展开查看详情
1 .Apache Spark⼊⻔
周康 · 阿⾥巴巴 / 分布式研发专家
�
2 . 01
Apache Spark基本概念
02
CONTENT
Spark SQL(DataFrames)
⽬录 >> 03
进阶指南
04
阿⾥云EMR
�
3 . 01
Apache Spark基本概念
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
4 .什么是Apache Spark?
Apache Spark是一个开源集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发
• 开源
• 高性能
• 易用,支持R、Scala、Java等
• 通用,支持批处理、流处理、机器学习等多种场景
�
5 . Apache Spark History
2.1版本发布
加⼊Apache 2016年2.1 release
2013年0.7版本加
⼊apache项⽬
1.0版本发布 3.0版本发布
2014年1.0 release 2020年3.0
release
2009诞⽣
�
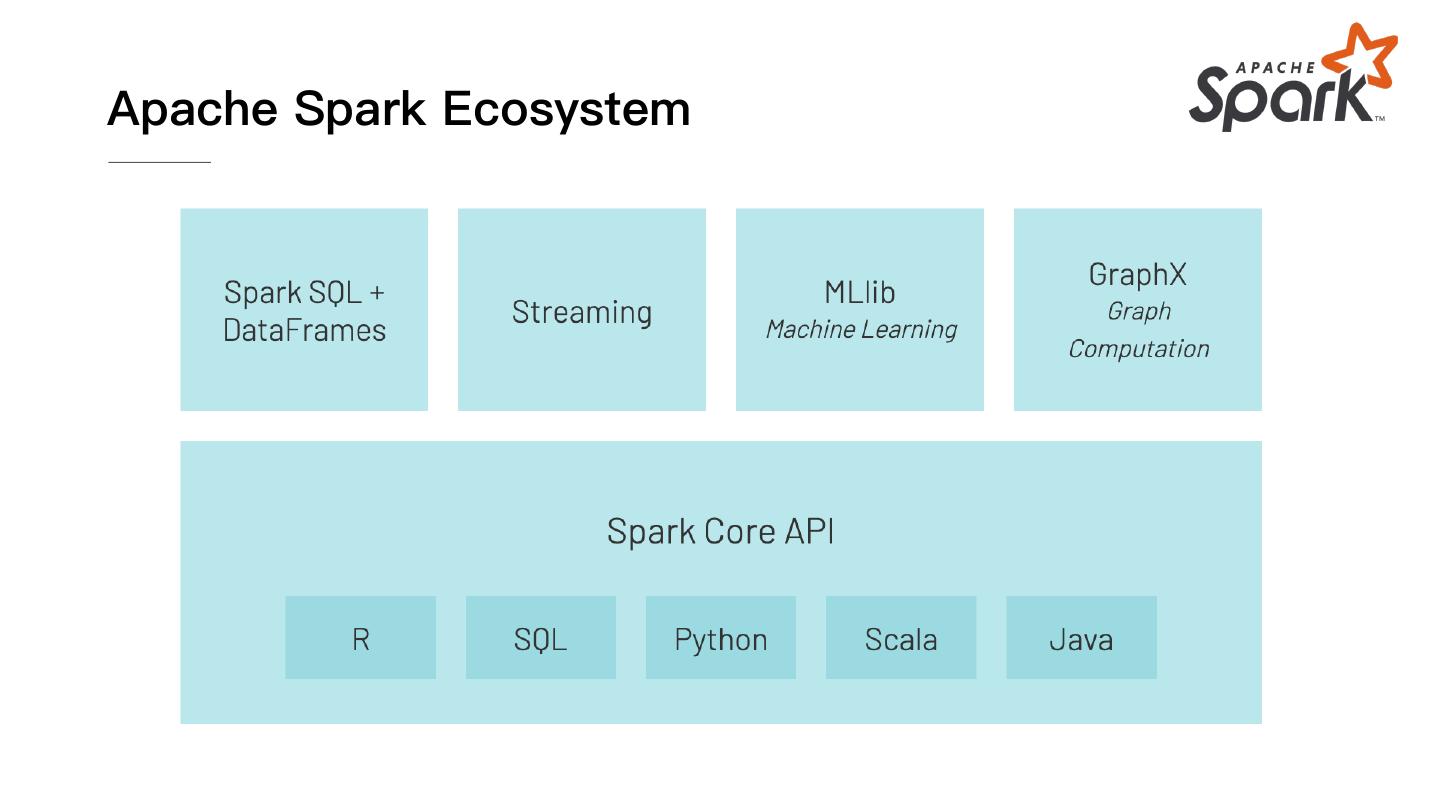
6 .Apache Spark Ecosystem
�
7 .举个栗⼦
基于阿里云EMR Spark 2.4.5
�
8 .Apache Spark架构
• Driver
• 运行作业主函数
• 创建 SparkContext
• Cluster Manager
• Standalone
• Mesos
• K8S
• Yarn
• Executor
• 执行task
• 处理rdd一个分区的数据
�
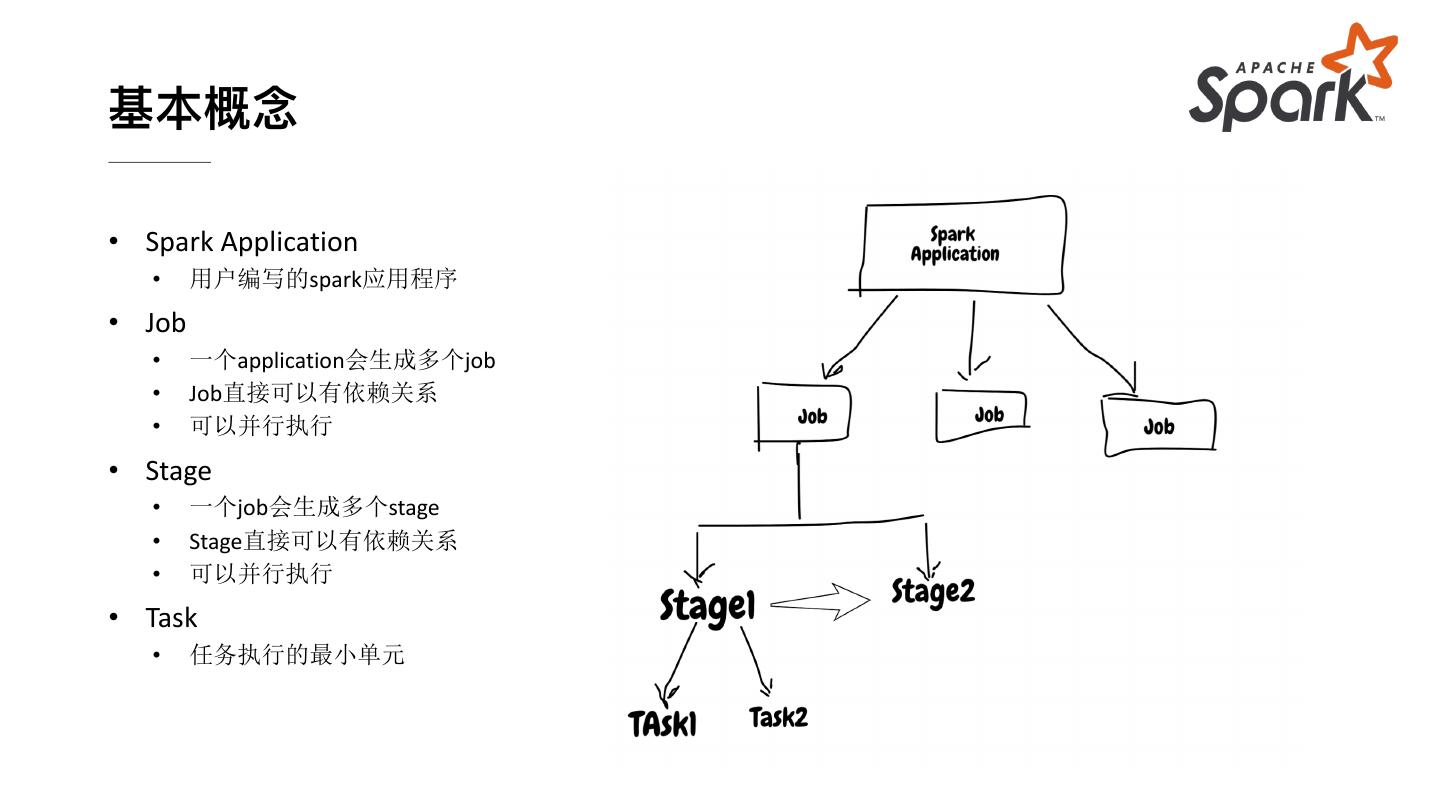
9 .基本概念
• Spark Application
• 用户编写的spark应用程序
• Job
• 一个application会生成多个job
• Job直接可以有依赖关系
• 可以并行执行
• Stage
• 一个job会生成多个stage
• Stage直接可以有依赖关系
• 可以并行执行
• Task
• 任务执行的最小单元
�
10 .SparkContext & SparkSession
• SparkContext是Spark2.0以前应用运 // 创建SparkContext
行入口 val conf = new SparkConf().setAppName(appName).setMaster(master)
• 一个进程只能有一个 new SparkContext(conf)
• Jar包管理
• DagScheduler // 创建SparkSession
• 事件处理 import org.apache.spark.sql.SparkSession
• 资源管理 val spark = SparkSession
• 运行时环境管理 .builder()
• Job Stage管理 .appName("Spark SQL basic example")
• … .config("spark.some.config.option", "some-value")
.getOrCreate()
• SparkSession是Spark 2.0之后应用运
行入口
• 支持spark context的特性
• 支持操作dataframe
• …
�
11 .History of Spark APIS
�
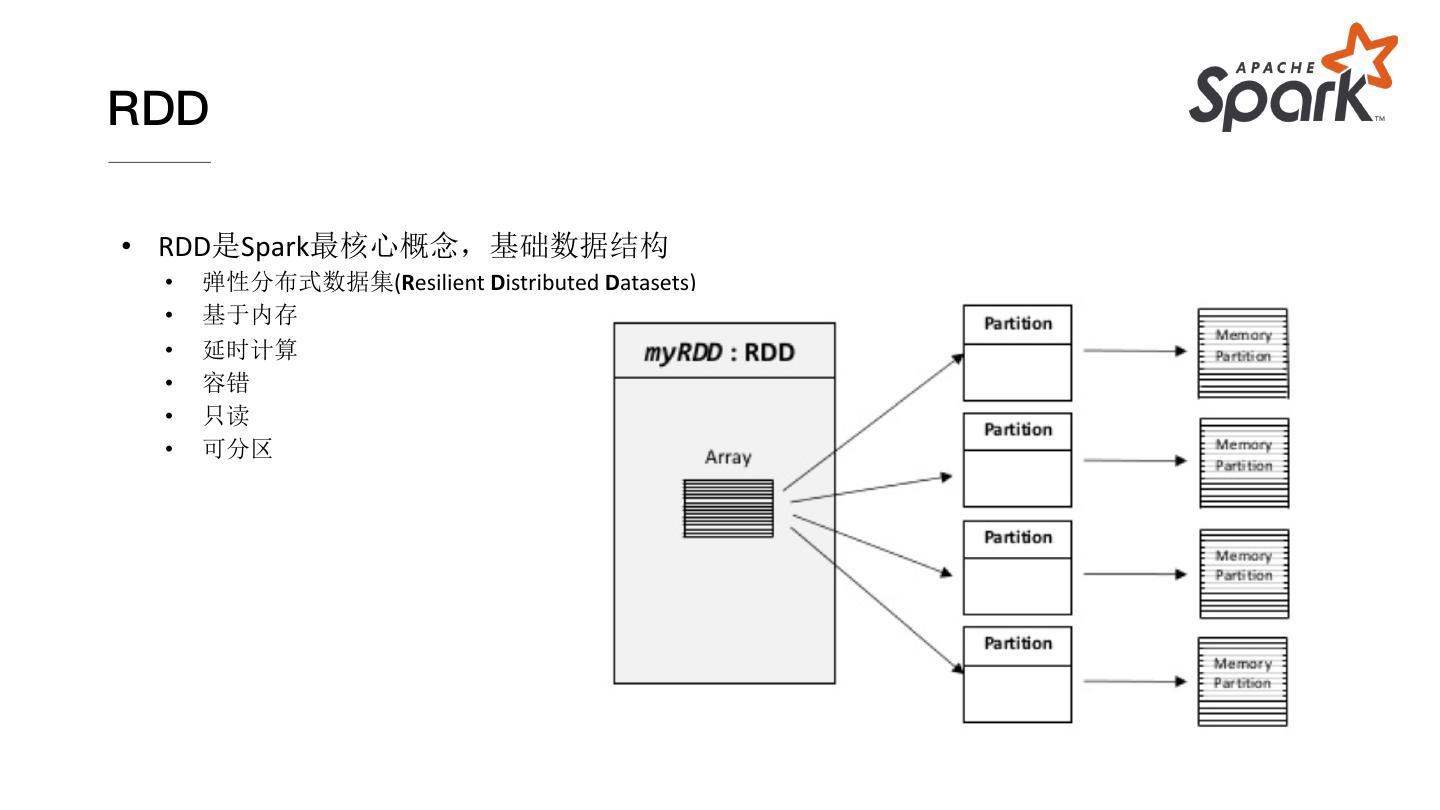
12 .RDD
• RDD是Spark最核心概念,基础数据结构
• 弹性分布式数据集(Resilient Distributed Datasets)
• 基于内存
• 延时计算
• 容错
• 只读
• 可分区
�
13 .RDD:Parallelized Collections
创建RDD方法1:在driver中对已有集合进行并行化
基于阿里云EMR Spark 2.4.5
�
14 .RDD:External Datasets
创建RDD方法2:基于外部数据源生成,比如本地文件、oss、HDFS等
基于阿里云EMR Spark 2.4.5
�
15 .RDD:Operations
RDD操作类型1:Transformations,基于已有的 RDD生成新的RDD
�
16 .RDD: Operations
RDD操作类型2:Actions,触发生成job开始运算
�
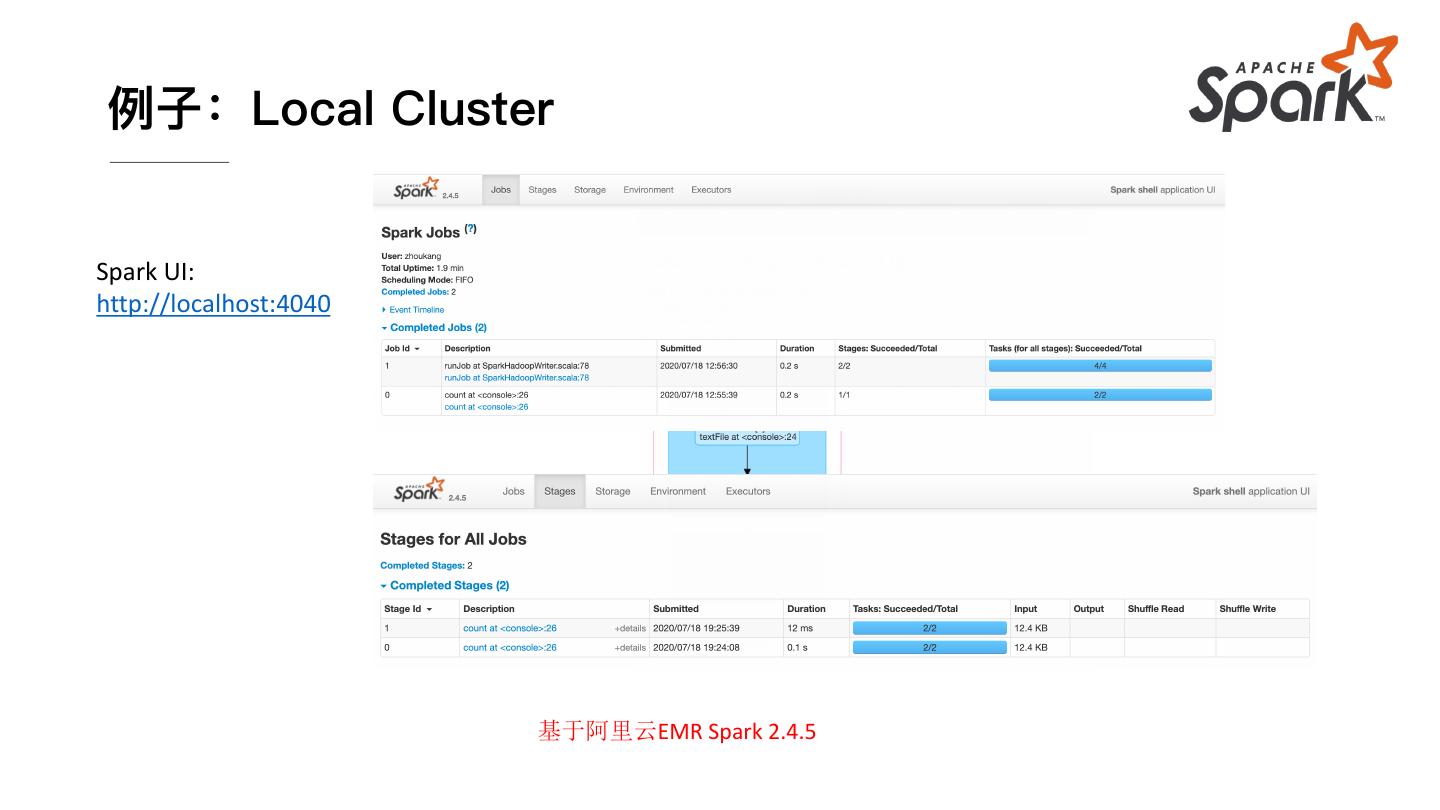
17 . 例⼦:Local Cluster
Spark UI:
http://localhost:4040
基于阿里云EMR Spark 2.4.5
�
18 .02
Spark SQL
DataFrames
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
19 .Spark SQL
Spark SQL 是一个用来处理结构化数据的Spark组件。 它提供了一个叫做DataFrames的可编程
抽象数据模型,并且可被视为一个分布式的SQL查询引擎
�
20 .DataFrames
• DataFrame是类似于关系表的分布式数据集
• 分布式
• 只读
• SQL查询
• Schema
• Catalyst优化
�
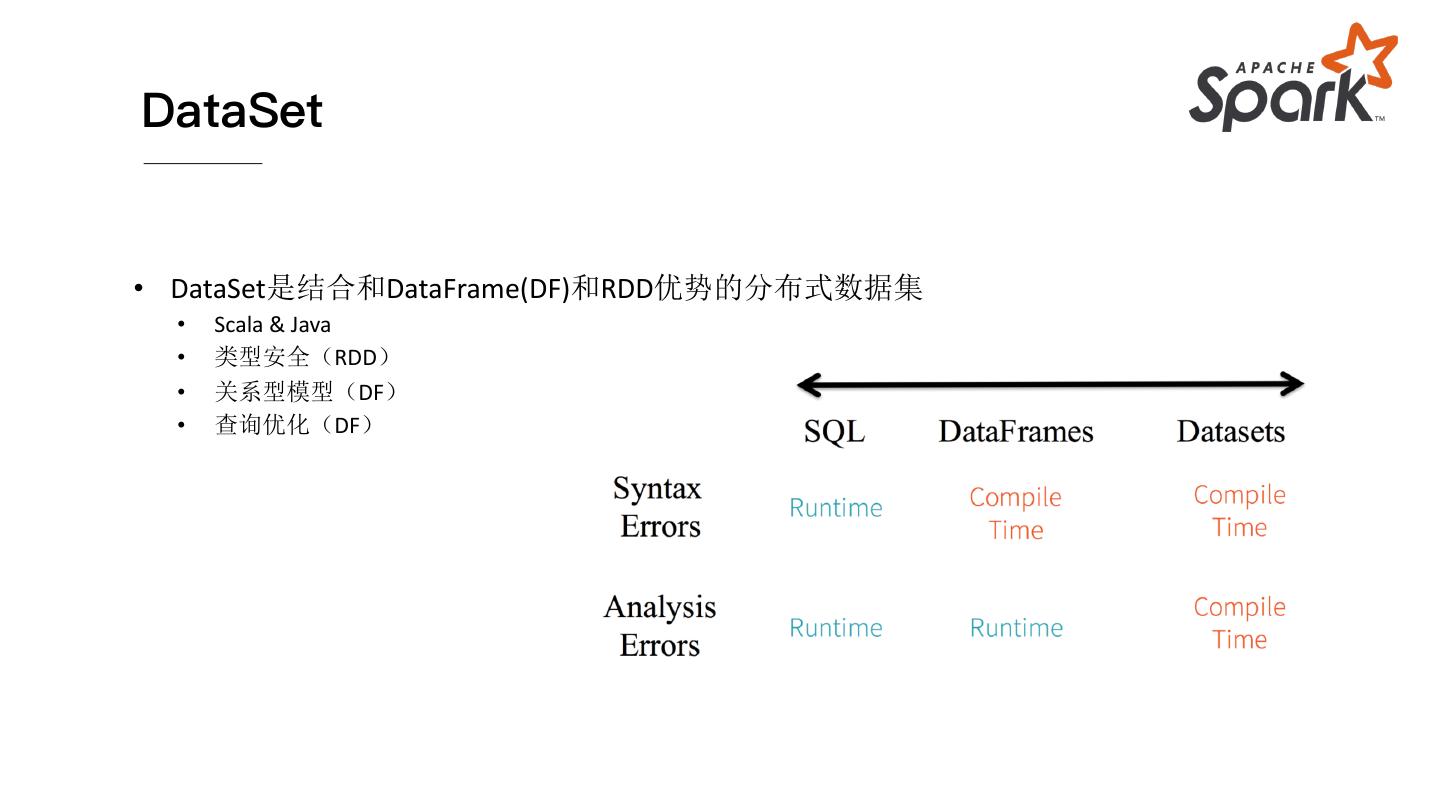
21 .DataSet
• DataSet是结合和DataFrame(DF)和RDD优势的分布式数据集
• Scala & Java
• 类型安全(RDD)
• 关系型模型(DF)
• 查询优化(DF)
�
22 .举个栗⼦
基于阿里云EMR Spark 2.4.5
�
23 .03
进阶指南
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
24 . Structured Streaming(SS)
• SS是构建与Spark SQL的流处理引擎
• 可扩展
• 容错
• 无限增长的表格
• SQL
• DataFrame
• …
�
25 . 例⼦:Structured Streaming
./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost 9999
基于阿里云EMR Spark 2.4.5
�
26 . ML Pipelines
• ML Pipelines是基于DF抽象的用于构建
机器学习工作流的API
• DataFrame(DF):表示数据集
• Transformer:DF转换的算法
• Estimator:作用于DF生成Transformer
• Pipeline:ML工作流
• Parameter:指定Transformer和Estimator的参
数
�
27 .04
阿⾥云EMR
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
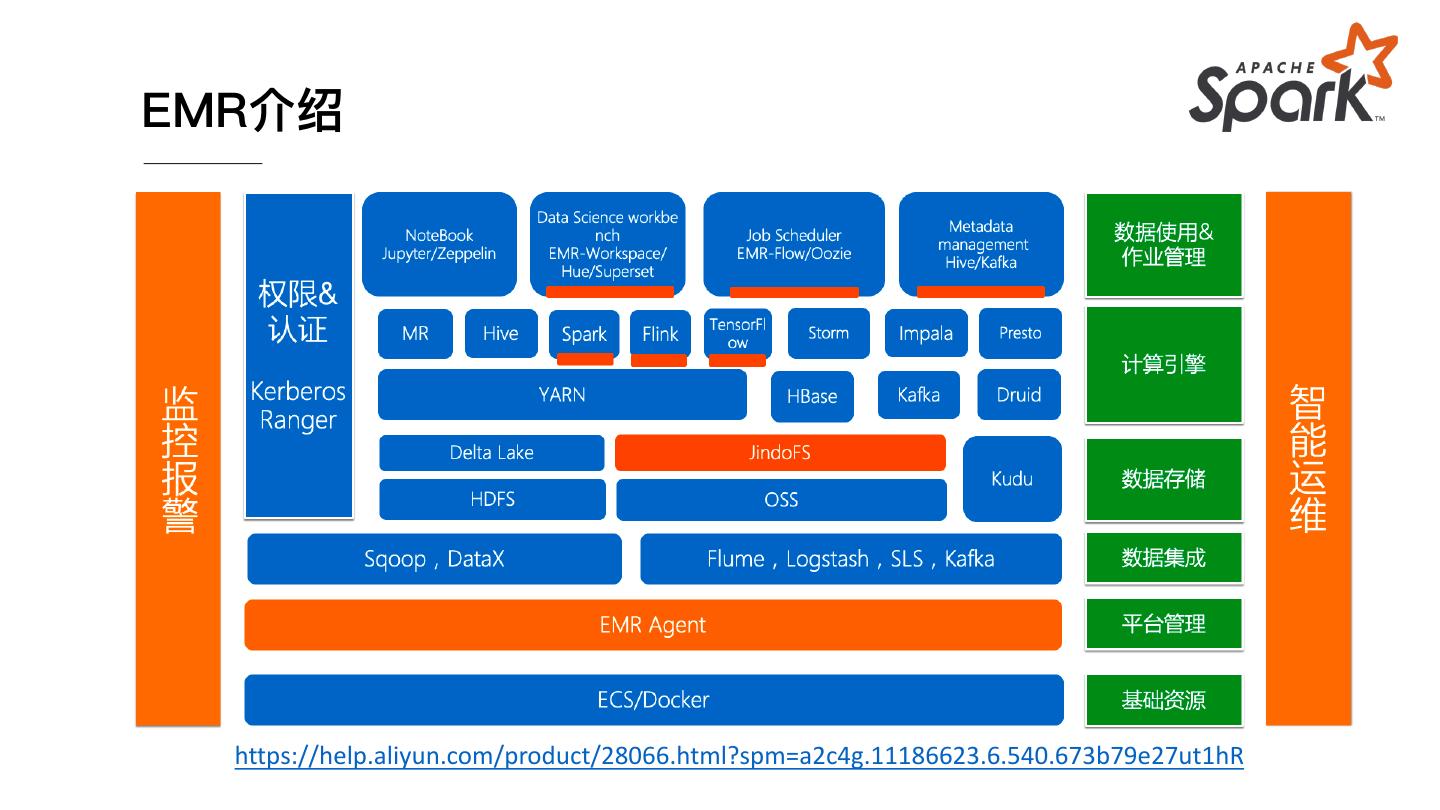
28 .EMR介绍
https://help.aliyun.com/product/28066.html?spm=a2c4g.11186623.6.540.673b79e27ut1hR
�
29 .关于我们
阿里云开源大数据团队专注于开源大数据生态,包括但不仅限于Hadoop/Spark/Hive/Kafka/Hbase
等开源系统的内核开发,我们在云平台上将开源大数据生态作为服务输出
欢迎加入我们!
zhoukang199191@gmail.com
yuzhou.zk@alibaba-inc.com
�