





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- <iframe src="https://www.slidestalk.com/ray/DatabricksSpark_80902?embed&video" frame border="0" width="640" height="360" scrolling="no" allowfullscreen="true">复制
- 微信扫一扫分享
Databricks数据洞察 - 企业级全托管Spark大数据分析平台介绍及案例分析
分享
点赞
0
收藏
0
下载 7
活动介绍
Databricks数据洞察是企业级全托管的Spark高性能大数据分析平台,来自Apache Spark创始公司Databricks。引擎采用Databricks Runtime,性能与社区版相比,最高可达50倍提升,高效而稳定。本次活动重点展开介绍该产品,并针对代表性案例进行分析。
讲师介绍
韩宗泽(棕泽),阿里云技术专家,计算平台事业部开放平台-生态企业团队负责人
展开查看详情
1 .Databricks数据洞察 - 企业级全托管Spark大数据 分析平台及案例分析 韩宗泽(棕泽) 阿里云技术专家,计算平台事业部开放平台-生态企业团队负责人 2021/05/19
2 .目录 Databricks数据洞察产品介绍 功能介绍 目录 典型场景 客户案例 产品Demo
3 .本次分享内容流程 Ø Databricks公司简介 Ø Databricks数据洞察(DDI)是什么 Ø Databricks on 阿里云 的合作方案 Ø 从功能上、引擎能力上、性能上、成本上不同维度的详细介绍 Ø 客户在大数据场景下遇到的常见的痛点问题,DDI如何针对性解决这些问题 Ø 实际生产场景的2个客户案例分析 Ø 产品演示Demo
4 .01. Databricks数据洞 察产品介绍 • Databricks公司简介 • 什么是阿里云Databricks数据洞察产品?
5 .Databricks 公司简介 • Apache Spark创始公司,也是Spark的最大代码贡献者,Spark技术生态背后的商业公司 o 成立于 2013年 o 由加州大学伯克利分校 AMPLab 的创始团队Apache Spark的创建者所成立 • 核心产品和技术,主导和推进Spark开源生态 o Apache Spark、Delta Lake、Koalas 、MLFlow、One Lakehouse Platform • 公司定位 o Databricks is the Data + AI company,为客户提供数据分析、数据工程、数据科学和人工智能方面的服务,一体化的 Lakehouse架构 o 开源版本 VS 商业版本:公司绝大部分技术研发资源投入在商业化产品 o 多云策略,与顶级云服务商合作,提供数据开发、数据分析、机器学习等产品,Data + AI一体化分析平台 • 市场地位 o 科技独角兽,行业标杆,领导Spark整体技术生态的走向及风向标 o 2021年最受期待的科技上市公司 o logo Databricks官网: https://databricks.com/
6 .Databricks 公司估值及融资历史 • 融资历史 • 2019年10月G轮,估值$6.2Billion (来源:https://databricks.com/company/newsroom/press-releases/databricks-growth-draws-400-million-series-f-investment-and-6-2-billion-valuation) • 2021年2月初F轮,估值$28Billion (来源https://databricks.com/company/newsroom/press-releases/databricks-raises-1-billion-series-g-investment-at-28-billion-valuation) • a)本轮融资,三大云服务商AWS、GCP、MS Azure以及Salesforce都进行了跟投——足以看到云厂商对Databricks的发展的重视 • b)上市预期:计划IPO在2021年——多方预测Databricks上市之时其估值可能达到350亿美元,甚至是高达500亿美元 G轮280亿美元 Databricks从成立之初的融资/估值历史 2019~2021最近一轮融资估值增长达5倍 进入爆发期 F轮62亿美元
7 .Databricks和阿里云联手打造的高品质Spark大数据分析平台 X Databricks数据洞察(DDI)为加速数据工程、数据分析、数据科学的跨领域创新而生 • Apache Spark背后的商业公司,Spark创始团队,美国科技独角兽 • 在全球拥有5,000多个客户和450多个合作伙伴,品牌认知强 • 2020年,在Gartner发布的数据科学和机器学习(DSML)平台魔力象限报告 中,位于领导者象限
8 .Databricks + 阿里云 = Databricks数据洞察 —— A Short Brief 产品简称(DDI):Databricks数据洞察(Databricks DataInsight) =》 DDI 产品核心 Ø 基于商业版 Spark 的全托管大数据分析 &AI 平台 Ø 内置商业版Spark引擎Databricks Runtime,在计算层面提供高效、稳定的保障 Ø 与阿里云产品集成互通,提供数据安全、动态扩容、监控告警等企业级特性 Databricks Runtime引擎 ( 兼 Databricks Delta Lake & 容Apache Spark ) Delta Engine (超高性能) 产品引擎与服务 Ø 100% 兼容开源 Spark,经阿里云与Databricks联合研发性能优化 Ø 提供商业化SLA保障与7*24小时Databricks专家支持服务
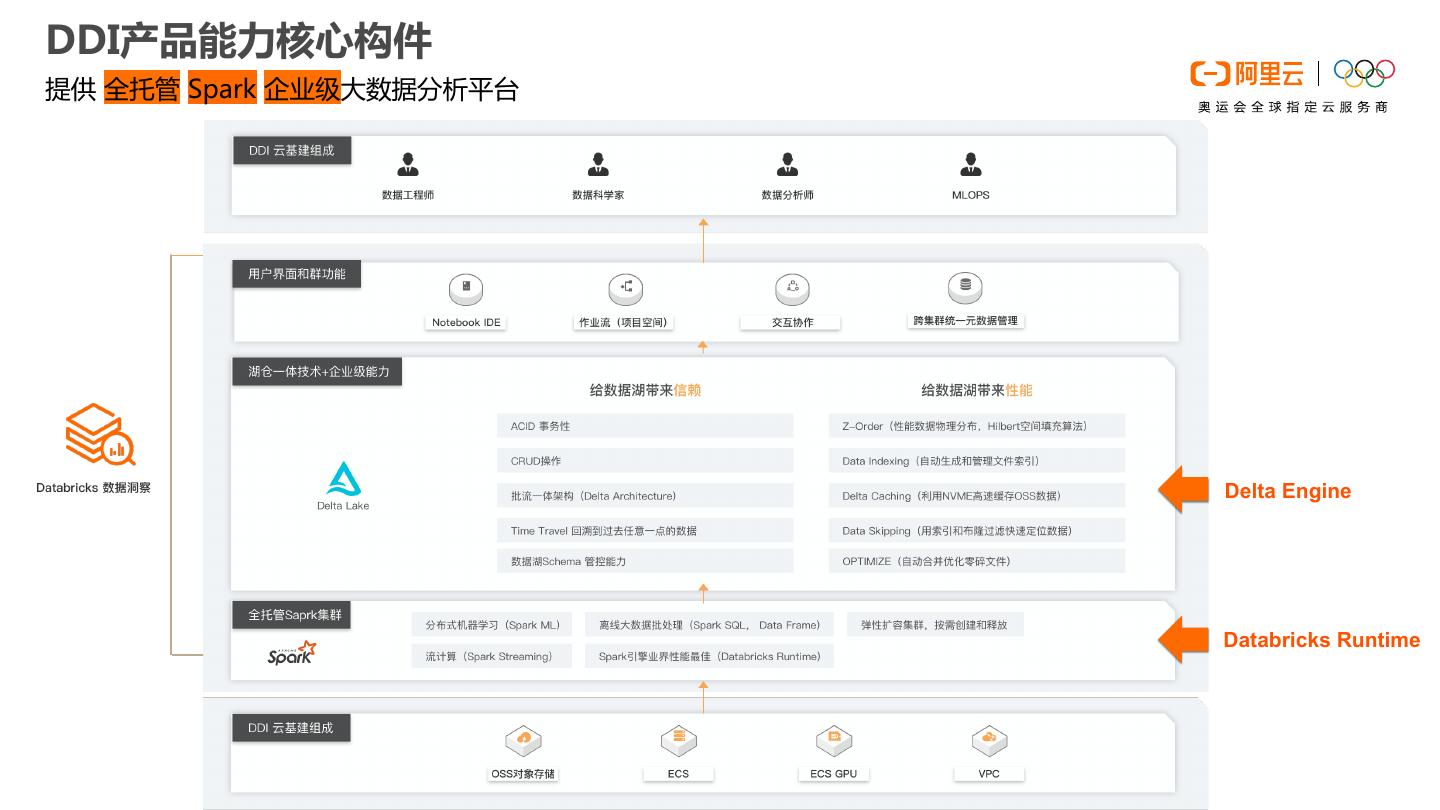
9 .DDI产品能力核心构件 提供 全托管 Spark 企业级大数据分析平台 Delta Engine Databricks Runtime
10 .产品关键信息与优势
11 .02. DDI产品功能介绍 • 整体架构 • 引擎能力 • 性能 • 功能 • 成本
12 . 阿里云Databricks数据洞察 (DDI) 架构 Databricks驱动的超高性能阿里云数据平台 Super Charged AliCloud Data Platform powered by Databricks 全托管 高性能 架构先进 企业级 Spark 交互协作 全托管Spark平台 集群 交互式 工作流 元数据 弹性 原生UI Apache 管理 分析 调度DAG 管理 伸缩 监控 Spark兼容 流式数据 商业洞察分析 Business Insights Databricks Delta Lake & Delta Engine (超高性能) 结构化数据 Databricks Runtime引擎 ( 兼容Apache Spark ) 机器学习训练 JindoFS VPC Machine Learning ECS Results OSS RDS/ES/Kafka.. 半结构化数据
13 .引擎:企业级性能优化,提升计算引擎效率和数据读写效率 企业级高性能、稳定性、可靠性 DBR + Delta Engine 性能Performance • 100% 兼容 Apache Spark • 自动解决小文件问题 • 自动开启Spark Job DAG过程的性能优化 • ACID 事务性,并发读/写/更新/删除 • 数据可流可批 • Z-Order优化,使读取数据量减少95%,20x性能提升 • 常用表和查询缓存,30x性能提升 • PB级可扩展性 数据来源,基于TPC-DS的测试,客户可复现:https://help.aliyun.com/document_detail/178243.html
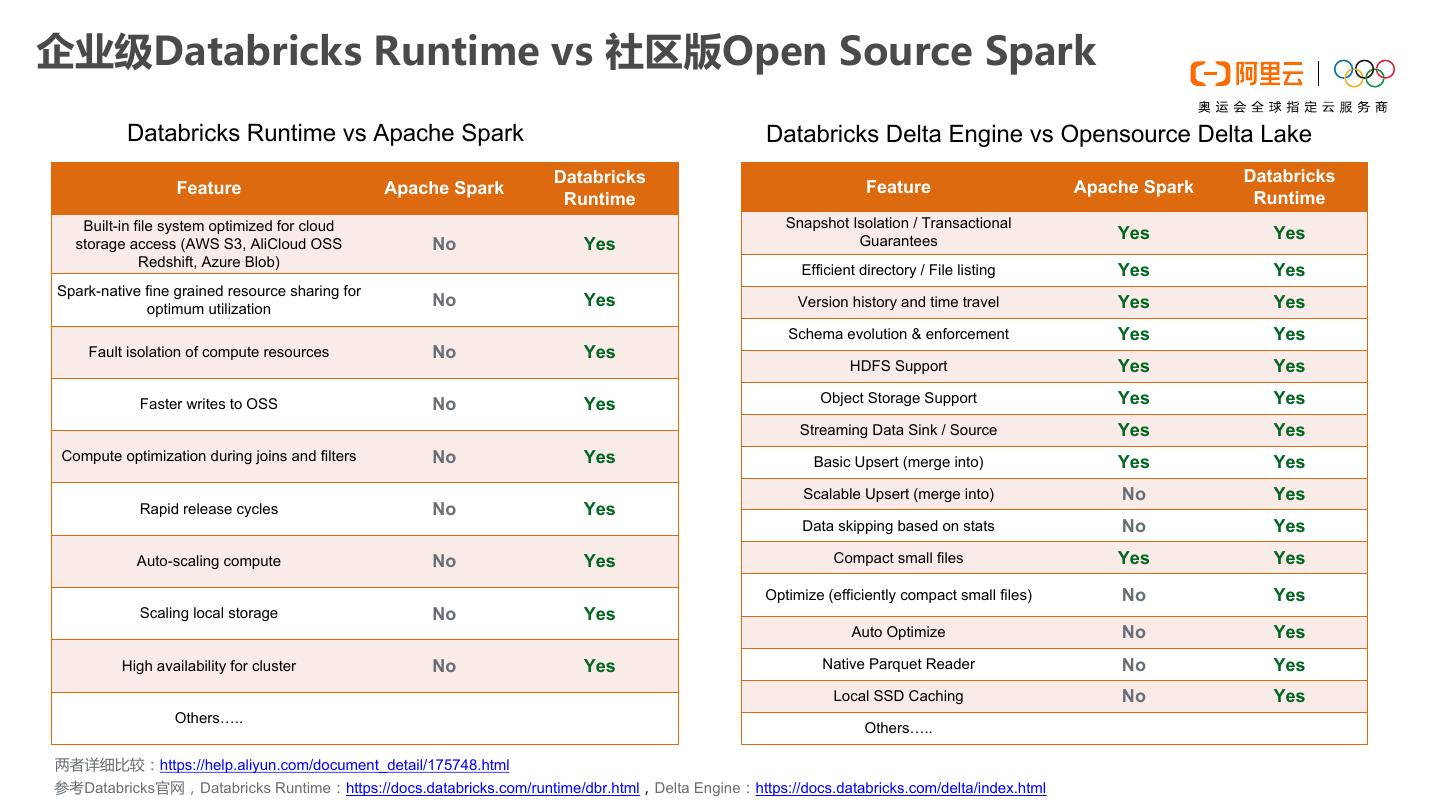
14 .企业级Databricks Runtime vs 社区版Open Source Spark Databricks Runtime vs Apache Spark Databricks Delta Engine vs Opensource Delta Lake Databricks Databricks Feature Apache Spark Feature Apache Spark Runtime Runtime Built-in file system optimized for cloud Snapshot Isolation / Transactional Guarantees Yes Yes storage access (AWS S3, AliCloud OSS No Yes Redshift, Azure Blob) Efficient directory / File listing Yes Yes Spark-native fine grained resource sharing for optimum utilization No Yes Version history and time travel Yes Yes Schema evolution & enforcement Yes Yes Fault isolation of compute resources No Yes HDFS Support Yes Yes Faster writes to OSS No Yes Object Storage Support Yes Yes Streaming Data Sink / Source Yes Yes Compute optimization during joins and filters No Yes Basic Upsert (merge into) Yes Yes Scalable Upsert (merge into) No Yes Rapid release cycles No Yes Data skipping based on stats No Yes Auto-scaling compute No Yes Compact small files Yes Yes Optimize (efficiently compact small files) No Yes Scaling local storage No Yes Auto Optimize No Yes High availability for cluster No Yes Native Parquet Reader No Yes Local SSD Caching No Yes Others….. Others….. 两者详细比较:https://help.aliyun.com/document_detail/175748.html 参考Databricks官网,Databricks Runtime:https://docs.databricks.com/runtime/dbr.html,Delta Engine:https://docs.databricks.com/delta/index.html
15 .基于计算存储分离的架构,HDFS vs OSS成本的对比 存算一体 =》 计算存储分离 HDFS数据存储成本 HDFS/OSS数据存储成本对比 平均存储成本 HDFS存储 OSS标准 OSS低频 OSS归档 OSS冷归档 按月标价(元) (元/GB/月) ECS d1ne.14xlarge 数据存储成本 13475 0.16 (元/GB/月) 0.16 0.12 0.08 0.033 0.015 (56C/224G/154TB) HDFS3副本 80%利用率计算,ECS价格参考: OSS归档的数据存储成本只有HDFS数据存储成本的20%,OSS冷归档不到HDFS存储的10% https://www.aliyun.com/price/product#/ecs/detail
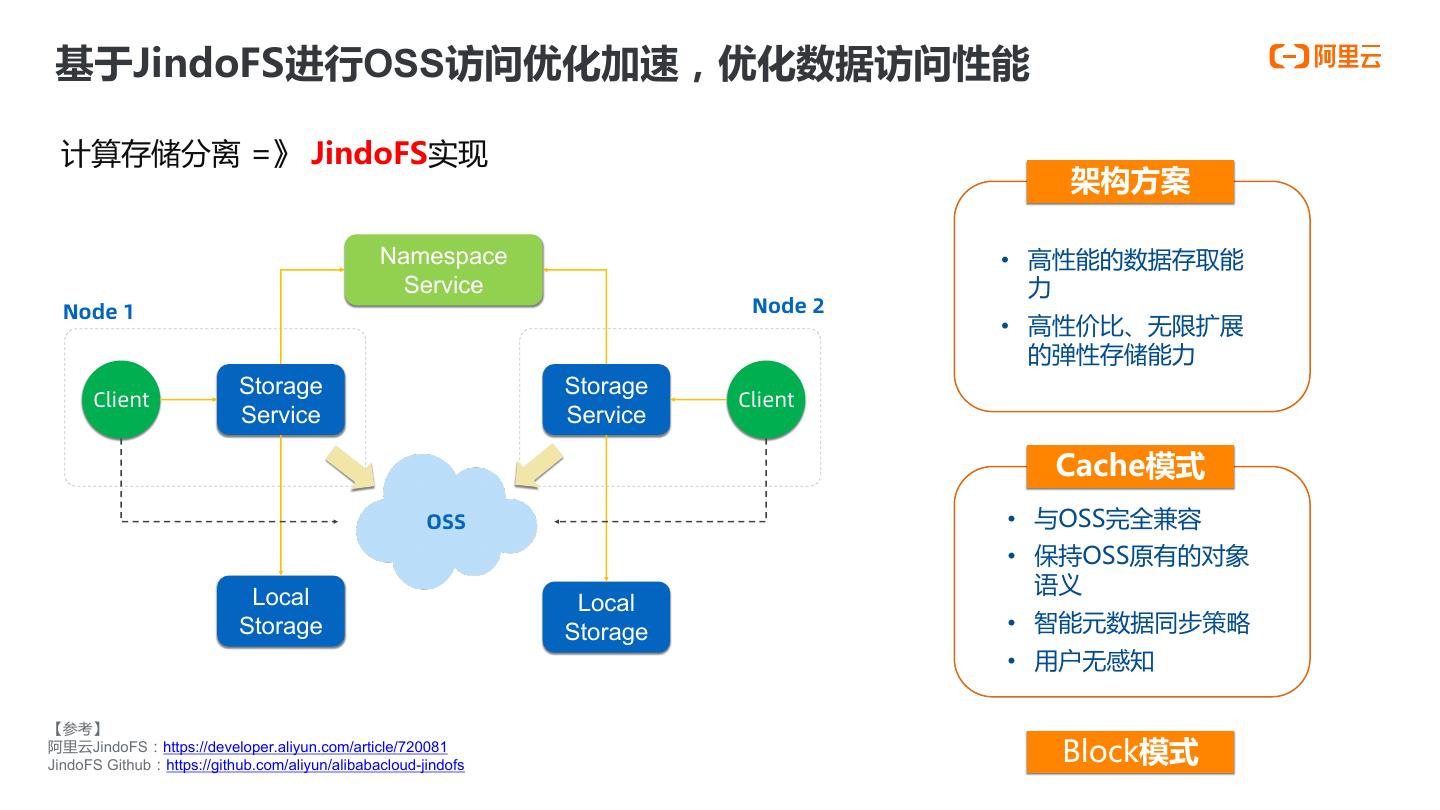
16 . 基于JindoFS进行OSS访问优化加速,优化数据访问性能 计算存储分离 =》 JindoFS实现 架构方案 Namespace • 高性能的数据存取能 Service 力 Node 1 Node 2 • 高性价比、无限扩展 的弹性存储能力 Storage Storage Client Client Service Service Cache模式 OSS • 与OSS完全兼容 • 保持OSS原有的对象 Local 语义 Local Storage Storage • 智能元数据同步策略 • 用户无感知 【参考】 阿里云JindoFS:https://developer.aliyun.com/article/720081 JindoFS Github:https://github.com/aliyun/alibabacloud-jindofs Block模式
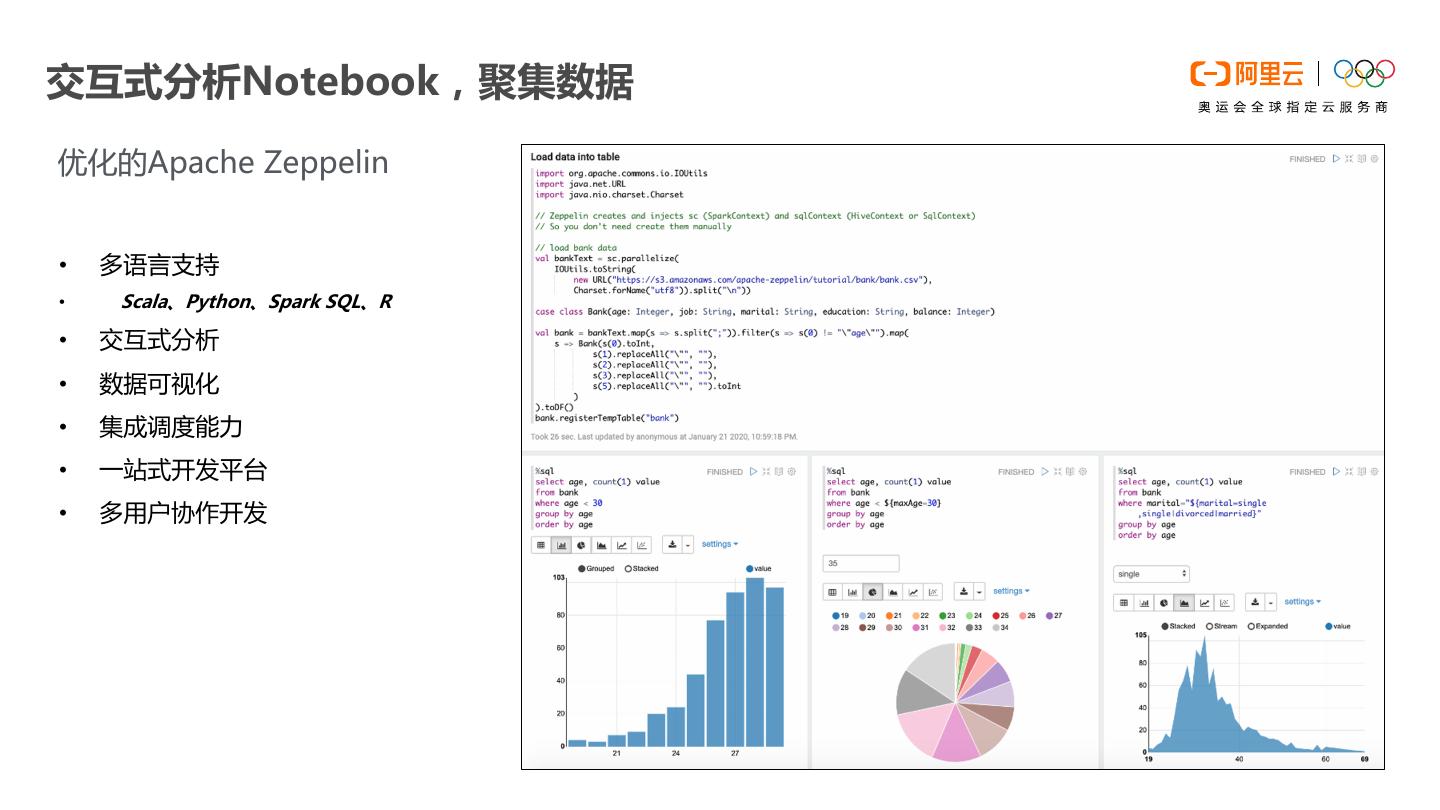
17 .交互式分析Notebook,聚集数据 优化的Apache Zeppelin • 多语言支持 • Scala、Python、Spark SQL、R • 交互式分析 • 数据可视化 • 集成调度能力 • 一站式开发平台 • 多用户协作开发
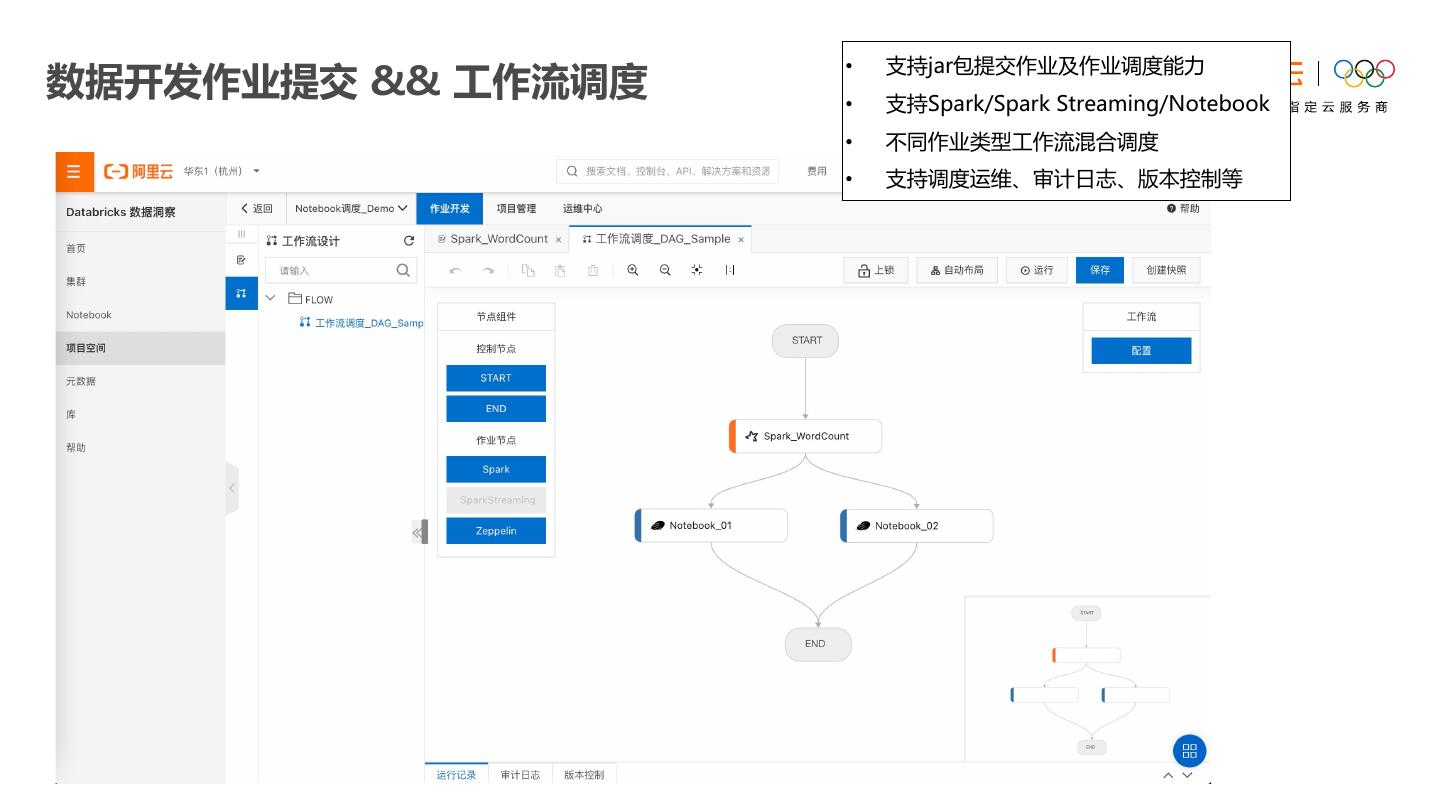
18 . • 支持jar包提交作业及作业调度能力 数据开发作业提交 && 工作流调度 • 支持Spark/Spark Streaming/Notebook • 不同作业类型工作流混合调度 • 支持调度运维、审计日志、版本控制等
19 .丰富的数据源支持 支持常见数据文件格式 CSV JSON Parquet ORC TXT文本文件 支持各种数据源(内置Connector) OSS HDFS MySQL(RDS) Redis ElasticSearch MongoDB JindoFS Block MaxCompute
20 .元数据管理 三种元数据选择的方式 Data Lake Formation 用户自建RDS MySQL 统一元数据 • 阿里云托管版本的元数据服务DLF • 独立的元数据服务性能佳 • DDI产品自带统一元数据服务 • 独立的元数据服务性能佳 • 客户来运维 • 使用简单 • 免运维 • 多系统共享元数据 • 多系统无法共享元数据信息 • 库、表级别的权限隔离 • 适合生产环境 • 适合测试环境 • 多系统共享元数据信息 • 适合生产环境
21 .03. 典型场景 • 客户存在的痛点问题及DDI如何解决 • Lambda架构到批流一体架构 • Lakehouse架构的演进 • DDI在阿里云中产品的组合
22 .开源大数据平台客户普遍存在的痛点问题 1、运维调优投入高 2. 数据源演进难,系统架构复杂 3. 硬件及资源耗费成本高 • 数据分析人员兼任运维,维护平台投入时 • 数据源增加时难保持数据事务一致性 • 计算存储不分离,使用昂贵的冷数据 间长,人员成本高 • 已有数据模型schema变化难以 演进 存储 • 想对作业调优,但是内核同学较少,技术 • 同时处理流式数据和批数据两套处理 • 如自建场景扩容不灵活,平台难以满 调优门槛高 逻辑 足业务的发展 全托管 存算分离 高性能引擎 企业版Delta Engine OSS
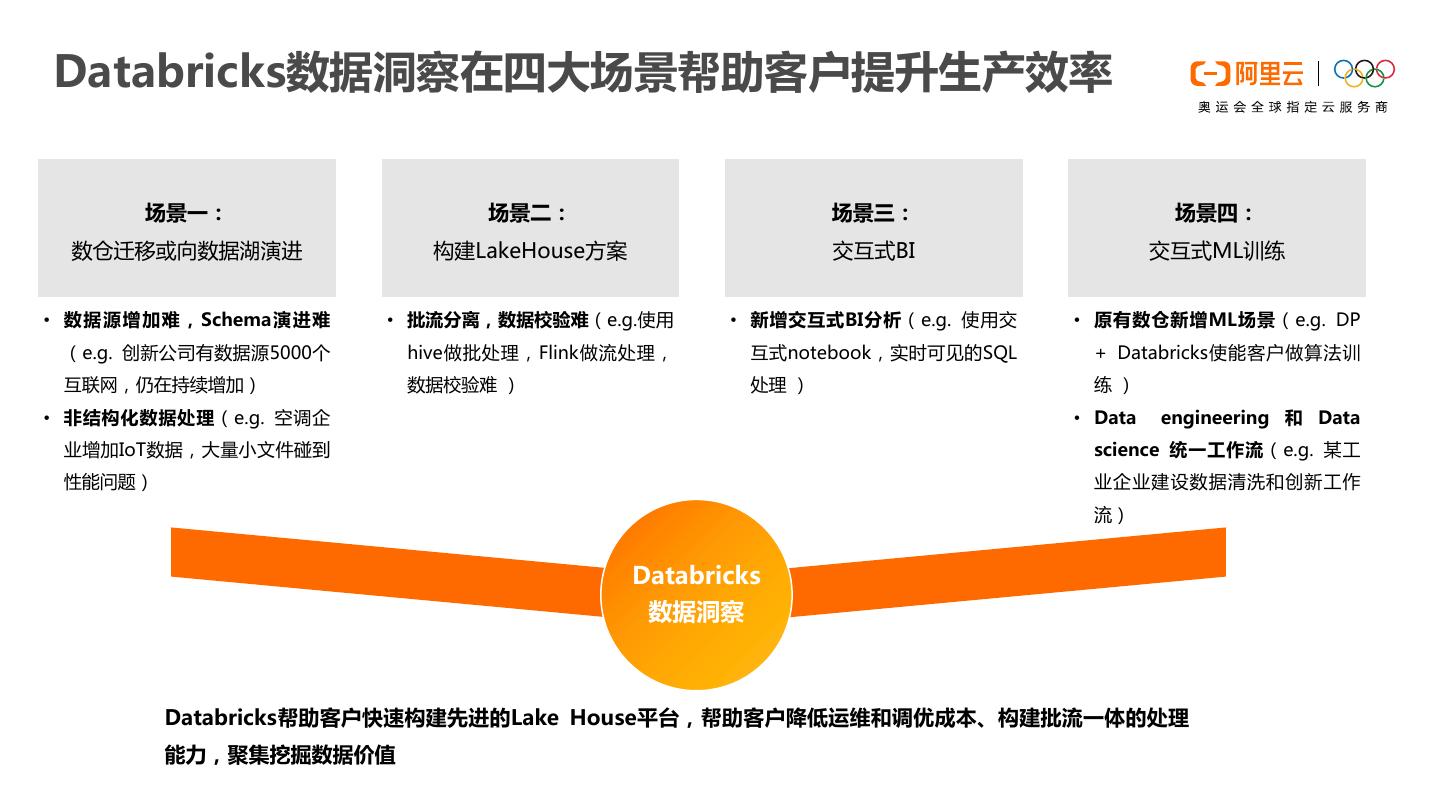
23 .Databricks数据洞察在四大场景帮助客户提升生产效率 场景一: 场景二: 场景三: 场景四: 数仓迁移或向数据湖演进 构建LakeHouse方案 交互式BI 交互式ML训练 • 数据源增加难,Schema演进难 • 批流分离,数据校验难(e.g.使用 • 新增交互式BI分析(e.g. 使用交 • 原有数仓新增ML场景(e.g. DP (e.g. 创新公司有数据源5000个 hive做批处理,Flink做流处理, 互式notebook,实时可见的SQL + Databricks使能客户做算法训 互联网,仍在持续增加) 数据校验难 ) 处理 ) 练) • 非结构化数据处理(e.g. 空调企 • Data engineering 和 Data 业增加IoT数据,大量小文件碰到 science 统一工作流(e.g. 某工 性能问题) 业企业建设数据清洗和创新工作 流) Databricks 数据洞察 Databricks帮助客户快速构建先进的Lake House平台,帮助客户降低运维和调优成本、构建批流一体的处理 能力,聚集挖掘数据价值
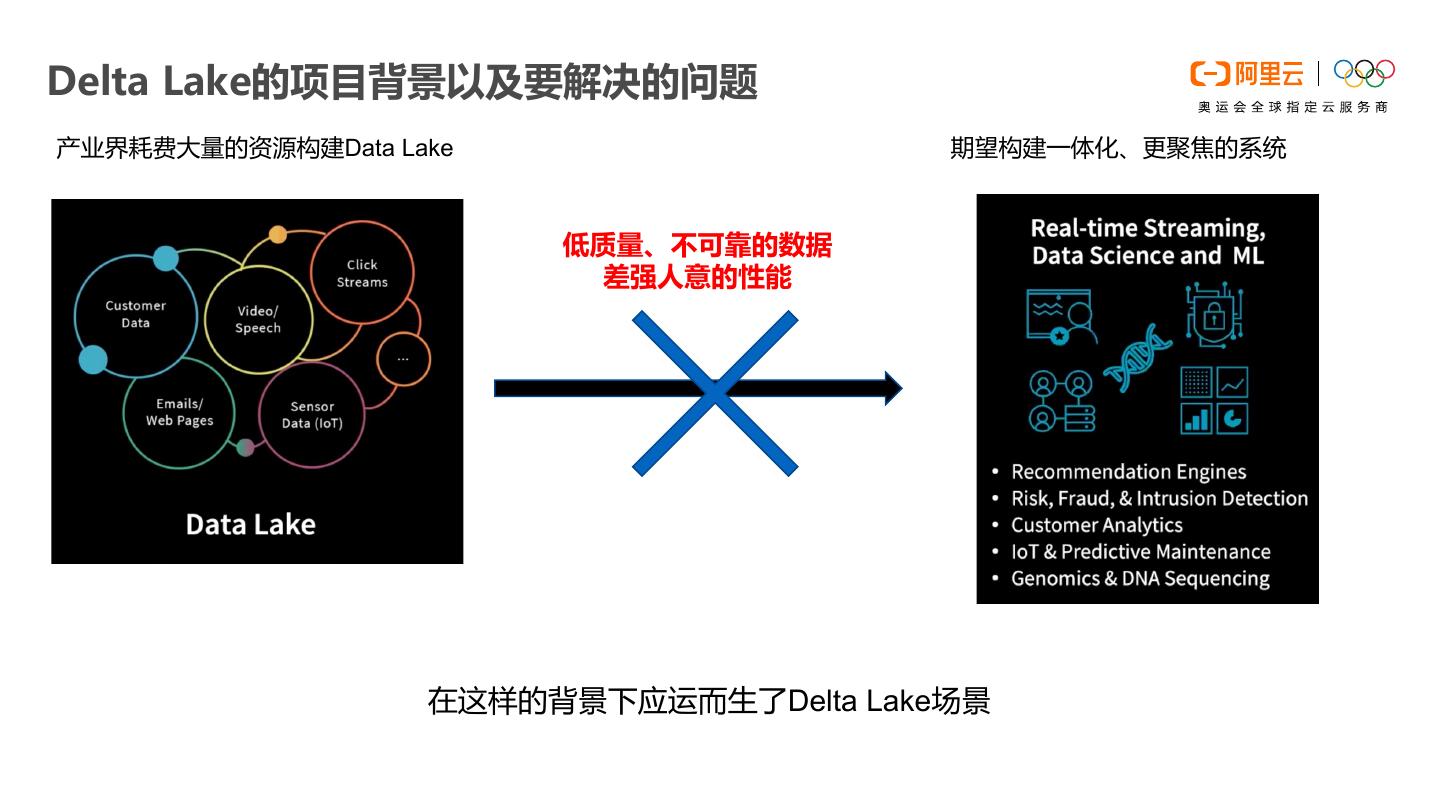
24 .Delta Lake的项目背景以及要解决的问题 产业界耗费大量的资源构建Data Lake 期望构建一体化、更聚焦的系统 低质量、不可靠的数据 差强人意的性能 在这样的背景下应运而生了Delta Lake场景
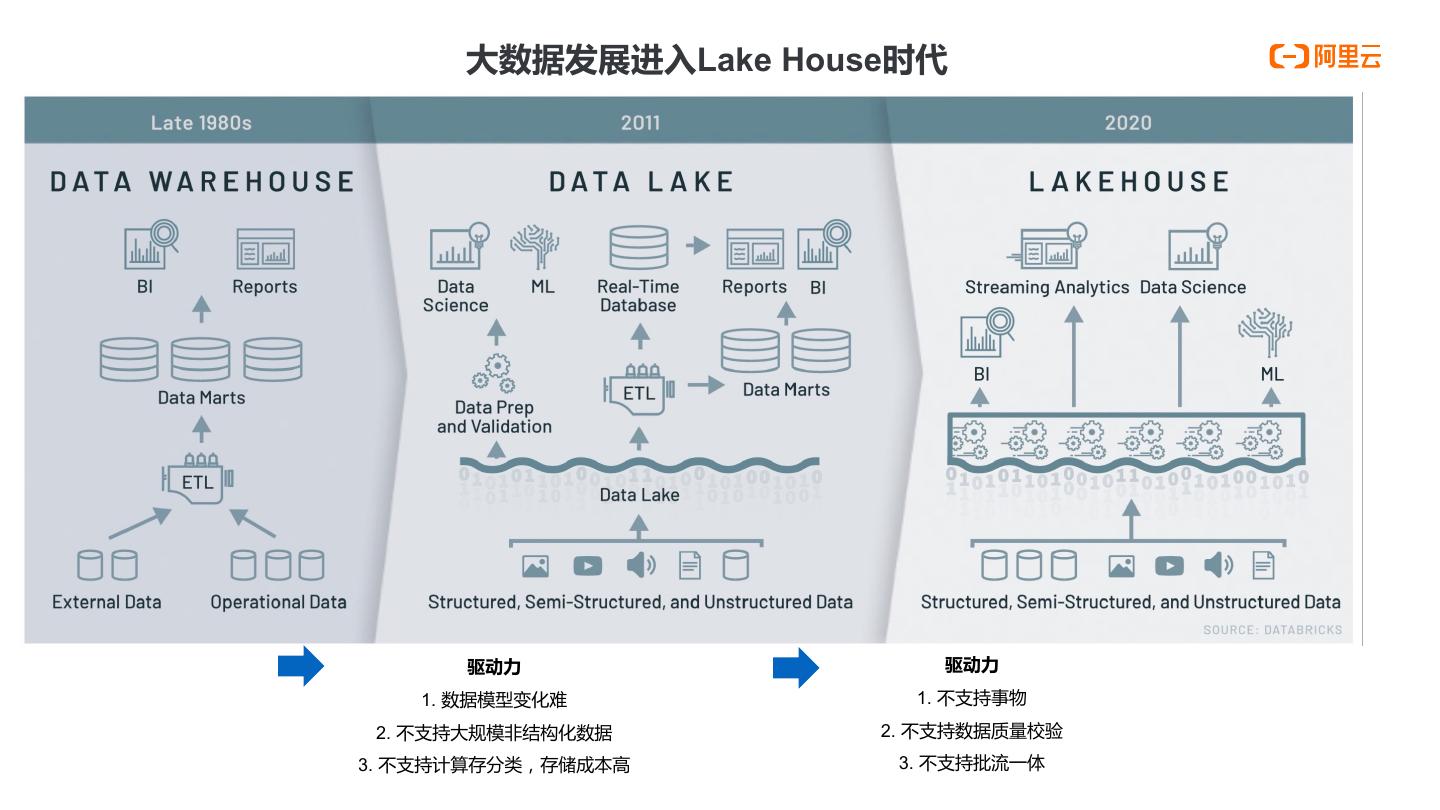
25 . 大数据发展进入Lake House时代 驱动力 驱动力 1. 数据模型变化难 1. 不支持事物 2. 不支持大规模非结构化数据 2. 不支持数据质量校验 3. 不支持计算存分类,存储成本高 3. 不支持批流一体
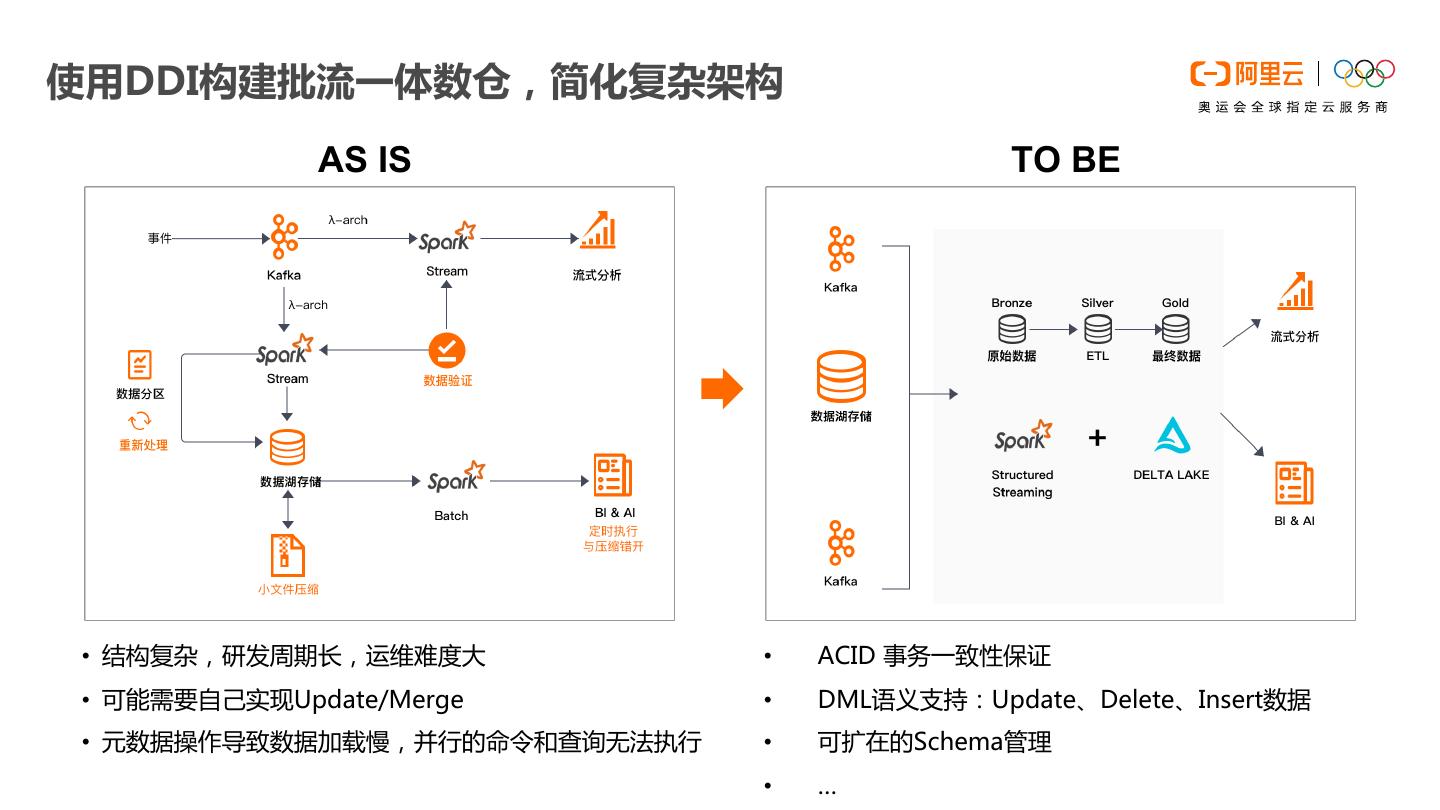
26 .使用DDI构建批流一体数仓,简化复杂架构 AS IS TO BE • 结构复杂,研发周期长,运维难度大 • ACID 事务一致性保证 • 可能需要自己实现Update/Merge • DML语义支持:Update、Delete、Insert数据 • 元数据操作导致数据加载慢,并行的命令和查询无法执行 • 可扩在的Schema管理 • …
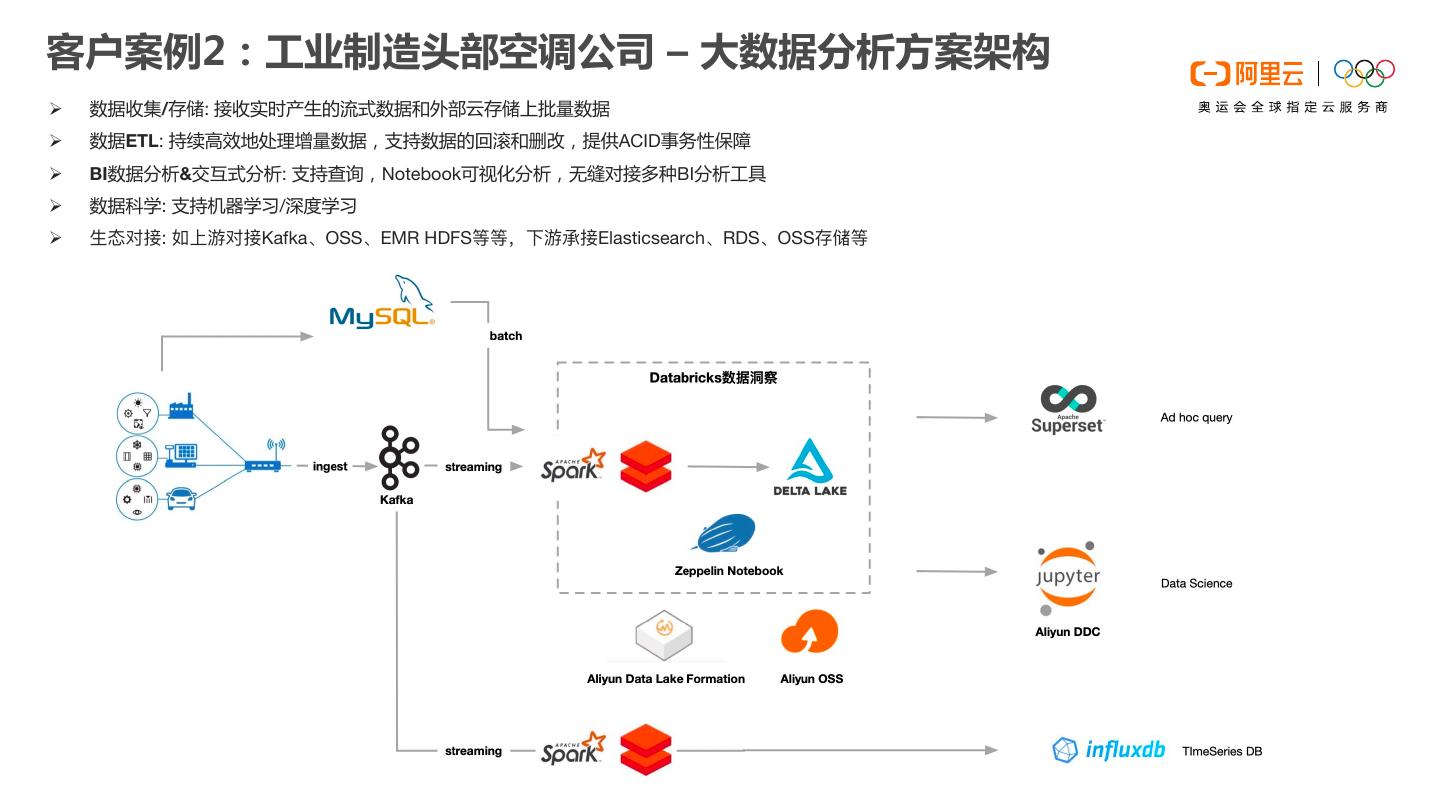
27 .DDI在阿里云产品中的组合 Databricks数据洞察典型架构 DDI与阿里云产品深度集成(典型场景) 数据获取 • 接收实时产生的流式数据和外部云存储上批量数 据。 数据ETL • 持续高效地处理增量数据,支持数据的回滚和删 改,提供ACID事务性保障。 BI报表数据分析 && 交互式分析 • 支持Ad hoc查询,Notebook可视化分析,无缝对 接多种BI分析工具。 AI数据探索 • 支持机器学习,Mllib等Spark生态AI场景。 上下游网络打通 • 如上游对接Kafka、OSS、EMR HDFS等等,下 游承接Elasticsearch、RDS、OSS存储等
28 .04. 客户案例介绍 1. 基智科技(STEPONE)自建上云案例 2. 工业制造头部公司数据分析案例
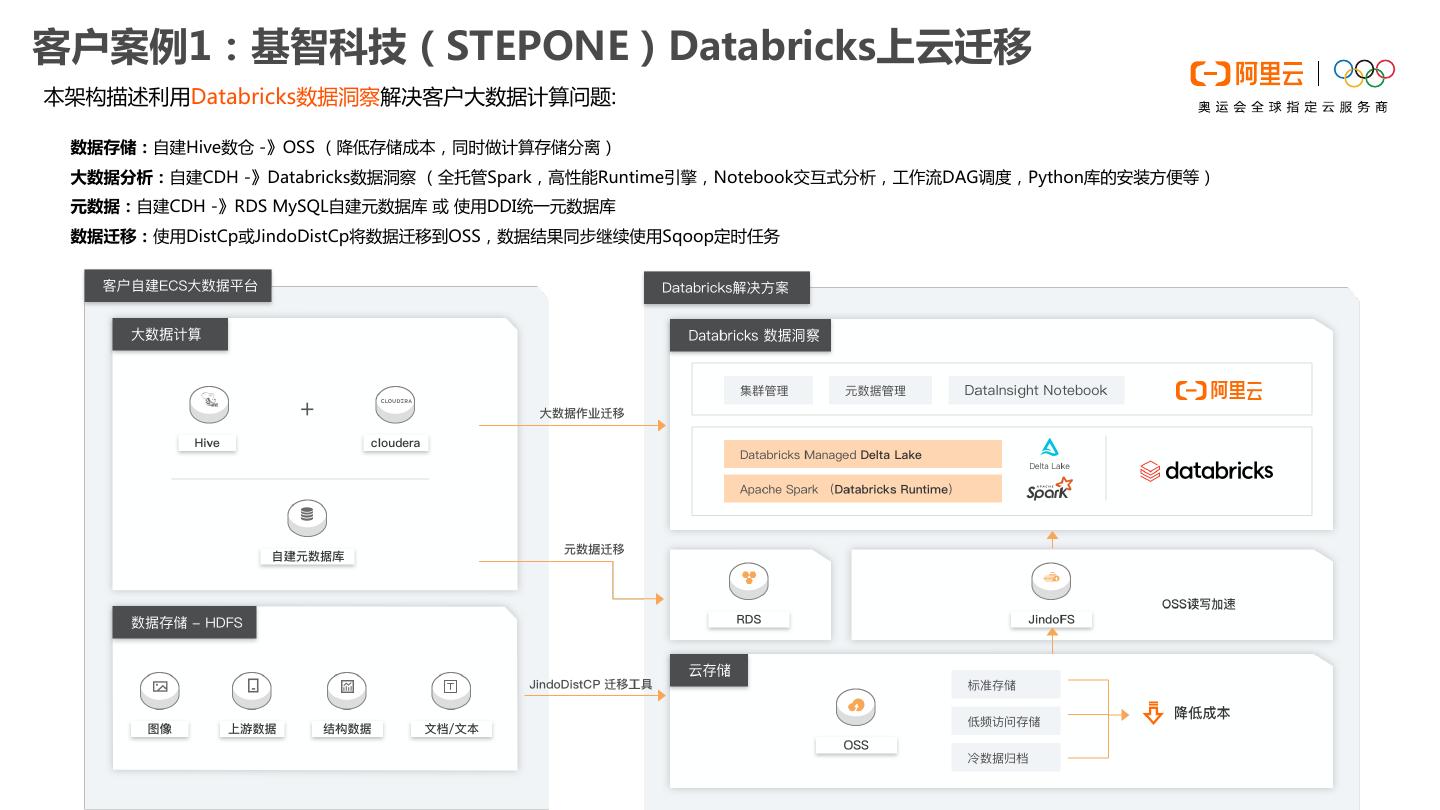
29 .客户案例1:基智科技(STEPONE)Databricks上云迁移 本架构描述利用Databricks数据洞察解决客户大数据计算问题: Ø 数据存储:自建Hive数仓 -》OSS (降低存储成本,同时做计算存储分离) Ø 大数据分析:自建CDH -》Databricks数据洞察 (全托管Spark,高性能Runtime引擎,Notebook交互式分析,工作流DAG调度,Python库的安装方便等) Ø 元数据:自建CDH -》RDS MySQL自建元数据库 或 使用DDI统一元数据库 Ø 数据迁移:使用DistCp或JindoDistCp将数据迁移到OSS,数据结果同步继续使用Sqoop定时任务
3秒后跳转登录页面
去登陆

