










- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
RSS 使用和性能展示
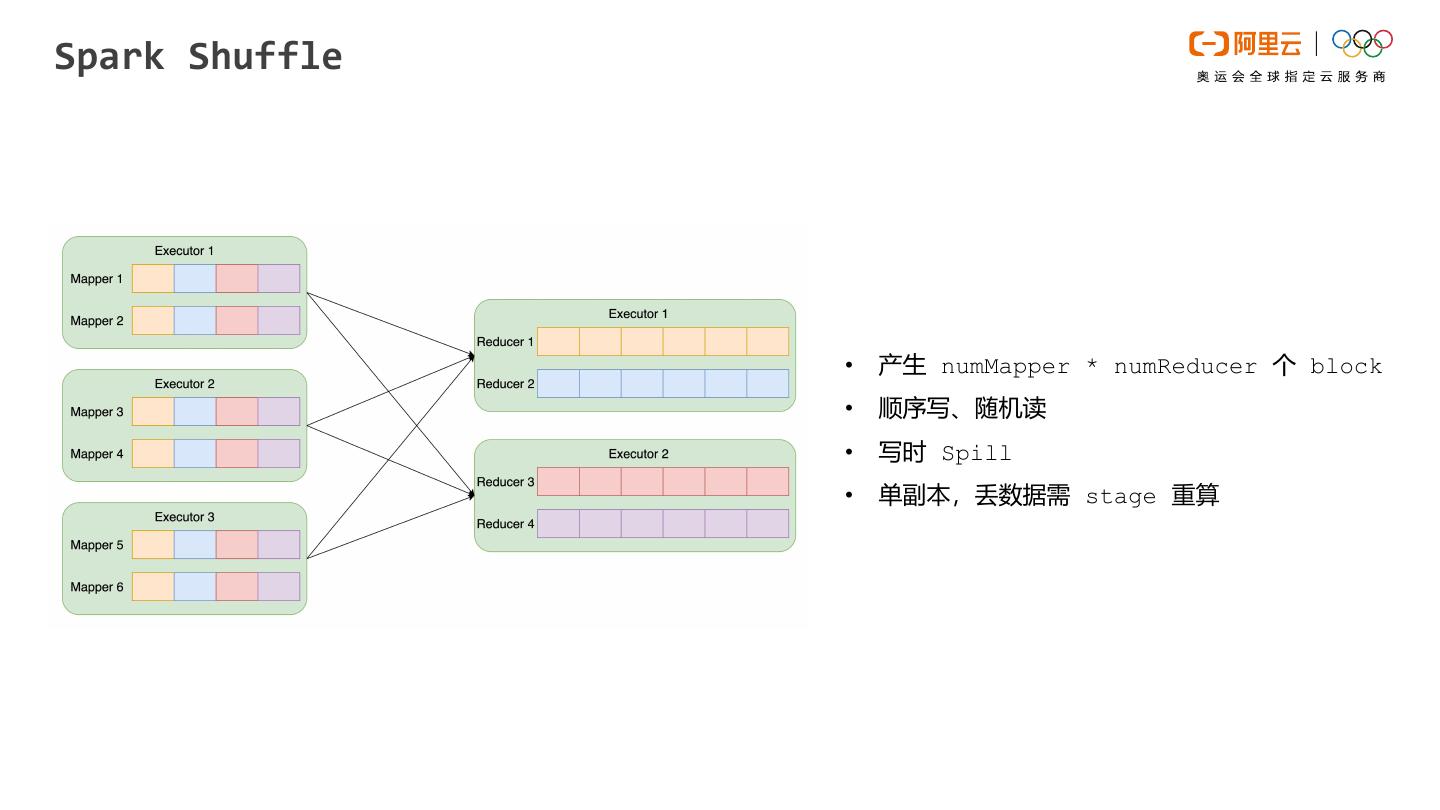
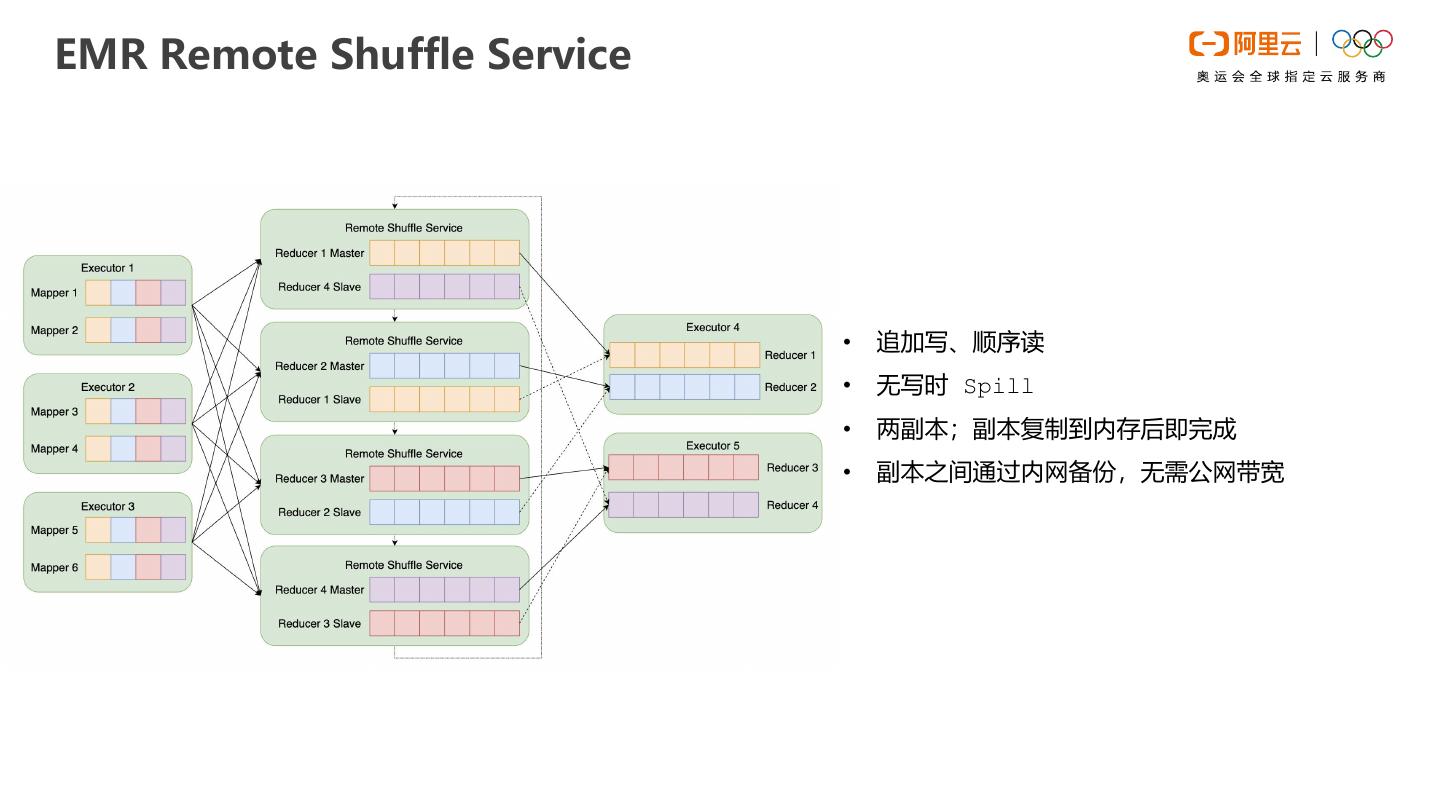
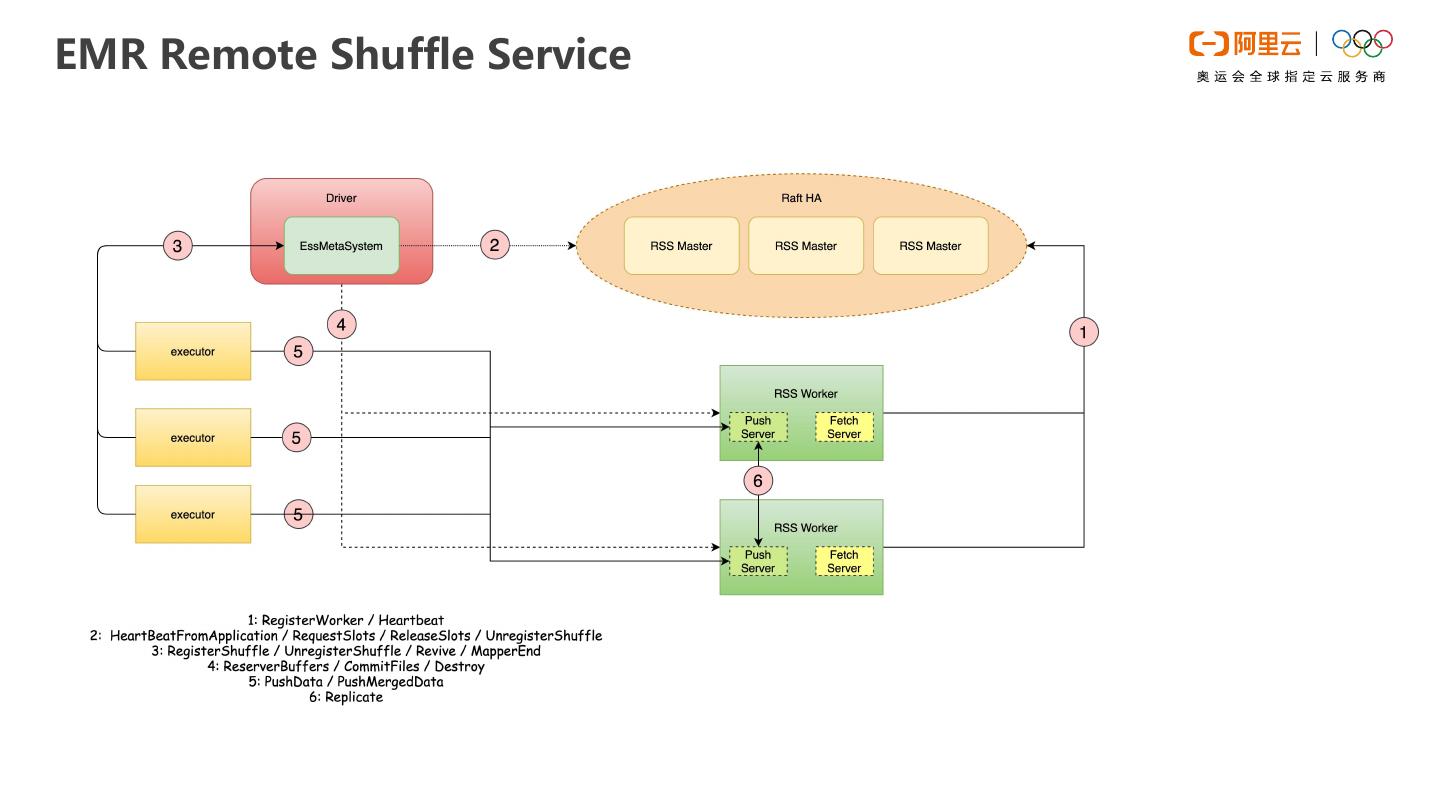
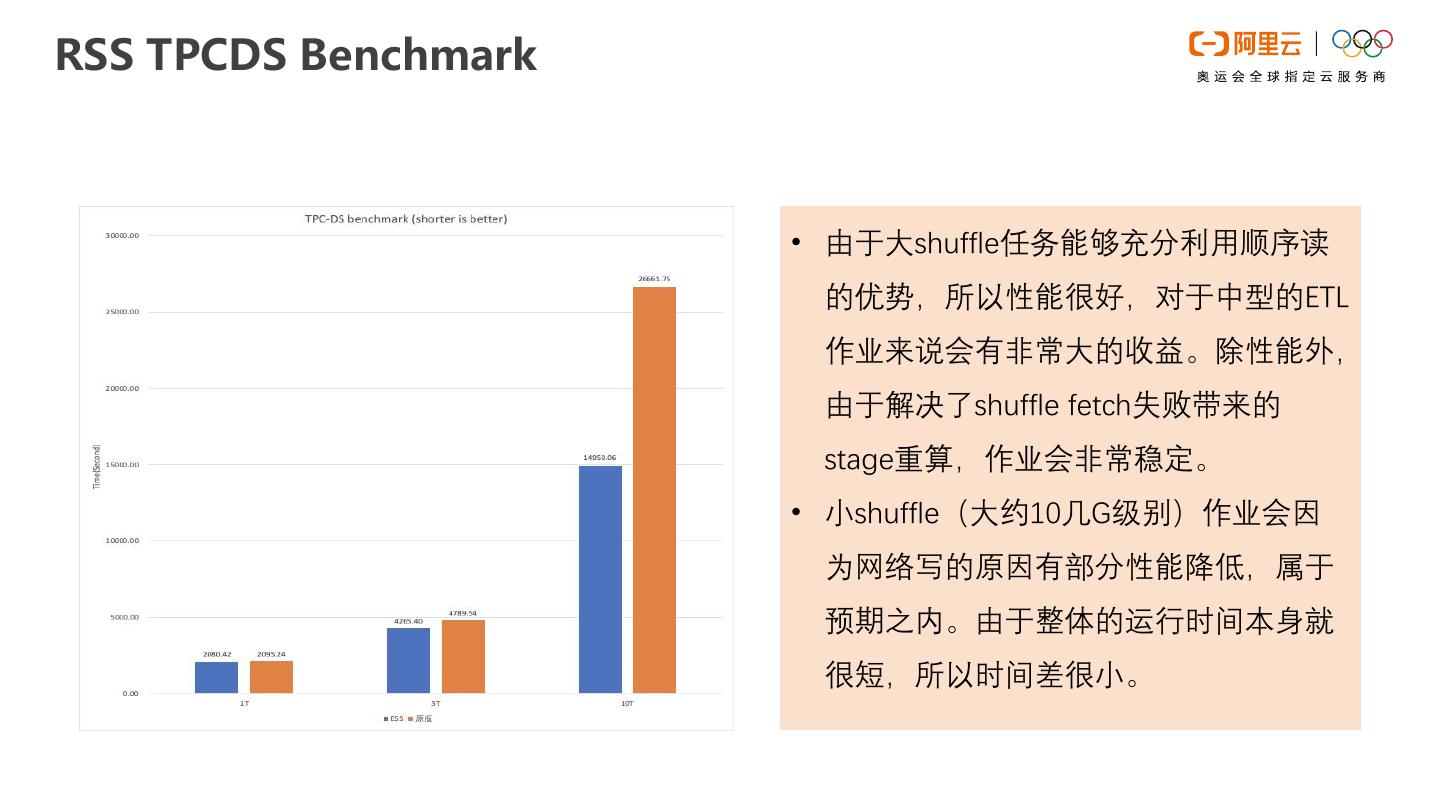
EMR Spark是运行在阿里云平台上的大数据处理解决方案。Spark on kubernetes时会面临shuffle的问题,针对相关问题,我们设计了shuffle读写分离的架构,称为Remote Shuffle Service,对现有的shuffle机制做了比较大的优化,解决了计算存储分离和混合架构下的shuffle稳定性和性能问题。本次直播将重点展开RSS的使用和性能展示。
枢木,阿里云开源大数据平台,高级开发工程师
3秒后跳转登录页面
去登陆

