展开查看详情
1 . | E-MapReduce | 对象存储OSS
数据湖 JindoFS + OSS 实操36讲
【数据迁移】 高效迁移 HDFS 海量文件到 OSS
演讲人:扬礼
阿里巴巴计算平台事业部 EMR 开发工程师
2021.05.11
�
2 . DistCp 介绍
Jindo DistCp 介绍
CONTENT
性能优化
功能演示
�
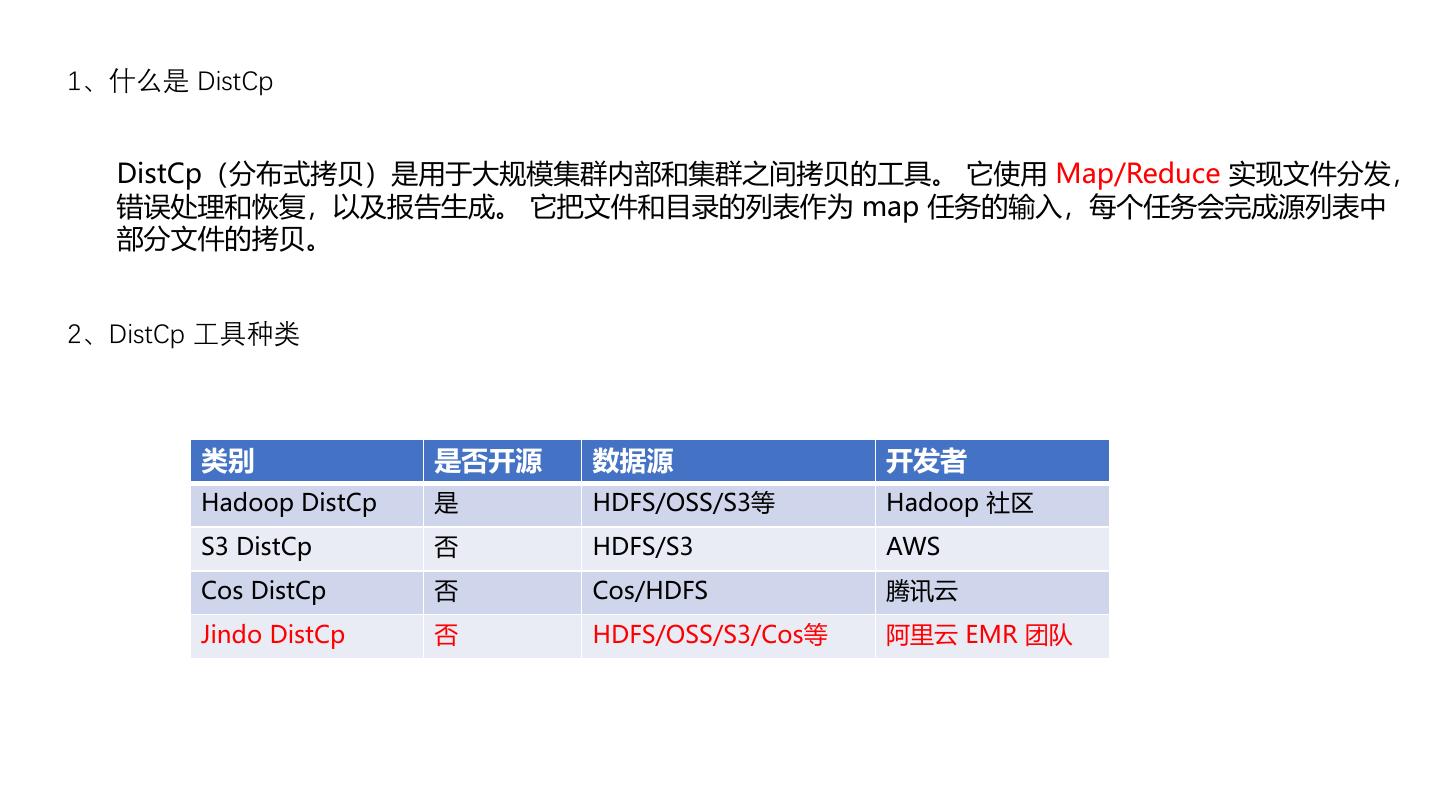
3 .1、什么是 DistCp
DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具。 它使用 Map/Reduce 实现文件分发,
错误处理和恢复,以及报告生成。 它把文件和目录的列表作为 map 任务的输入,每个任务会完成源列表中
部分文件的拷贝。
2、DistCp 工具种类
类别 是否开源 数据源 开发者
Hadoop DistCp 是 HDFS/OSS/S3等 Hadoop 社区
S3 DistCp 否 HDFS/S3 AWS
Cos DistCp 否 Cos/HDFS 腾讯云
Jindo DistCp 否 HDFS/OSS/S3/Cos等 阿里云 EMR 团队
�
4 .Jindo DistCp 介绍
➢ 分布式文件拷贝工具,基于 MapReduce
➢ 支持多种数据源(HDFS / OSS / S3 / COS 等)
➢ 多种拷贝策略,功能对齐开源 Hadoop DistCp 及 S3 DistCp 等
➢ 深度结合 OSS,基于 native 实现的 JindoFS SDK
➢ 优化 JobCommitter,性能领先开源工具
�
5 .现有 HDFS 海量文件同步到 OSS 问题
➢ 文件数量规模大,百/千万级,开源 DistCp 超时/OOM等
➢ HDFS 拷贝到 OSS ,效率较慢,Rename 耗时
➢ 现有开源工具无法保证数据拷贝一致性
➢ 不支持传输时进行归档/冷存储等 OSS 特性
�
6 .Jindo DistCp 基于 HDFS 海量文件同步到 OSS 场景优化
➢ 分批 Batch,避免文件数过多/文件size过大,造成超时/OOM
➢ 定制化 CopyCommitter,实现 No-Rename 拷贝,并保证数据拷贝落地的一致性
➢ 大/小文件传输策略优化
➢ 基于 native 实现的 JindoFS SDK,优化读写 OSS 性能
�
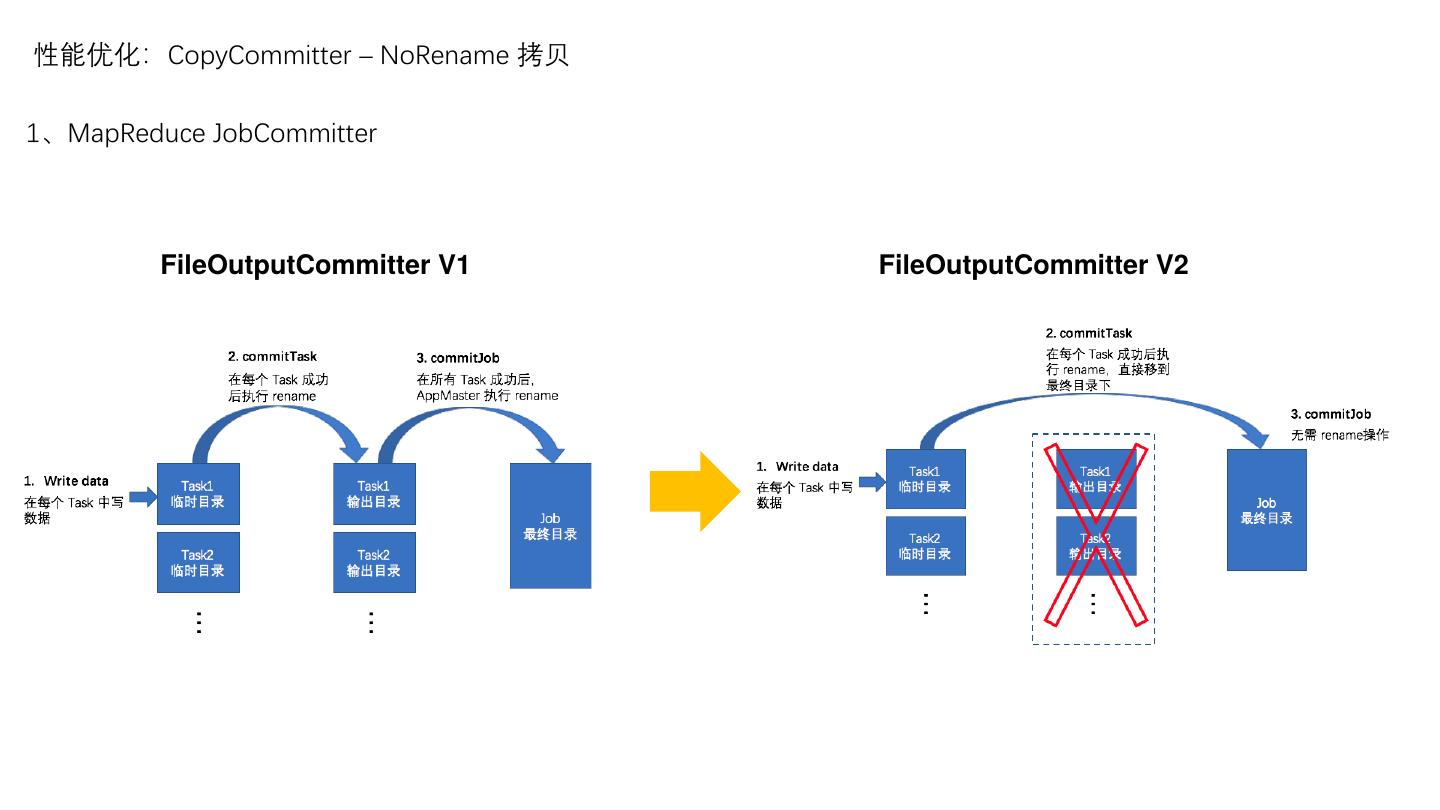
7 .性能优化:CopyCommitter – NoRename 拷贝
1、MapReduce JobCommitter
FileOutputCommitter V1 FileOutputCommitter V2
�
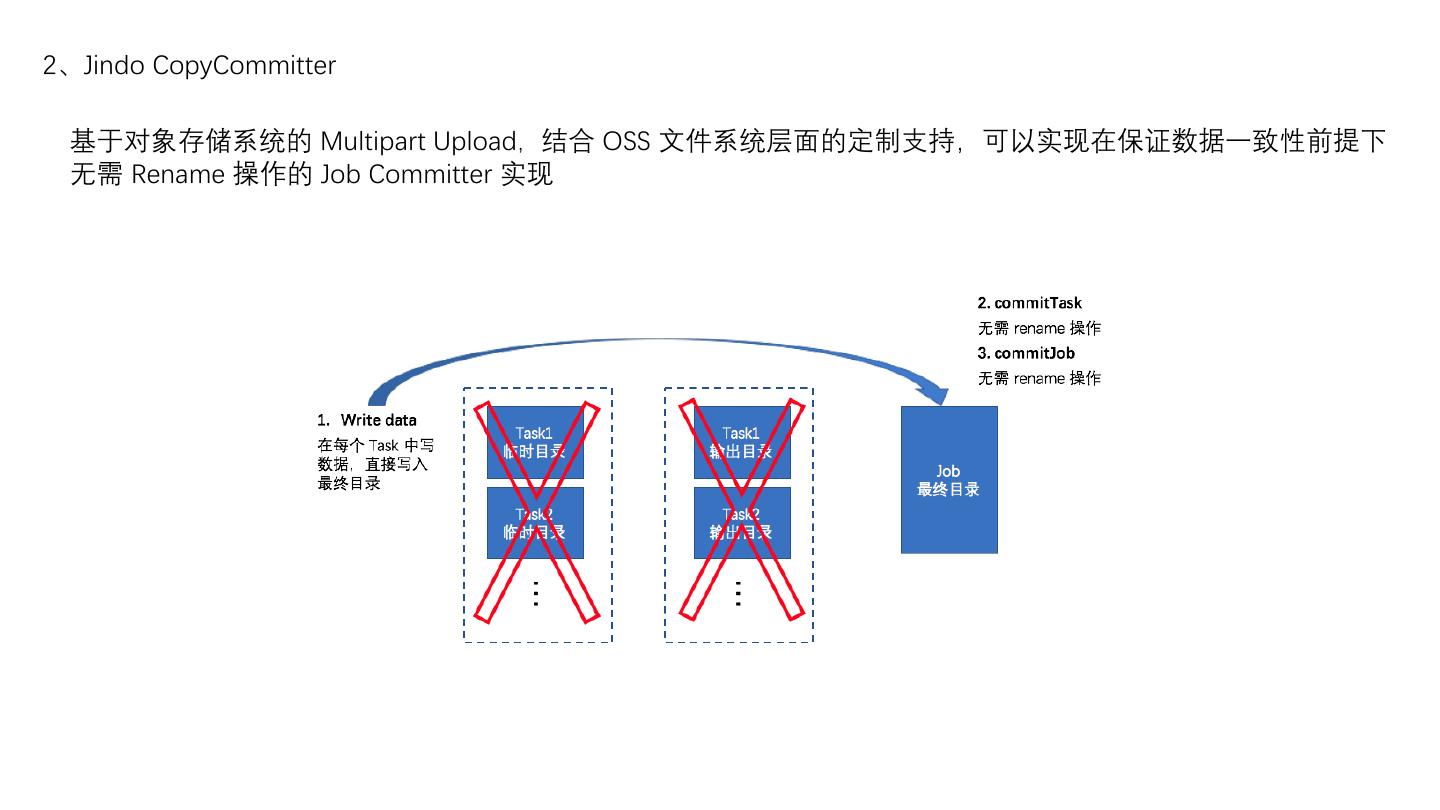
8 .2、Jindo CopyCommitter
基于对象存储系统的 Multipart Upload,结合 OSS 文件系统层面的定制支持,可以实现在保证数据一致性前提下
无需 Rename 操作的 Job Committer 实现
�
9 .性能测试
我们做了一个 Jindo DistCp 和 Hadoop DistCp的性能对比,在这个测试中我们以 HDFS 到 OSS 离线数据迁移为主要场景,利用
Hadoop 自带的测试数据集 TestDFSIO 分别生成1000个10M、1000个500M、1000个1G 大小的文件进行从 HDFS 拷贝数据到
OSS 上的测试过程。
�
10 .访问链接
https://github.com/aliyun/alibabacloud-jindofs/blob/master/docs/jindo_distcp/jindo_distcp_overview.md
�
11 .演示
1、下载 jindo-distcp-3.5.0.jar
2、将 jar 包拷贝到可提交 YARN 作业的节点上
3、选择 src 和 dest 路径及合适的参数
hadoop jar jindo-distcp-3.5.0.jar --src /data --dest oss://yang-ha/data --parallelism 10
4、执行命令
5、查看进度(命令行/WebUI)
�
12 . | E-MapReduce | 对象存储OSS
数据湖 JindoFS OSS 实操36讲
【数据无忧】利用 Checksum 迁移 HDFS 数据到 OSS
演讲人:焱冰
阿里巴巴计算平台事业部 EMR 技术专家
2021.05.11
�
13 . 简述
Checksum
技术科普
CONTENT DistCp
技术解密
Jindo DistCp
操作实战
�
14 .DistCp & Jindo DistCp
• DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝数据的
工具。使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生
成。
• Jindo DistCp,则是基于 JindoFS SDK 的阿里云数据迁移工具。Jindo
DistCp 由阿里云 E-MapReduce 团队开发,目前支持 HDFS/OSS/S3 之
间的数据拷贝场景,提供多种个性化拷贝参数和多种拷贝策略。重点
优化 HDFS 到 OSS 的数据拷贝,通过定制化 CopyCommitter,实现
No-Rename 拷贝,并保证数据拷贝落地的完整性、一致性。
• Jindo DistCp具体文档,参见https://github.com/aliyun/alibabacloud-
jindofs/tree/master/docs/jindo_distcp
�
15 .数据迁移场景中的Checksum
• 大数据迁移使用场景:迁移后完整性校验、差异比对/增量拷贝
• 完整性校验的场景,特别是异构存储介质间的迁移场景。由于异
构存储介质间,默认的数据校验方式往往无法通用。现有的方案
往往只能跳过数据完整性校验,这使得在迁移出现问题时无法及
时发现。
• 现有的增量拷贝方案中,开源的Hadoop DistCp和S3 DistCp也会
做差异比较,在异构存储介质间只能对文件名,文件大小做比较,
不能真实反应源文件和目标文件是完全否一致。哪怕在同构存储
介质间,在做差异比较时,往往也需要将目标存储介质的数据重
新读取,并计算一次校验和。
�
16 . 简述
Checksum
技术科普
CONTENT DistCp
技术解密
Jindo DistCp
操作实战
�
17 .Checksum
• 数据校验和,可用于差错检测和完整性校验,常见的算法有:
• 奇偶校验
• MD5
• SHA-1
• SHA-256
• SHA-512
• CRC32
• CRC64
�
18 .奇偶校验
• 奇偶校验是最简单的校验算法。
• 具体做法是,在原始数据外,新增一位奇偶校验位,奇偶校验位
有两种类型:
• 以偶校验位来说,如果一组给定数据位中1的个数是奇数,补一个bit为1,
使得总的1的个数是偶数。
• 例:0000001, 补一个bit为1, 00000011。
• 以奇校验位来说,如果给定一组数据位中1的个数是奇数,补一个bit为0,
使得总的1的个数是奇数。
• 例:0000001, 补一个bit为0, 00000010。
1bit
原始数据
奇偶校验位
�
19 .数据摘要算法
• MD5、SHA-1、SHA-256、SHA-512都是数据摘要算法,均被广
泛作为密码的散列函数。
• 但由于MD5、SHA-1已经被证明为不安全的算法,目前建议使用
较新的SHA-256和SHA-512。
• 所有算法的输入均可以是不定长的数据。MD5输出是16字节
(128位),SHA-1输出为20字节(160位),SHA-256为32字节
(256位),SHA-512为64字节(512位)。
• 可以看到,SHA算法的输出长度更长,因此更难发生碰撞,数据
也更为安全。但运算速度与MD5相比,也更慢。
�
20 .循环冗余校验
• 循环冗余校验又称 CRC(Cyclic redundancy check),将待发送
的比特串看做是系数为 0 或者 1 的多项式。
• M = 1001010
• M(x) = 1*x^6 + 0*x^5 + 0*x^4 + 1*x^3 + 0*x^2 + 1*x^1 + 0*x^0
• M(x) = x^6 + x^3 + x
• CRC 编码时,发送方和接收方必须预先商定一个生成多项式 G(x)。
• 发送方将比特串和生成多项式 G(x) 进行运算得到校验码,在比特
串尾附加校验码,使得带校验码的比特串的多项式能被 G(x) 整除。
接收方接收到后,除以 G(x),若有余数,则传输有错。
原始数据 校验码 % G(x) == 0
�
21 .CRC常用的生成多项式( ITU-IEEE 规范)
�
22 .CRC的优缺点
• CRC算法的优点是算法实现相对简单、运算速度较快。而且错误检错
能力很强,因此被广泛应用于通信数据校验。
• 缺点是输出长度较短,容易被伪造,碰撞率高。
• 性能参考:CRC32 > CRC64 > MD5 > SHA-1 > SHA-512 > SHA-256
• BenchmarkMD5_100MB-8 6 175423280 ns/op
• BenchmarkSHA1_100MB-8 7 176478051 ns/op
• BenchmarkSHA256_100MB-8 3 344191216 ns/op
• BenchmarkSHA512_100MB-8 5 226938072 ns/op
• BenchmarkCRC32IEEE_100MB-8 117 10500107 ns/op
• BenchmarkCRC32Castagnoli_100MB-8 98 12991050 ns/op
• BenchmarkCRC64_100MB-8 13 86377178 ns/op
�
23 . 简述
Checksum
技术科普
CONTENT DistCp
技术解密
Jindo DistCp
操作实战
�
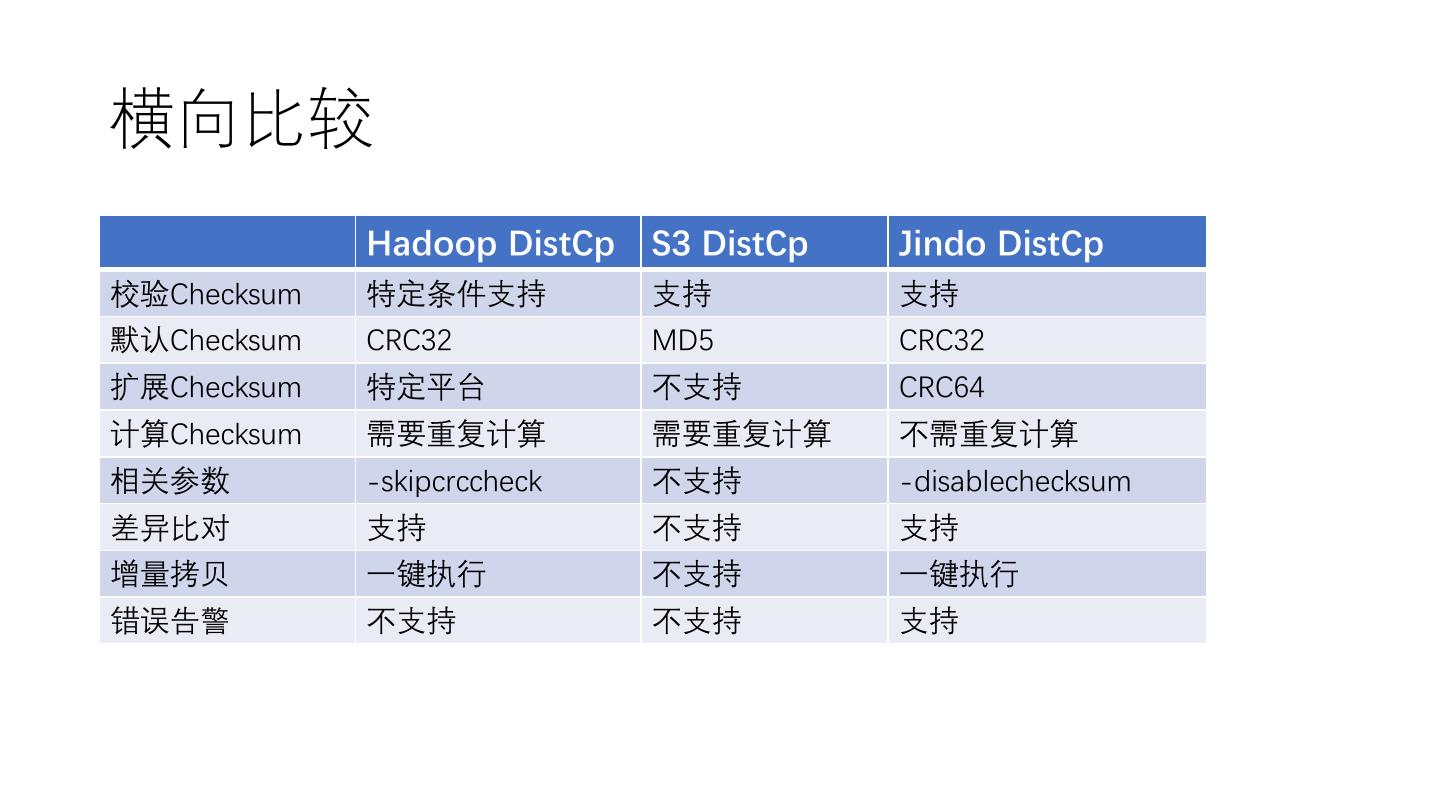
24 . Hadoop DistCp
• 默认 Checksum 算法:CRC32
• 跳过 Checksum 校验的参数:-skipcrccheck
• 差异比较:直接调用参数 -diff
• 增量拷贝:直接调用参数 –update
• Hadoop 3.1.1以上版本,支持了全新组合式CRC文件Checksum。让
Hadoop实现与外部存储系统一致的CRC算法,以满足HDFS 和其他外
部存储系统进行差异对比。但该方案有以下缺点:源存储介质和目标
存储介质必须使用相同的Checksum算法,如果是往云上迁移,往往只
能改变源端私有化存储介质的Checksum算法,去适配目标介质,有一
定改造成本。
�
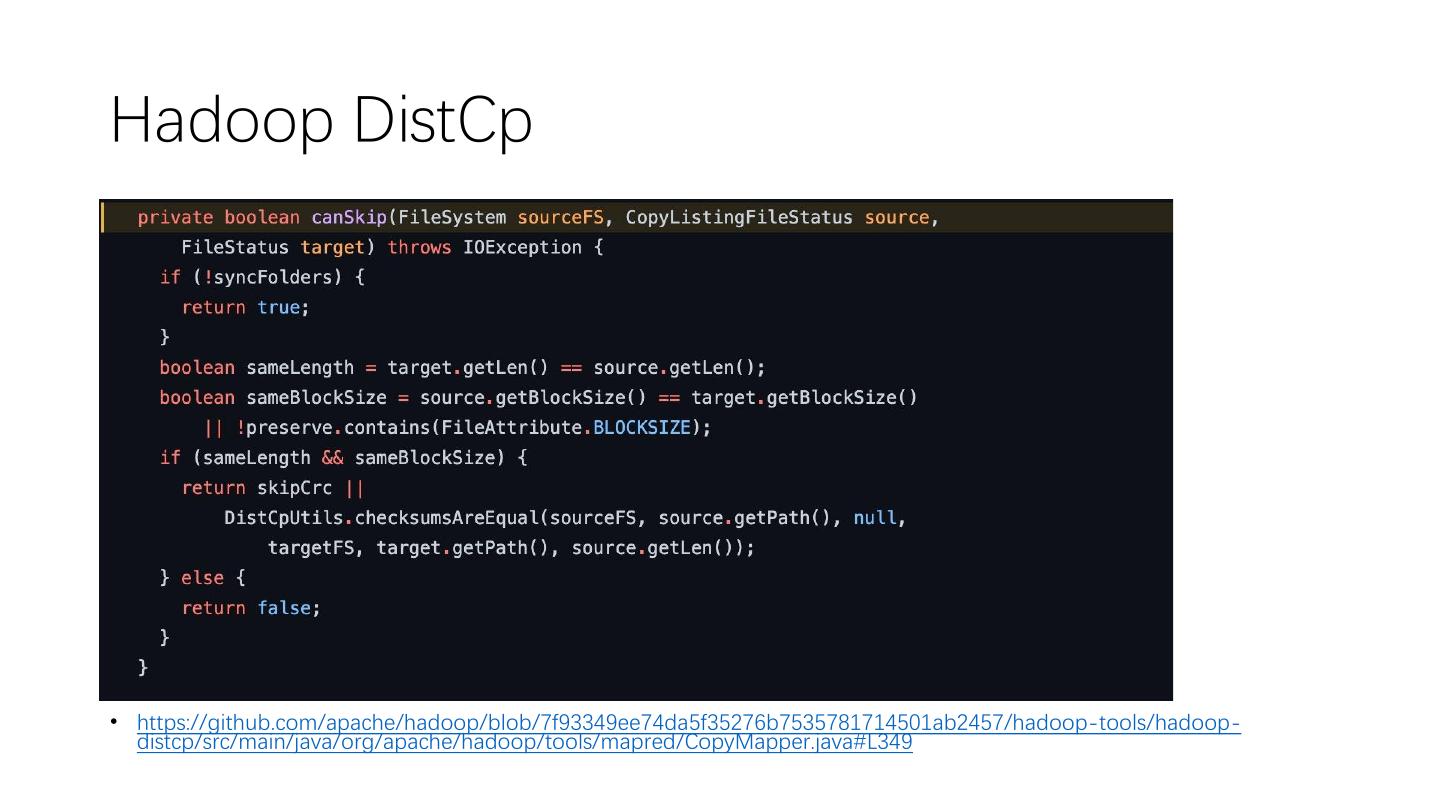
25 .Hadoop DistCp
• https://github.com/apache/hadoop/blob/7f93349ee74da5f35276b7535781714501ab2457/hadoop-tools/hadoop-
distcp/src/main/java/org/apache/hadoop/tools/mapred/CopyMapper.java#L349
�
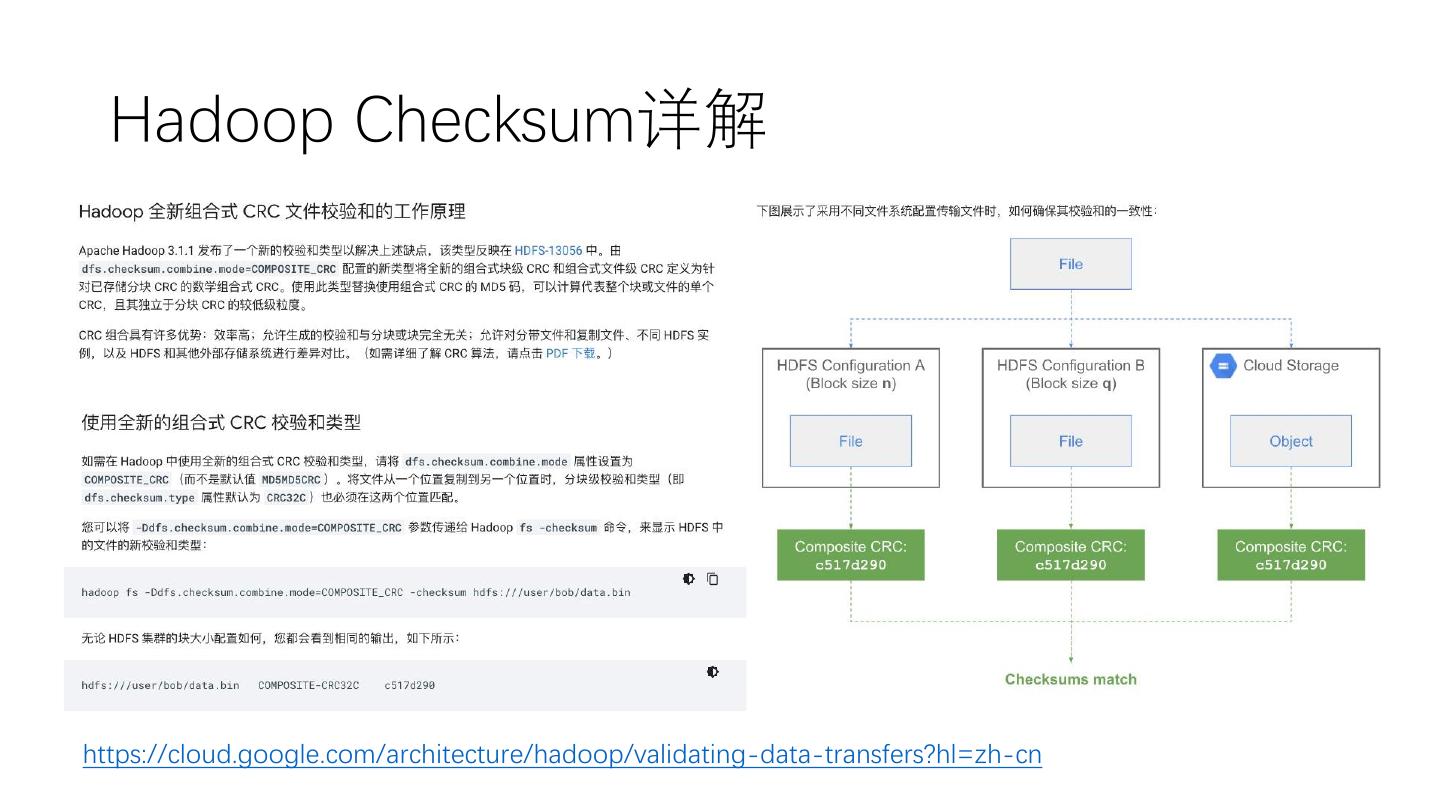
26 .Hadoop Checksum详解
• https://cloud.google.com/architecture/hadoop/validating-data-transfers?hl=zh-cn
�
27 .Hadoop Checksum详解
• https://cloud.google.com/architecture/hadoop/validating-data-transfers?hl=zh-cn
�
28 .Hadoop Checksum详解
• https://cloud.google.com/architecture/hadoop/validating-data-transfers?hl=zh-cn
�
29 . Hadoop Checksum详解
https://cloud.google.com/architecture/hadoop/validating-data-transfers?hl=zh-cn
�