











- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
E-MapReduce产品探秘,扩展开源生态云上的能力
分享
点赞
0
收藏
0
7月10日【E-MapReduce产品探秘,扩展开源生态云上的能力】
讲师:夏立,花名雷飙 ,阿里巴巴计算平台EMR高级产品专家,2014年开始接触大数据,历经阿里内部的大数据发展,目前在阿里云上负责开源的大数据平台EMR产品,构建云上的开源生态。
直播介绍:E-MapReduce的产品能力介绍,通过EMR来构建高效的云上大数据平台,优化云上的使用成本,更快的计算效率。
阿里巴巴开源大数据EMR技术团队成立Apache Spark中国技术社区,定期打造国内Spark线上线下交流活动。请持续关注。
钉钉群号:21784001
团队群号:HPRX8117
微信公众号:Apache Spark技术交流社区
展开查看详情
1 .E-MapReduce(EMR)产品系列讲座 2 云智能-EMR 雷飙
2 . 产品功能进阶 监控优势 CONTENT 产品实践
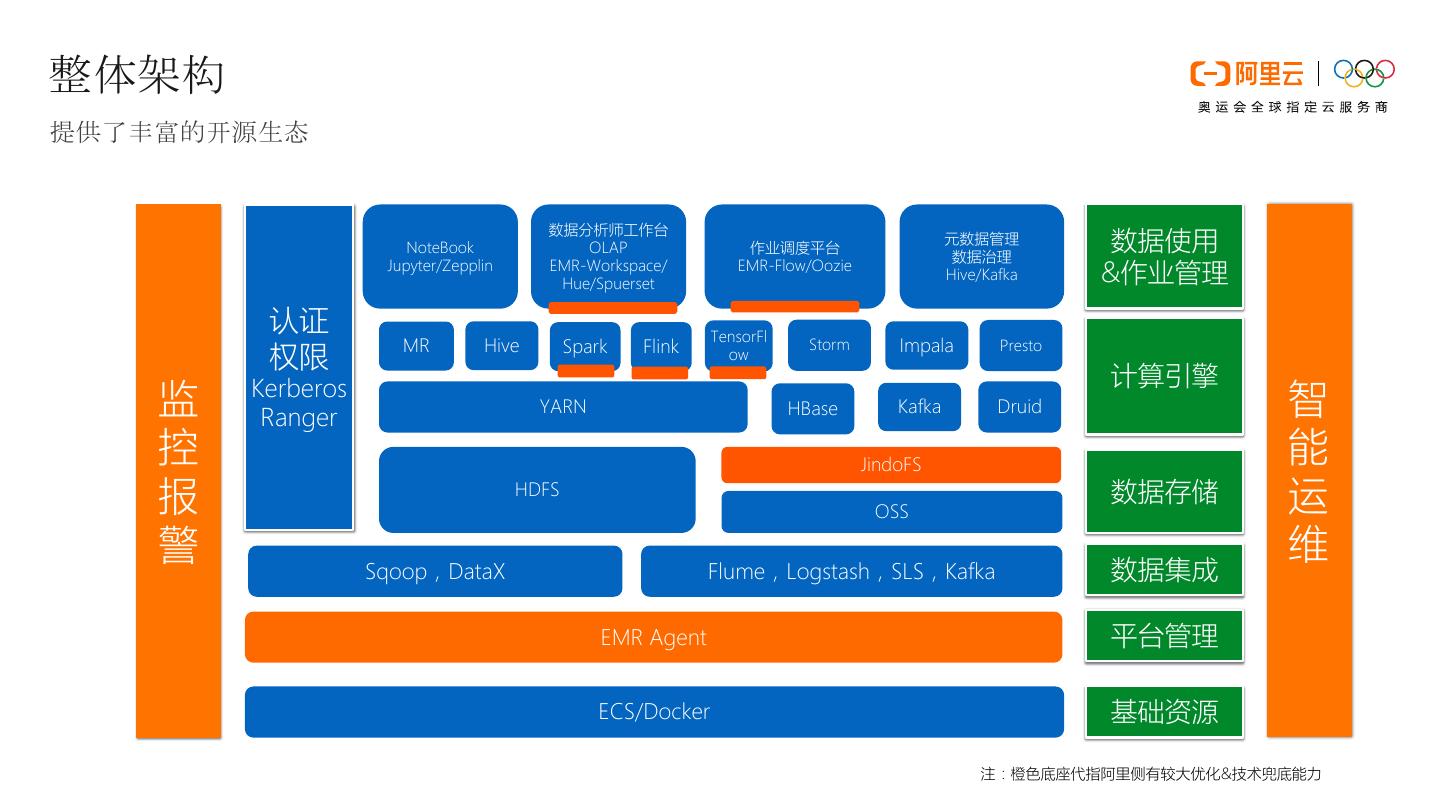
3 .整体架构 提供了丰富的开源生态 数据分析师工作台 NoteBook OLAP 作业调度平台 元数据管理 数据治理 数据使用 Jupyter/Zepplin EMR-Workspace/ Hue/Spuerset EMR-Flow/Oozie Hive/Kafka &作业管理 认证 TensorFl MR Hive Spark Flink Storm Impala Presto 权限 ow 计算引擎 监 Kerberos Ranger YARN HBase Kafka Druid 智 控 JindoFS 能 报 HDFS OSS 数据存储 运 警 维 Sqoop,DataX Flume,Logstash,SLS,Kafka 数据集成 EMR Agent 平台管理 ECS/Docker 基础资源 注:橙色底座代指阿里侧有较大优化&技术兜底能力
4 .E-MapReduce开源大数据平台 Ø 管理运维能力 • 集群管理,作业管理和调度 • 操作Web化、SDK&API Ø 完全兼容开源系统,并在之基础上强化 • Hadoop, Spark性能优化 • 监控能力能整合强化 开源 企业级 Ø 伴随社区发展的生态 • 组件跟随开源社区保持版本升级 Hadoop 大数据 • 开源与阿里云平台的联结者,充分发挥云的生态能力 生态 平台 • 云产品对接(OSS,SLS,MaxCompute等) • 云能力对接,弹性等等(本地盘实例严格打散,弹性伸缩 能力,支持竞价实例) Ø 全球部署(全球15个region部署),基于企业级开源大数据生 态上多样化场景方案的快速复制 Ø 提供完整的企业级的一体化平台 • 打包计算平台能力 • 开箱即用的体验
5 .E-MapReduce开源大数据平台 引导操作 在集群启动 Hadoop 前执行您自定义的脚本,以便安装您需要的第三方软件或者修改集群运行环境。 • 使用 yum 安装已经提供的软件。 • 直接下载公网上的一些公开的软件。 • 读取 OSS 中您的自有数据。 • 安装并运行一个服务,例如 Kylin或者 Kudu等等,但需要编写的脚本会复杂些。 运行条件引导操作,可以指定节点的角色执行不动的动作 是否是Master?
6 .E-MapReduce开源大数据平台 软件配置 在集群启动时需要对其软件配置进行修改时,可以使用软件配置功能来实现。目前软件配置操作只能在集群 启动时执行一次。 举例2个场景: • HDFS 服务器的服务线程数目 dfs.namenode.handler.count 默 认是 10,假设要加大到 50; • HDFS 的文件块的大小 dfs.blocksize 默认是 128 MB,假设系 统都是小文件,想要改小到 64 MB。 [ { "ServiceName":"YARN", "FileName":"yarn-site", "ConfigKey":"yarn.nodemanager.resource.cpu-vcores", "ConfigValue":"8" }, { "ServiceName":”HDFS", "FileName":”core-site", "ConfigKey":" dfs.namenode.handler.count ", "ConfigValue":”50" } ]
7 .E-MapReduce开源大数据平台 元数据库的选择 提供给Hive做Meta数据库使用,尤其在使用动态集群的时候必须要有。 • 外部的独立RDS(推荐) • 集群内部默认的Mysql • EMR提供的统一元数据库
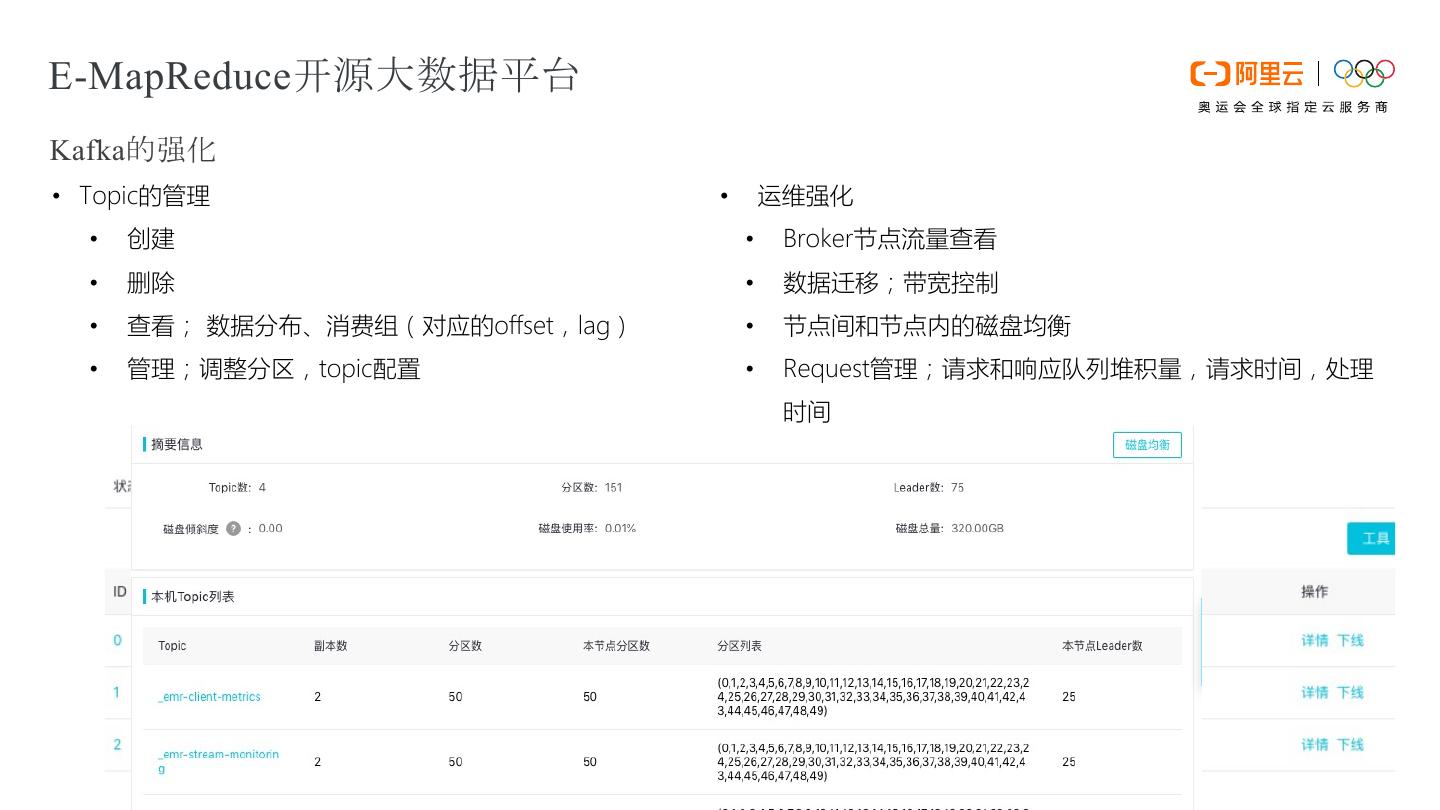
8 .E-MapReduce开源大数据平台 Kafka的强化 • Topic的管理 • 运维强化 • 创建 • Broker节点流量查看 • 删除 • 数据迁移;带宽控制 • 查看; 数据分布、消费组(对应的offset,lag) • 节点间和节点内的磁盘均衡 • 管理;调整分区,topic配置 • Request管理;请求和响应队列堆积量,请求时间,处理 时间
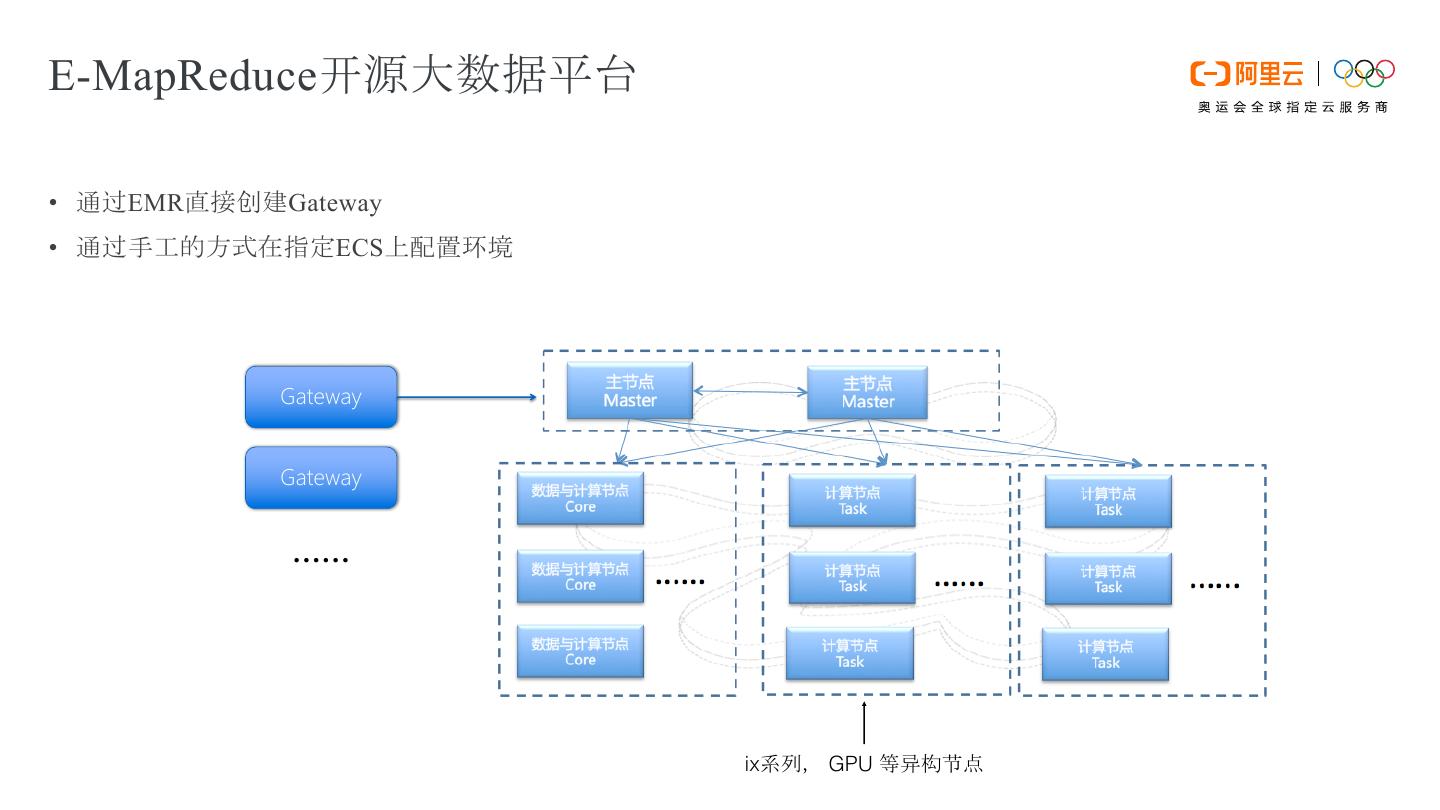
9 .E-MapReduce开源大数据平台 • 通过EMR直接创建Gateway • 通过手工的方式在指定ECS上配置环境 Gateway Gateway …… ix系列, GPU 等异构节点
10 .E-MapReduce开源大数据平台 如何登陆Core节点 Ø 登录Core节点,按照以下步骤操作: 1.在Master节点上切换到hadoop账号。 2.su hadoop Ø 免密码SSH登录到对应的Core节点;通过sudo命令可以获得root权限。 1.ssh emr-worker-1 2.sudo vi /etc/hosts
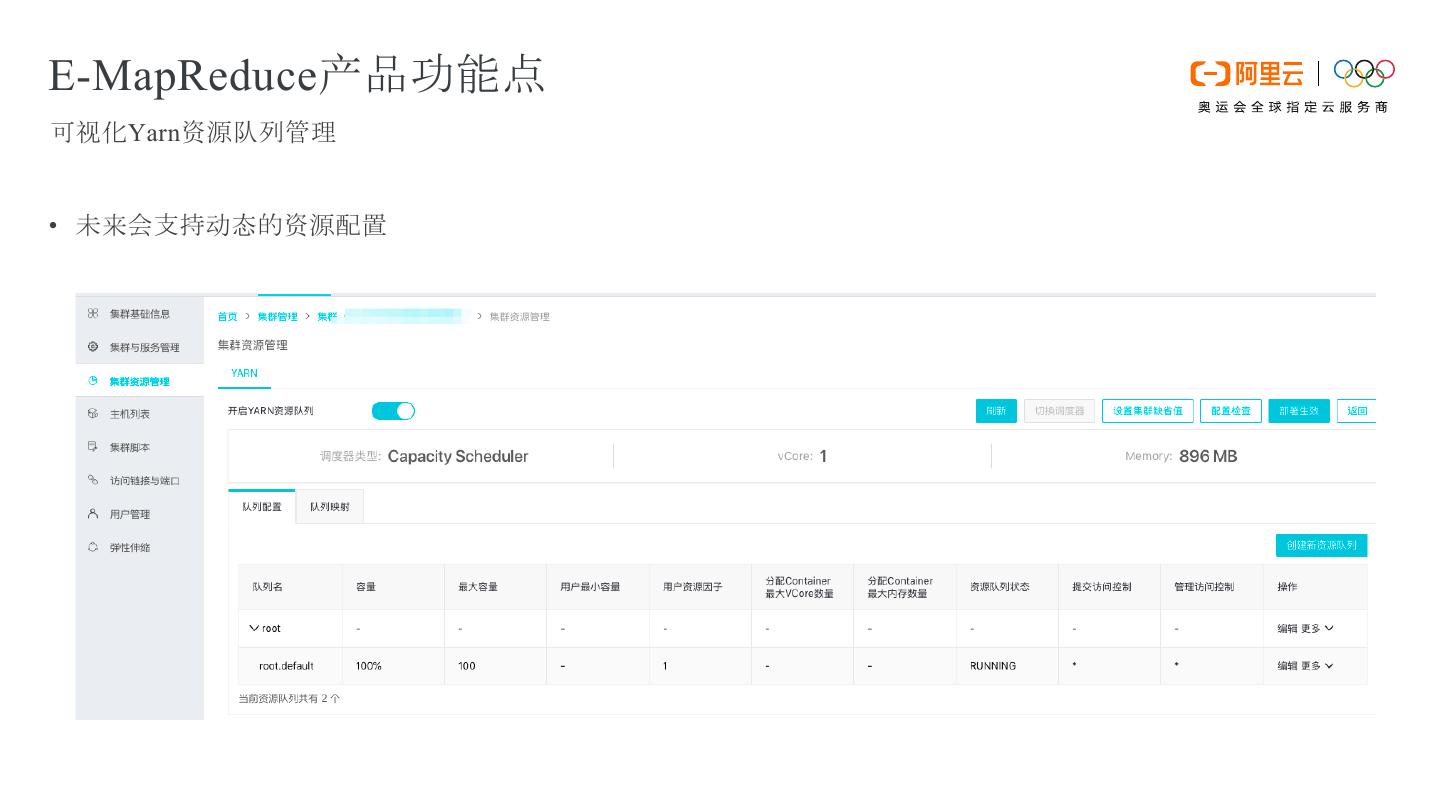
11 .E-MapReduce产品功能点 可视化Yarn资源队列管理 • 未来会支持动态的资源配置
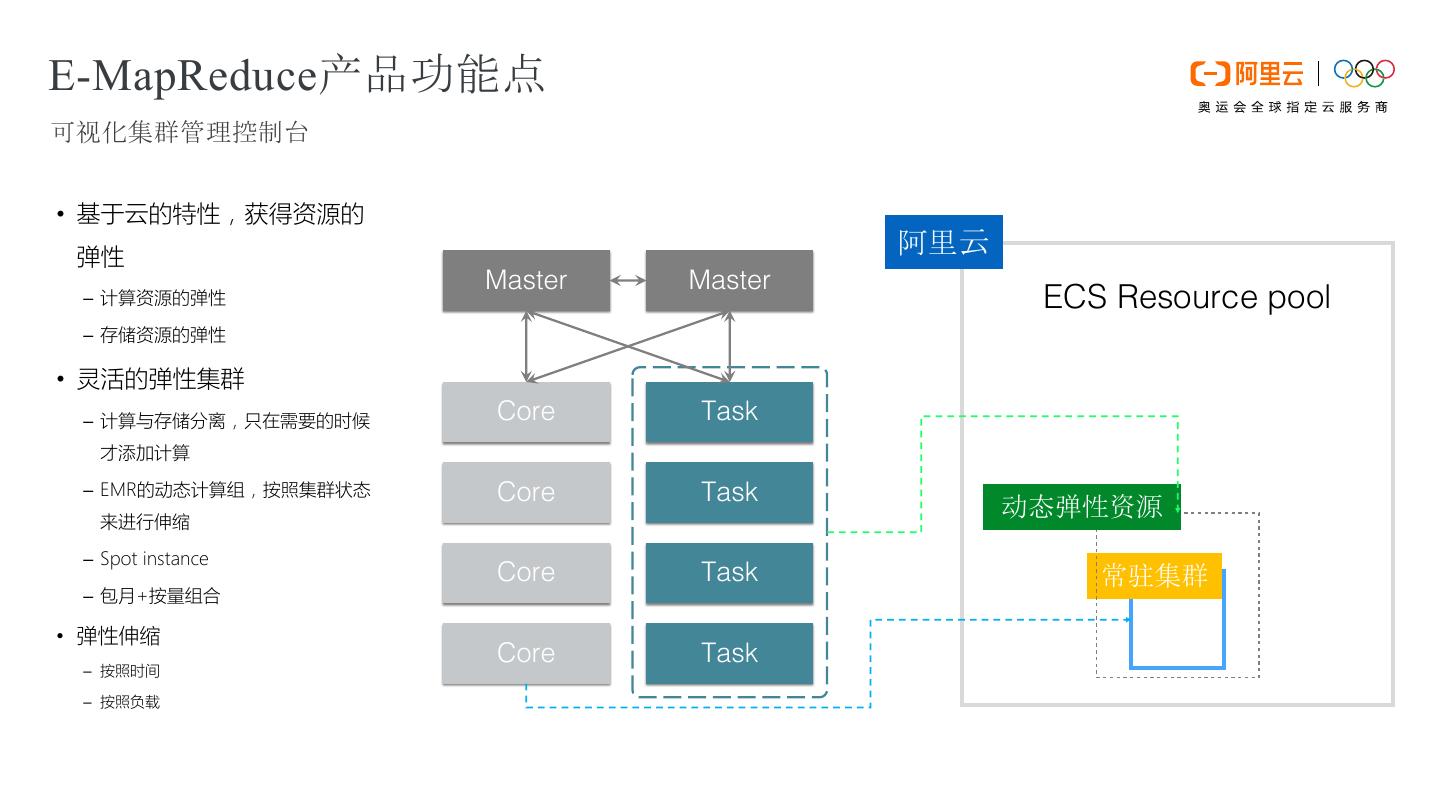
12 .E-MapReduce产品功能点 可视化集群管理控制台 • 基于云的特性,获得资源的 Active Standby 弹性 阿里云 Master Master – 计算资源的弹性 ECS Resource pool – 存储资源的弹性 • 灵活的弹性集群 – 计算与存储分离,只在需要的时候 Core Task 才添加计算 – EMR的动态计算组,按照集群状态 Core Task 来进行伸缩 动态弹性资源 – Spot instance Core Task 常驻集群 – 包月+按量组合 • 弹性伸缩 Core Task – 按照时间 – 按照负载 计算和存储节点 计算节点
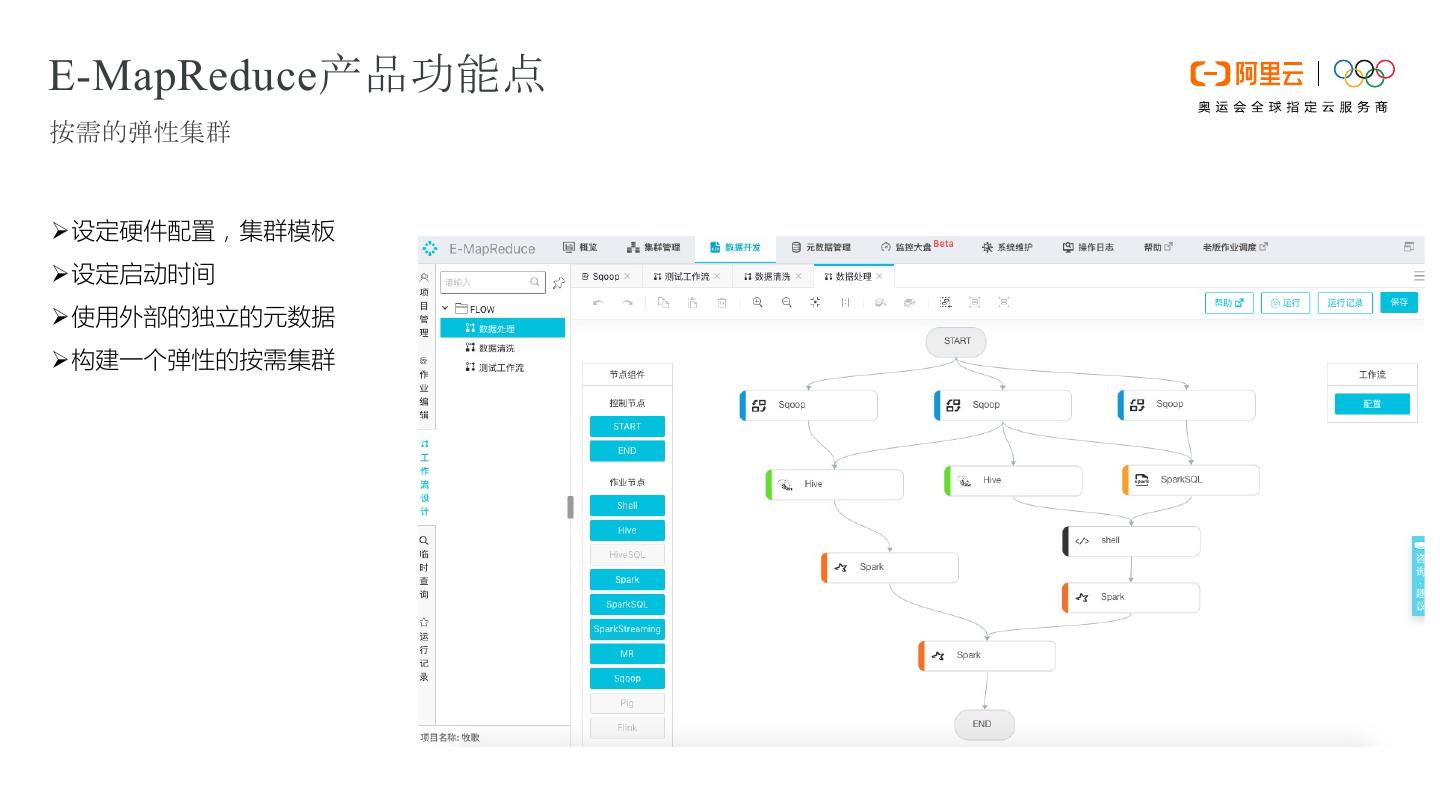
13 .E-MapReduce产品功能点 按需的弹性集群 Ø设定硬件配置,集群模板 Ø设定启动时间 Ø使用外部的独立的元数据 Ø构建一个弹性的按需集群
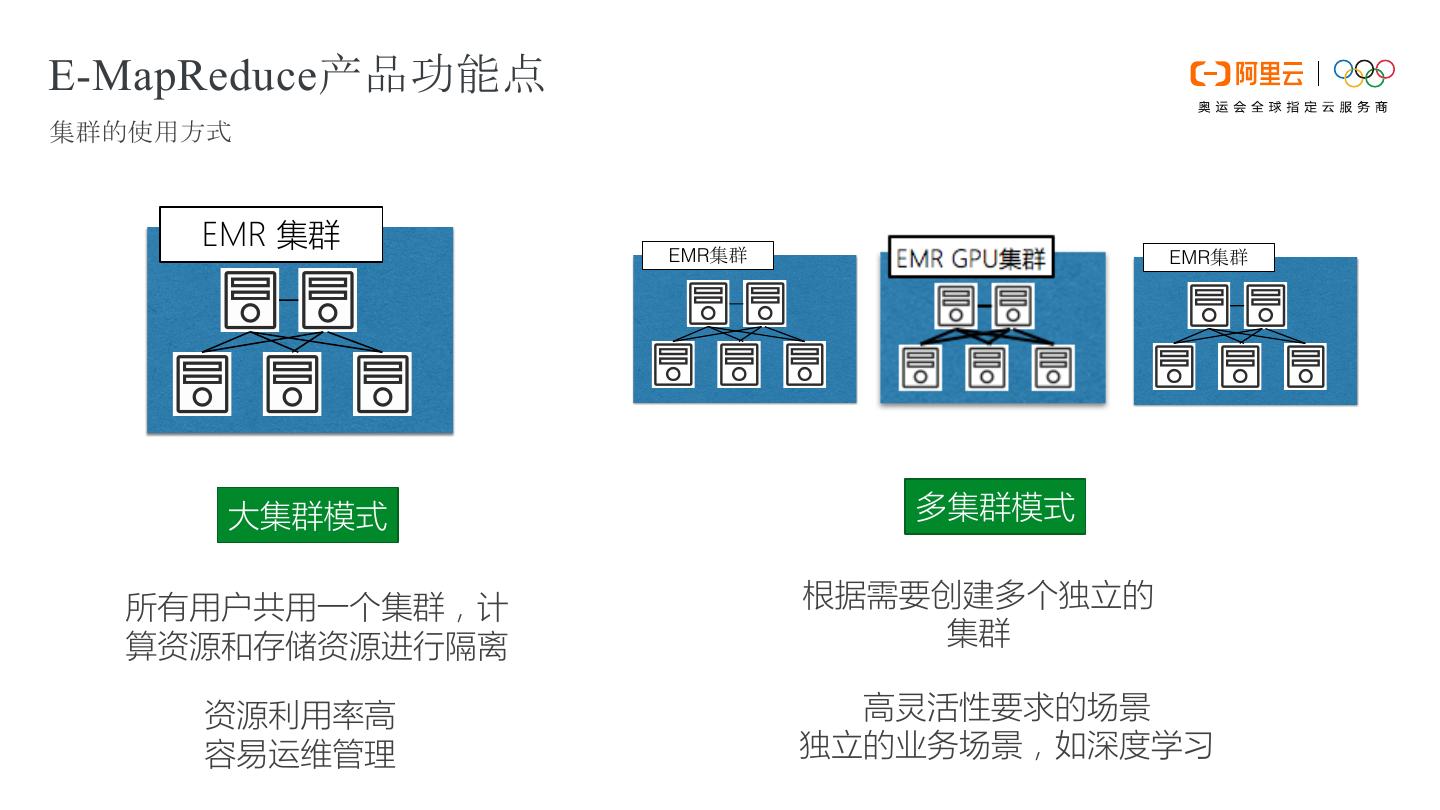
14 .E-MapReduce产品功能点 集群的使用方式 EMR 集群 EMR EMR 大集群模式 多集群模式 所有用户共用一个集群,计 根据需要创建多个独立的 算资源和存储资源进行隔离 集群 资源利用率高 高灵活性要求的场景 容易运维管理 独立的业务场景,如深度学习
15 . 产品介绍 监控优势 CONTENT 产品实践
16 .E-MapReduce产品优势 监控方案 1. 云端的监控方案,不额外消耗资源成本,完全EMR团队运维 2. 根据EMR服务开源大数据客户这么多年的经验,扩展了非常多的指标采集实现,传统的方案(zabbix, ganglia)只支持一些通用的系统指标,开源大数据生态服务特定的指标采集很少,需要自己实现采集脚本并 且集成到这些采集系统中,这个普通去开发会消耗大量的人力。我们有专人来进行这块的工作 3. 针对EMR服务大客户的经验,默认定制了一整套的服务稳定性相关的告警规则,传统的其它开源方案这块是 没有的; 4. 除了对系统和服务指标有采集监控,还加入了日志的分析处理和异常检测,其它开源方案里面是没有的; 5. 提供了对作业的分析诊断以及统计报表、以及整个集群环境和健康度的大盘; 6. 对于超大规模的集群,我们也有长期应用的优势和经验的,传统的开源的方案,很少有达到1000台+规模的 集群,每天的指标数据起码是几十亿到一百亿,这还不包括对所有服务和作业日志数据的分析处理,日志数据 的分析处理会更大,这么大的数据需要实时分析处理,实时分析处理引擎、实时告警引擎需要具有很高的时效 性和吞吐,我们所有的方案均在实际的生产环境验证过的,且有效的支撑了大量的客户;
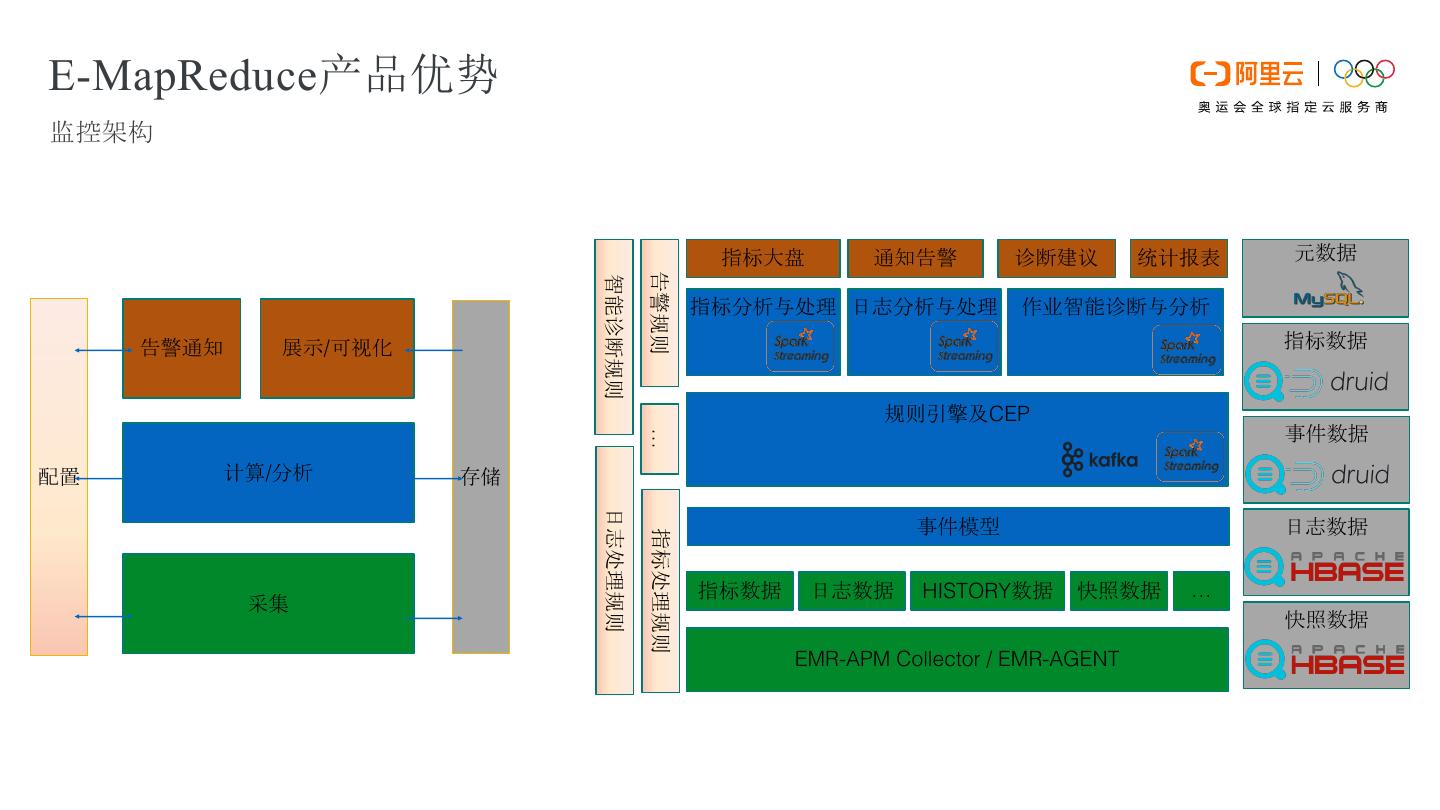
17 .E-MapReduce产品优势 监控架构 指标大盘 通知告警 诊断建议 统计报表 元数据 告警规则 智能诊断规则 指标分析与处理 日志分析与处理 作业智能诊断与分析 告警通知 展示/可视化 指标数据 规则引擎及CEP 事件数据 … 配置 计算/分析 存储 日志处理规则 事件模型 日志数据 指标处理规则 指标数据 日志数据 HISTORY数据 快照数据 … 采集 快照数据 EMR-APM Collector / EMR-AGENT
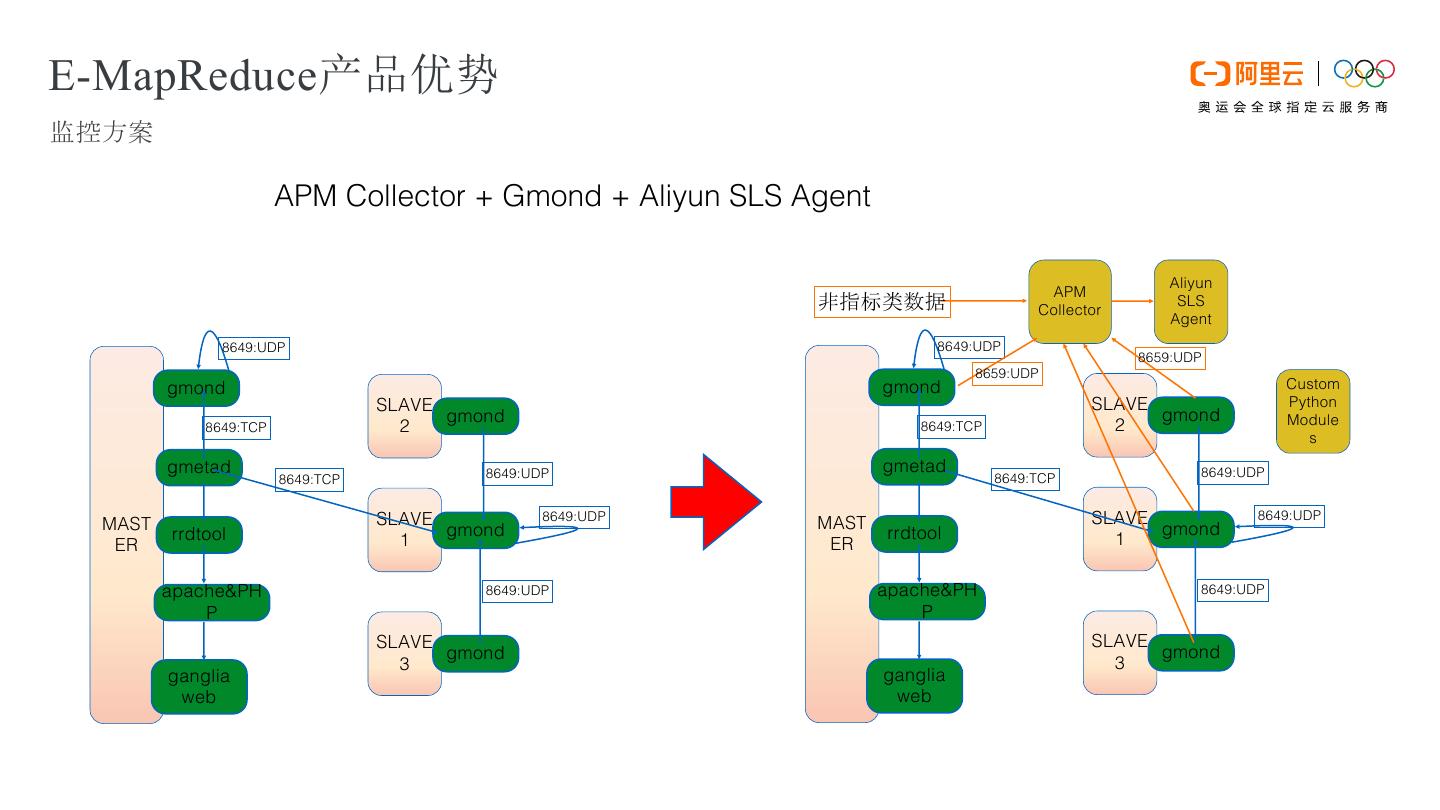
18 .E-MapReduce产品优势 监控方案 APM Collector + Gmond + Aliyun SLS Agent Aliyun APM 非指标类数据 Collector SLS Agent 8649:UDP 8649:UDP 8659:UDP 8659:UDP gmond gmond Custom SLAVE SLAVE Python gmond gmond Module 8649:TCP 2 8649:TCP 2 s gmetad 8649:UDP gmetad 8649:UDP 8649:TCP 8649:TCP MAST SLAVE 8649:UDP MAST SLAVE 8649:UDP rrdtool gmond rrdtool gmond ER 1 ER 1 apache&PH 8649:UDP apache&PH 8649:UDP P P SLAVE SLAVE gmond gmond 3 3 ganglia ganglia web web
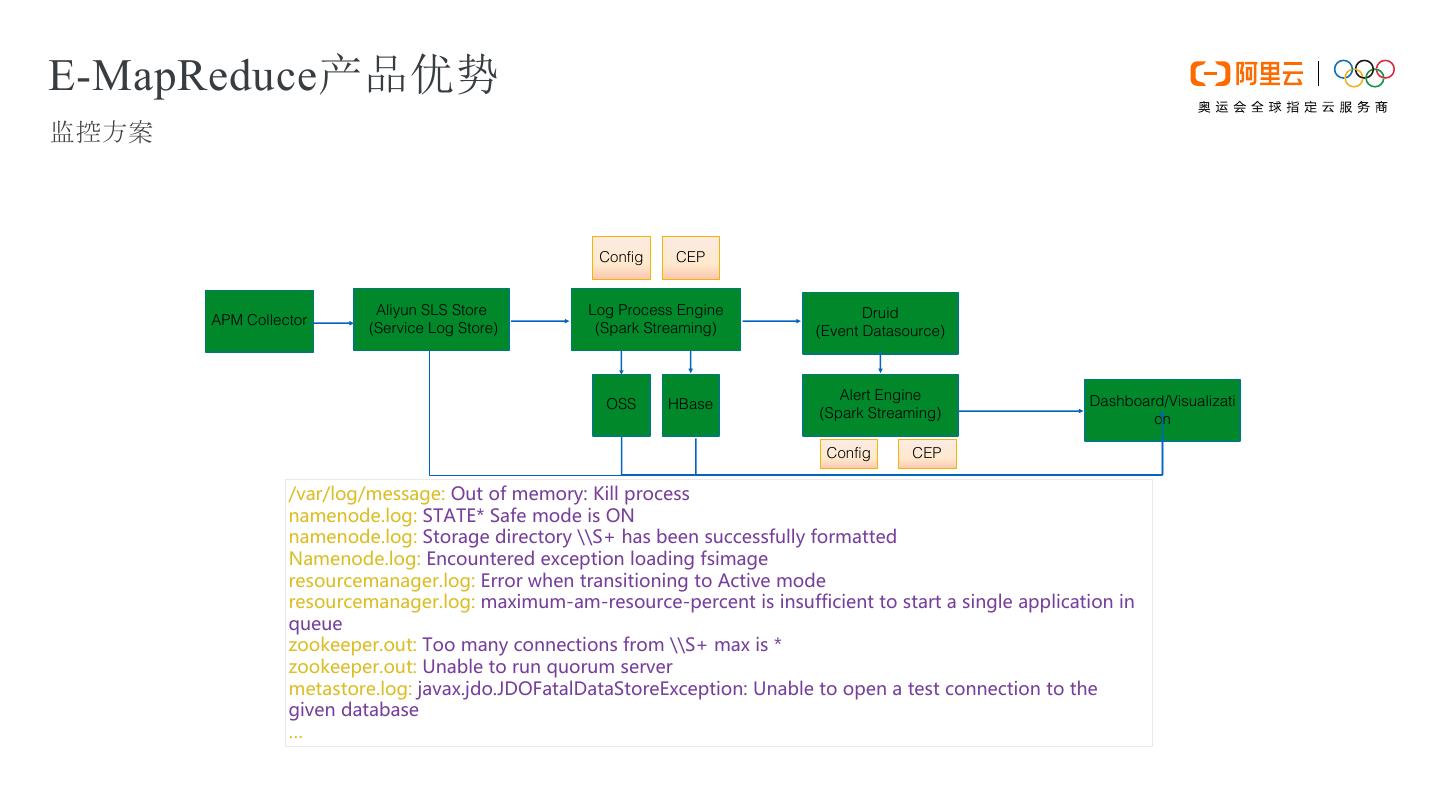
19 .E-MapReduce产品优势 监控方案 Config CEP log Aliyun SLS Store log Log Process Engine event Druid APM Collector (Service Log Store) (Spark Streaming) (Event Datasource) Alert Engine Dashboard/Visualizati OSS HBase (Spark Streaming) on Config CEP /var/log/message: Out of memory: Kill process namenode.log: STATE* Safe mode is ON namenode.log: Storage directory \\S+ has been successfully formatted Namenode.log: Encountered exception loading fsimage resourcemanager.log: Error when transitioning to Active mode resourcemanager.log: maximum-am-resource-percent is insufficient to start a single application in queue zookeeper.out: Too many connections from \\S+ max is * zookeeper.out: Unable to run quorum server metastore.log: javax.jdo.JDOFatalDataStoreException: Unable to open a test connection to the given database …
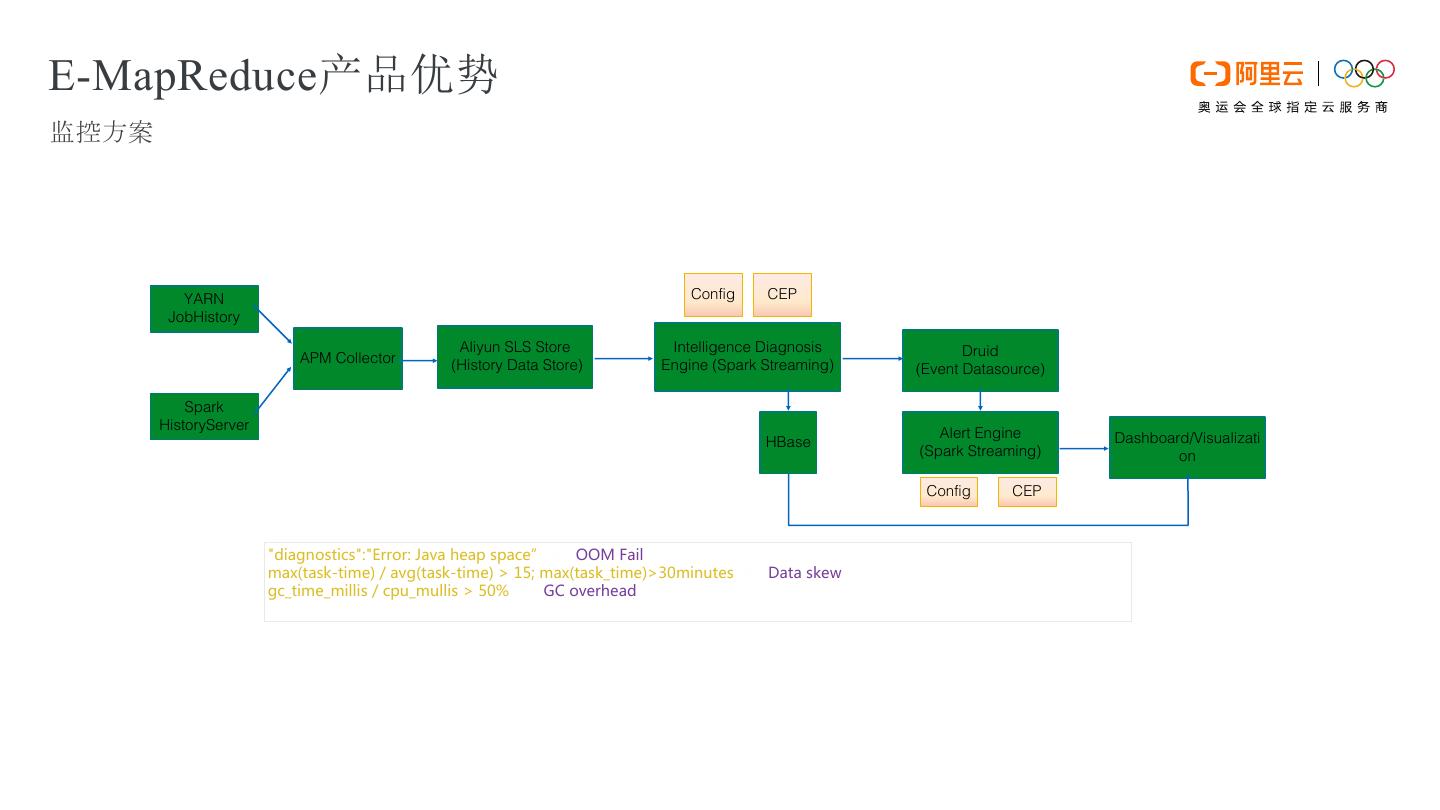
20 .E-MapReduce产品优势 监控方案 YARN Config CEP JobHistory Aliyun SLS Store Intelligence Diagnosis event Druid APM Collector (History Data Store) Engine (Spark Streaming) (Event Datasource) Spark HistoryServer Alert Engine Dashboard/Visualizati HBase (Spark Streaming) on Config CEP "diagnostics":"Error: Java heap space”➔ OOM Fail max(task-time) / avg(task-time) > 15; max(task_time)>30minutes ➔ Data skew gc_time_millis / cpu_mullis > 50% ➔ GC overhead …
21 . 产品介绍 产品对比分析 CONTENT 产品实践
22 .客户能力提升 如何提高整体利用率? 1. 消除Master节点的单点瓶颈,比如NameNode的RPC callqueue监控,ResourceManager调度瓶颈优化,Hive元数据库 (MySQL)的性能调优等,避免因为Master的性能问题影响整体利用率。如果单点性能短时间内无法继续优化,切换federation方 案。 2. 用户作业类型优化,比如传统的MapReduce作业可以迁移到Spark上,Spark可以更好的利用率内存,减少IO,从整体上提 升CPU利用率。同时软件层进行优化,如对Spark进行优化。 3. 用户资源申请优化,需要获得用户作业的CPU/内存实际使用和申请量比例,比如MapReduce框架有“CPU time spent”和 “Physical memory (bytes) snapshot”是实际的资源使用量,YARN作业完成后会显示 Aggregate Resource Allocation: xxx MB- seconds, xxx vcore-seconds,这是在调度层面使用的资源。提高资源实际使用和申请量的比例,提升整体的利用率 4. 实践计算和存储分离的架构,因为计算资源和存储资源需求量不匹配,可能会导致CPU资源空闲但磁盘空间紧张(或者反过 来),可以将部分冷数据迁移到冷备(比如阿里云上OSS低频访问或归档存储上),或者使用EMR弹性扩容机制,使用单独的 计算节点补充CPU等资源。
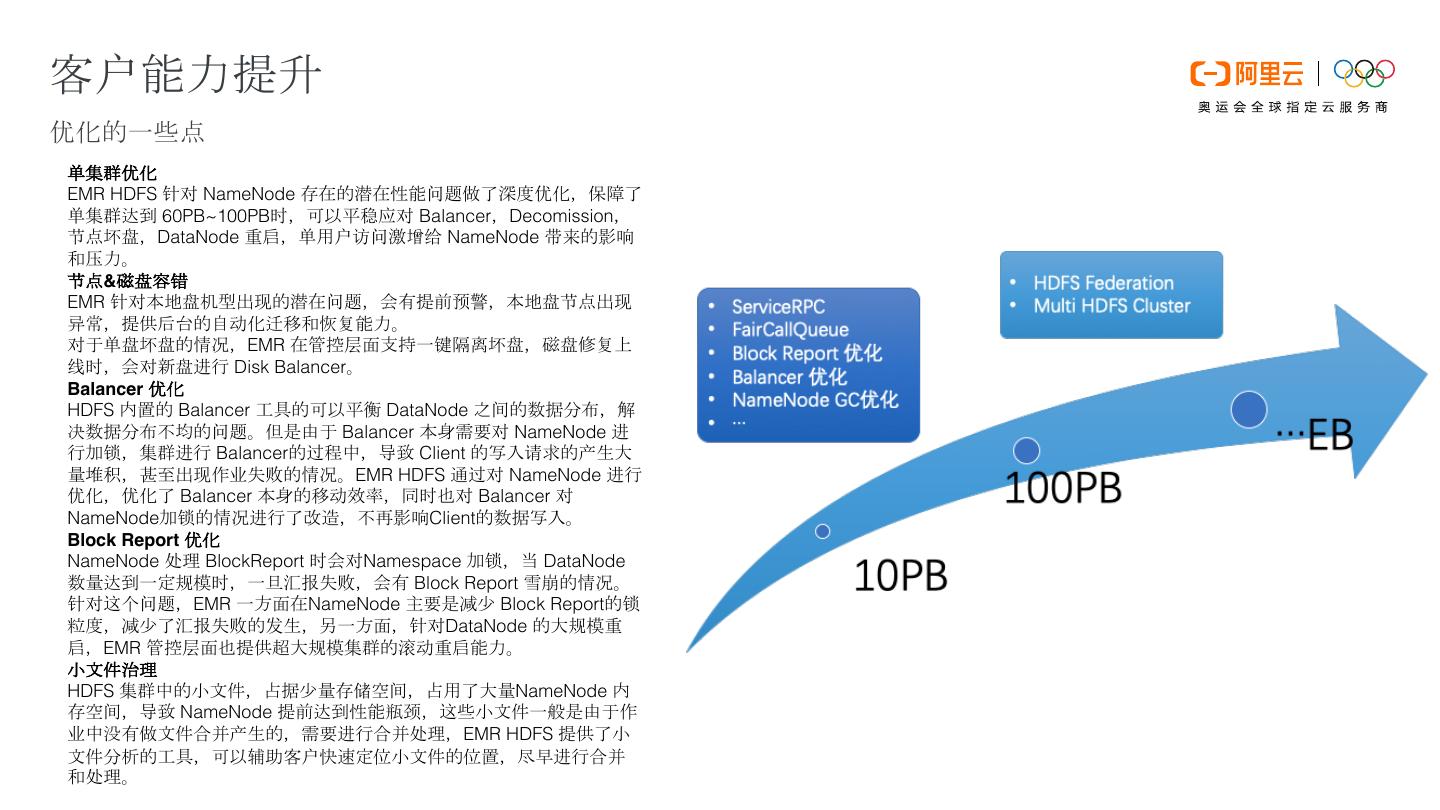
23 .客户能力提升 优化的一些点 单集群优化 EMR HDFS 针对 NameNode 存在的潜在性能问题做了深度优化,保障了 单集群达到 60PB~100PB时,可以平稳应对 Balancer,Decomission, 节点坏盘,DataNode 重启,单用户访问激增给 NameNode 带来的影响 和压力。 节点&磁盘容错 EMR 针对本地盘机型出现的潜在问题,会有提前预警,本地盘节点出现 异常,提供后台的自动化迁移和恢复能力。 对于单盘坏盘的情况,EMR 在管控层面支持一键隔离坏盘,磁盘修复上 线时,会对新盘进行 Disk Balancer。 Balancer 优化 HDFS 内置的 Balancer 工具的可以平衡 DataNode 之间的数据分布,解 决数据分布不均的问题。但是由于 Balancer 本身需要对 NameNode 进 行加锁,集群进行 Balancer的过程中,导致 Client 的写入请求的产生大 量堆积,甚至出现作业失败的情况。EMR HDFS 通过对 NameNode 进行 优化,优化了 Balancer 本身的移动效率,同时也对 Balancer 对 NameNode加锁的情况进行了改造,不再影响Client的数据写入。 Block Report 优化 NameNode 处理 BlockReport 时会对Namespace 加锁,当 DataNode 数量达到一定规模时,一旦汇报失败,会有 Block Report 雪崩的情况。 针对这个问题,EMR 一方面在NameNode 主要是减少 Block Report的锁 粒度,减少了汇报失败的发生,另一方面,针对DataNode 的大规模重 启,EMR 管控层面也提供超大规模集群的滚动重启能力。 小文件治理 HDFS 集群中的小文件,占据少量存储空间,占用了大量NameNode 内 存空间,导致 NameNode 提前达到性能瓶颈,这些小文件一般是由于作 业中没有做文件合并产生的,需要进行合并处理,EMR HDFS 提供了小 文件分析的工具,可以辅助客户快速定位小文件的位置,尽早进行合并 和处理。
24 .
0点赞
0收藏
3秒后跳转登录页面
去登陆

