展开查看详情
1 . Tablestore Spark Streaming Connector
海量结构化数据的实时计算和处理
阿里云存储服务技术专家 朱晓然
�
2 . 01 Tablestore 产品介绍和 CDC 技术
Contents
目录 02 Tablestore Tunnel 对接 Spark Streaming
03 大数据架构和场景
�
3 .Tablestore 的 CDC 技术
01
�
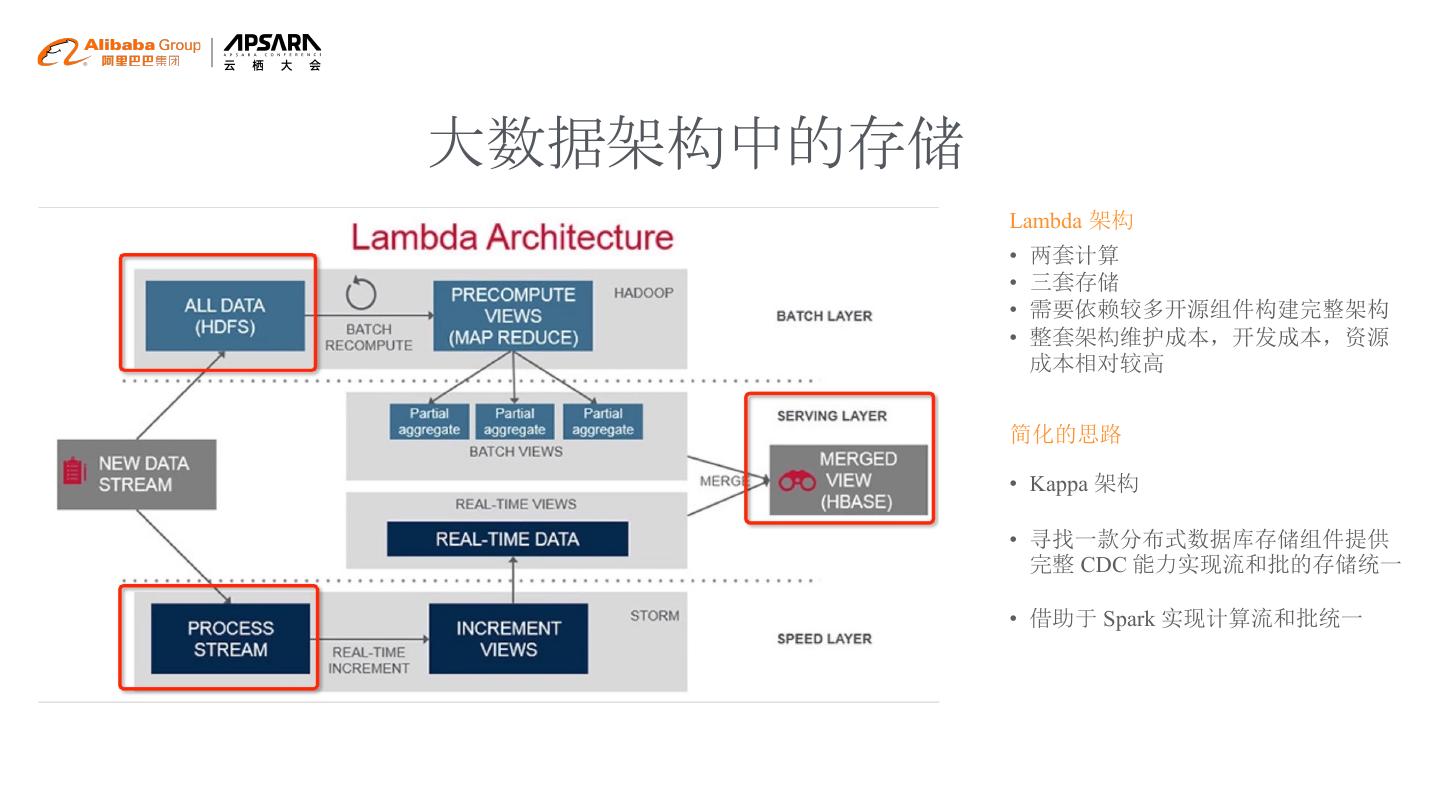
4 .大数据架构中的存储
Lambda 架构
• 两套计算
• 三套存储
• 需要依赖较多开源组件构建完整架构
• 整套架构维护成本,开发成本,资源
成本相对较高
简化的思路
• Kappa 架构
• 寻找一款分布式数据库存储组件提供
完整 CDC 能力实现流和批的存储统一
• 借助于 Spark 实现计算流和批统一
�
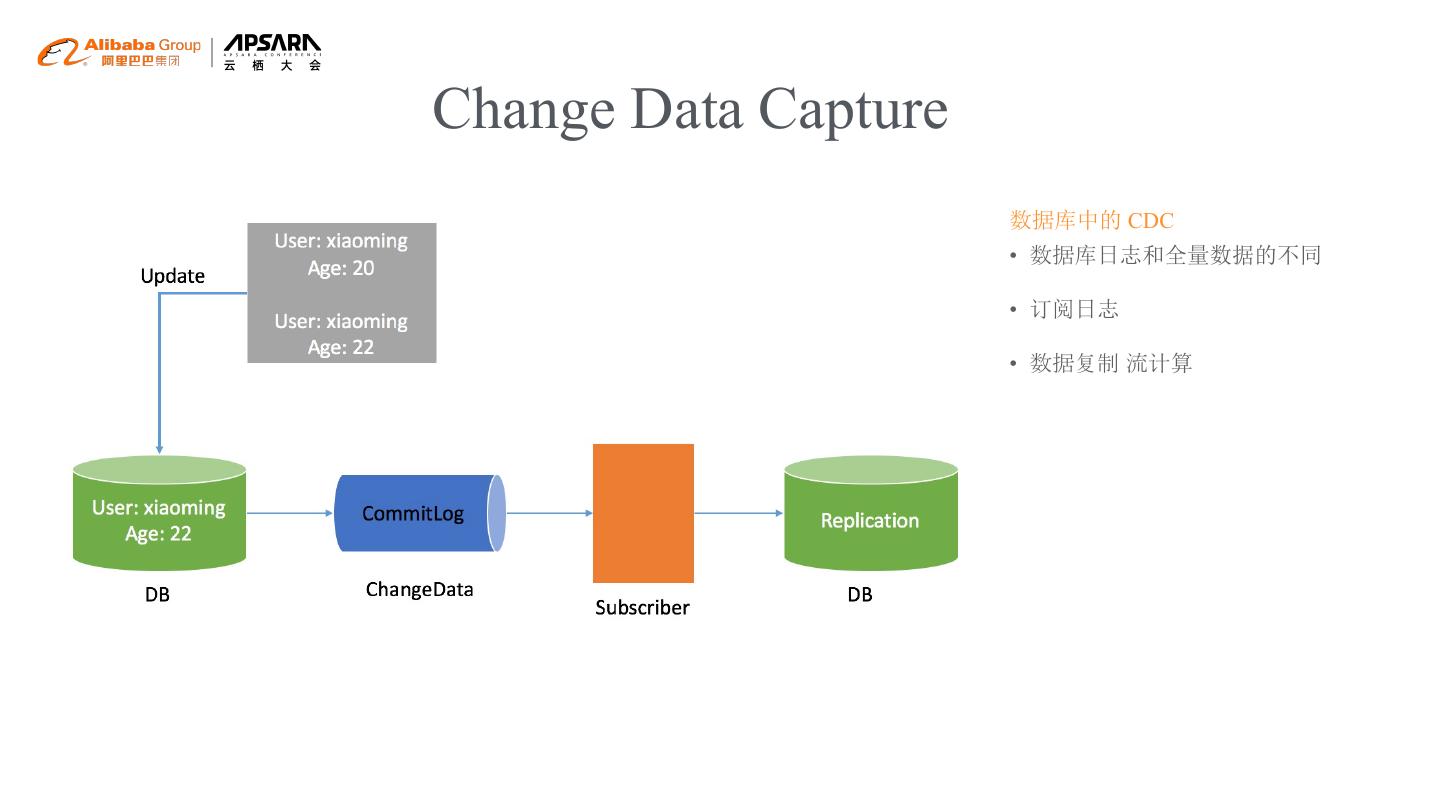
5 .Change Data Capture
数据库中的 CDC
• 数据库日志和全量数据的不同
• 订阅日志
• 数据复制 流计算
�
6 .Tablestore 结构化数据存储平台
分布式存储平台
• Bigtable 宽行模型
• 存储计算分离
• 实时变更捕获 (CDC)
• 灵活的数据与计算的上下游对接
支持混合负载的结构化数据存储
• 分布式架构,云原生 Serverless 产品形态
• 混合负载(HTAP):行列混存、多元化
索引
• 支持存储、查询、搜索和分析一体
完善的大数据生态对接
• 开源大数据和自研大数据完整的对接
• Spark Batch Source and Streaming Source
• Spark 批流 Sink 结果表
�
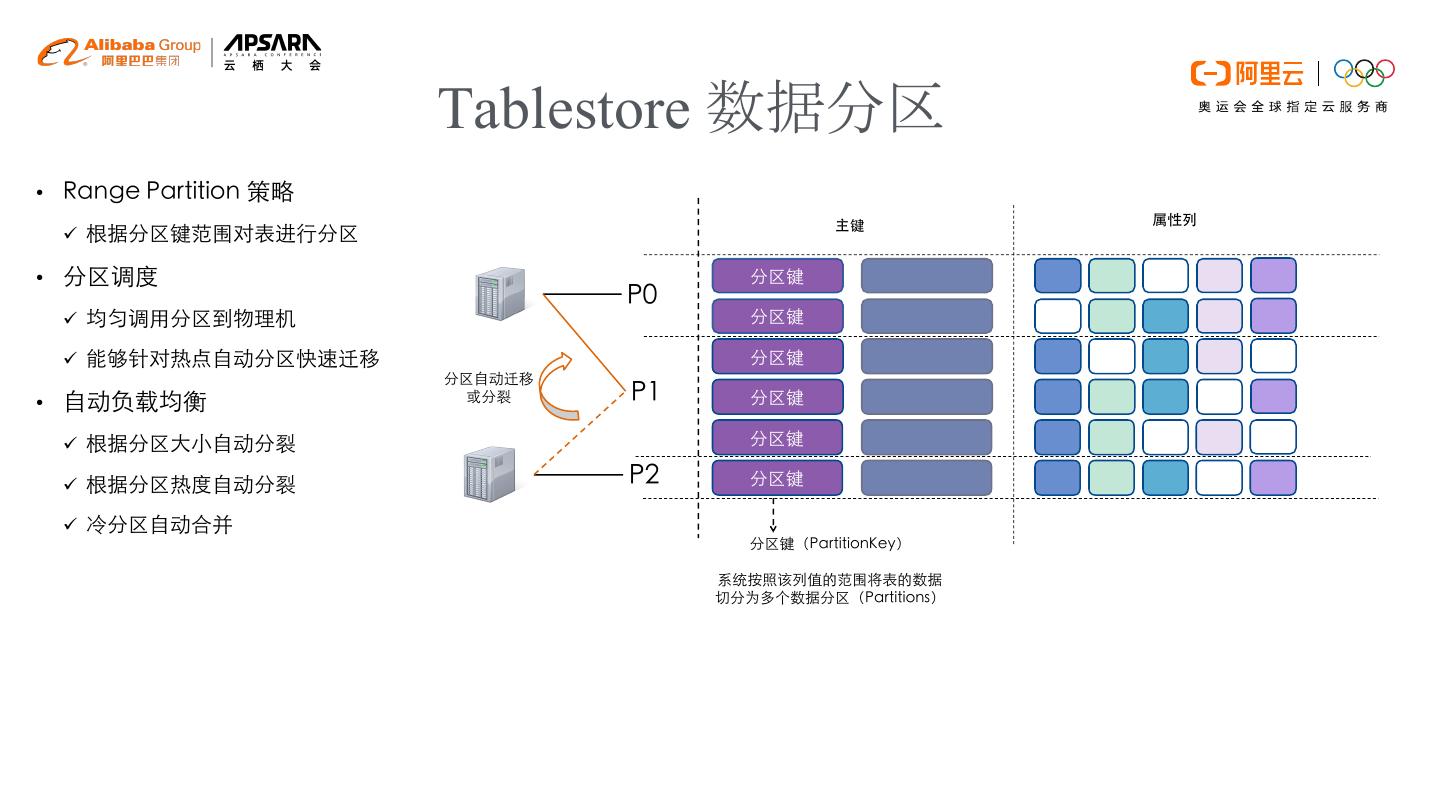
7 . Tablestore 数据分区
• Range Partition 策略
主键 属性列
ü 根据分区键范围对表进行分区
• 分区调度 分区键
P0
ü 均匀调用分区到物理机 分区键
ü 能够针对热点自动分区快速迁移 分区键
分区自动迁移
• 自动负载均衡 或分裂 P1 分区键
ü 根据分区大小自动分裂 分区键
ü 根据分区热度自动分裂 P2 分区键
ü 冷分区自动合并
分区键(PartitionKey)
系统按照该列值的范围将表的数据
切分为多个数据分区(Partitions)
�
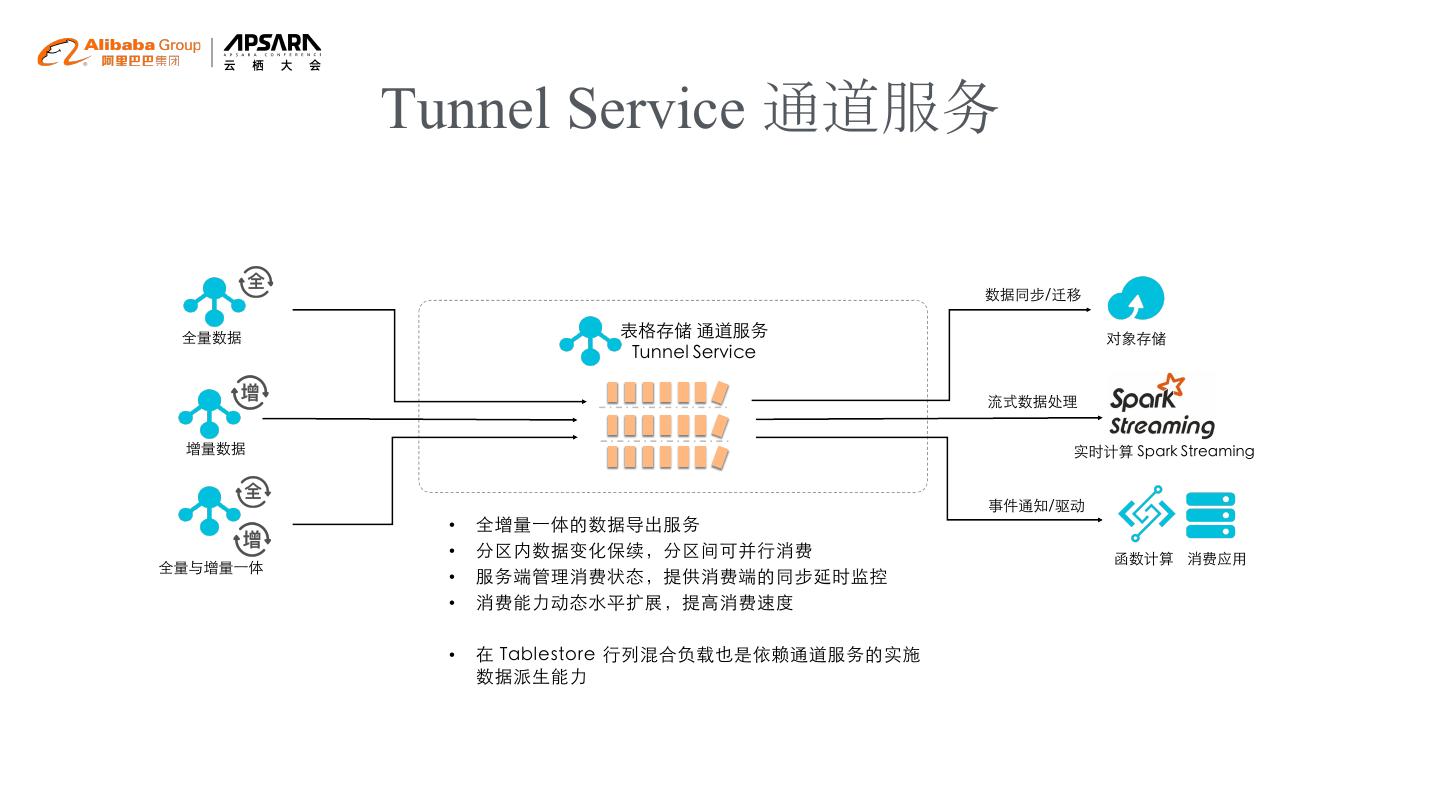
8 . Tunnel Service 通道服务
数据同步/迁移
全量数据 表格存储 通道服务 对象存储
Tunnel Service
流式数据处理
增量数据 实时计算 Spark Streaming
事件通知/驱动
• 全增量一体的数据导出服务
• 分区内数据变化保续,分区间可并行消费 函数计算 消费应用
全量与增量一体
• 服务端管理消费状态,提供消费端的同步延时监控
• 消费能力动态水平扩展,提高消费速度
• 在 Tablestore 行列混合负载也是依赖通道服务的实施
数据派生能力
�
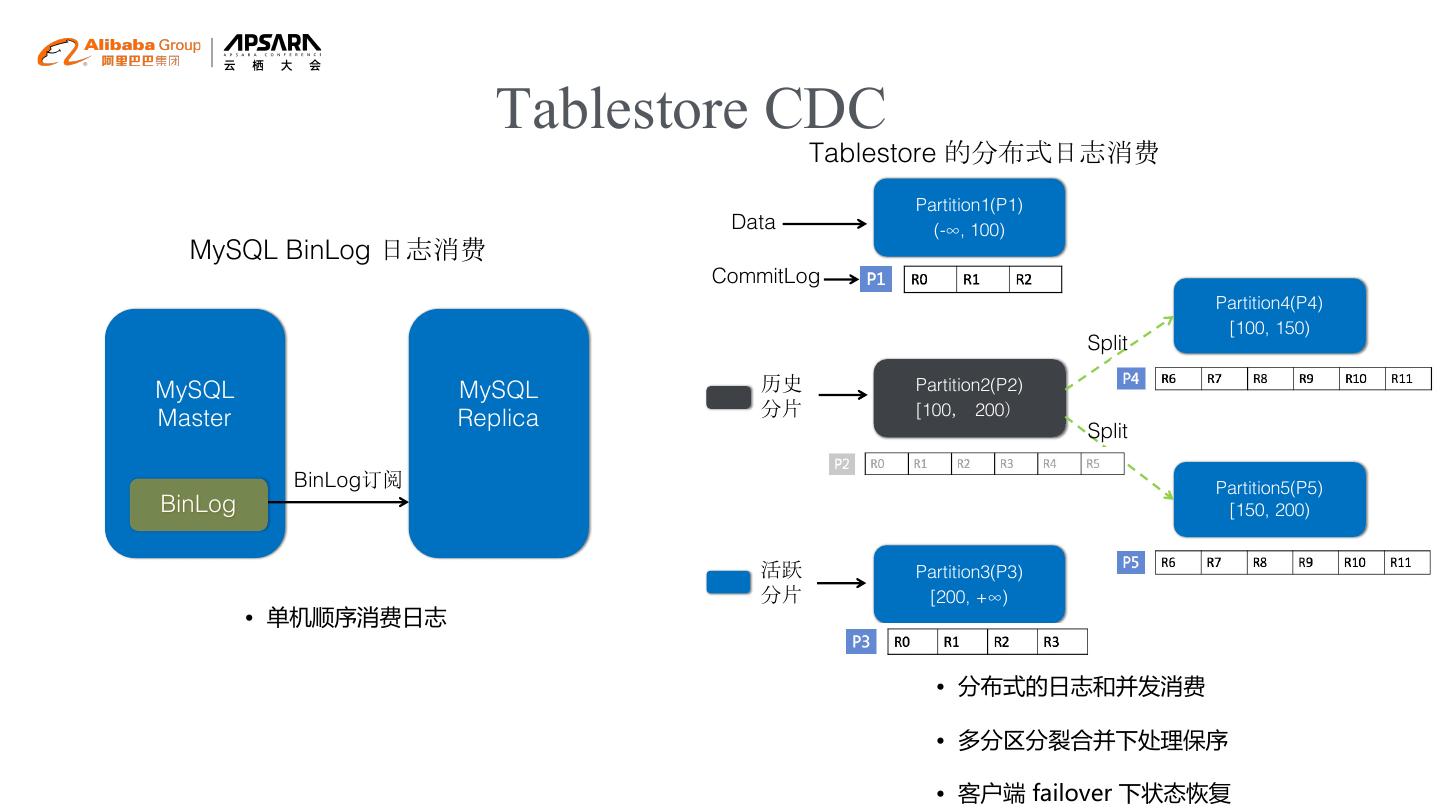
9 . Tablestore CDC
Tablestore 的分布式日志消费
Partition1(P1)
Data (-∞, 100)
MySQL BinLog 日志消费
CommitLog
Partition4(P4)
[100, 150)
Split
MySQL MySQL 历史 Partition2(P2)
Master Replica 分片 [100, 200)
Split
BinLog订阅 Partition5(P5)
BinLog [150, 200)
活跃 Partition3(P3)
分片 [200, +∞)
• 单机顺序消费日志
• 分布式的日志和并发消费
• 多分区分裂合并下处理保序
• 客户端 failover 下状态恢复
�
10 .Tablestore Tunnel 对接
Spark Streaming
02
�
11 . EMR Spark Connector
• Tablestore 和 Loghub 是做到同时支持批读写和流读写的产品
• Tablestore 是目前唯一一款实现 Connector 全面对接的数据库产品
�
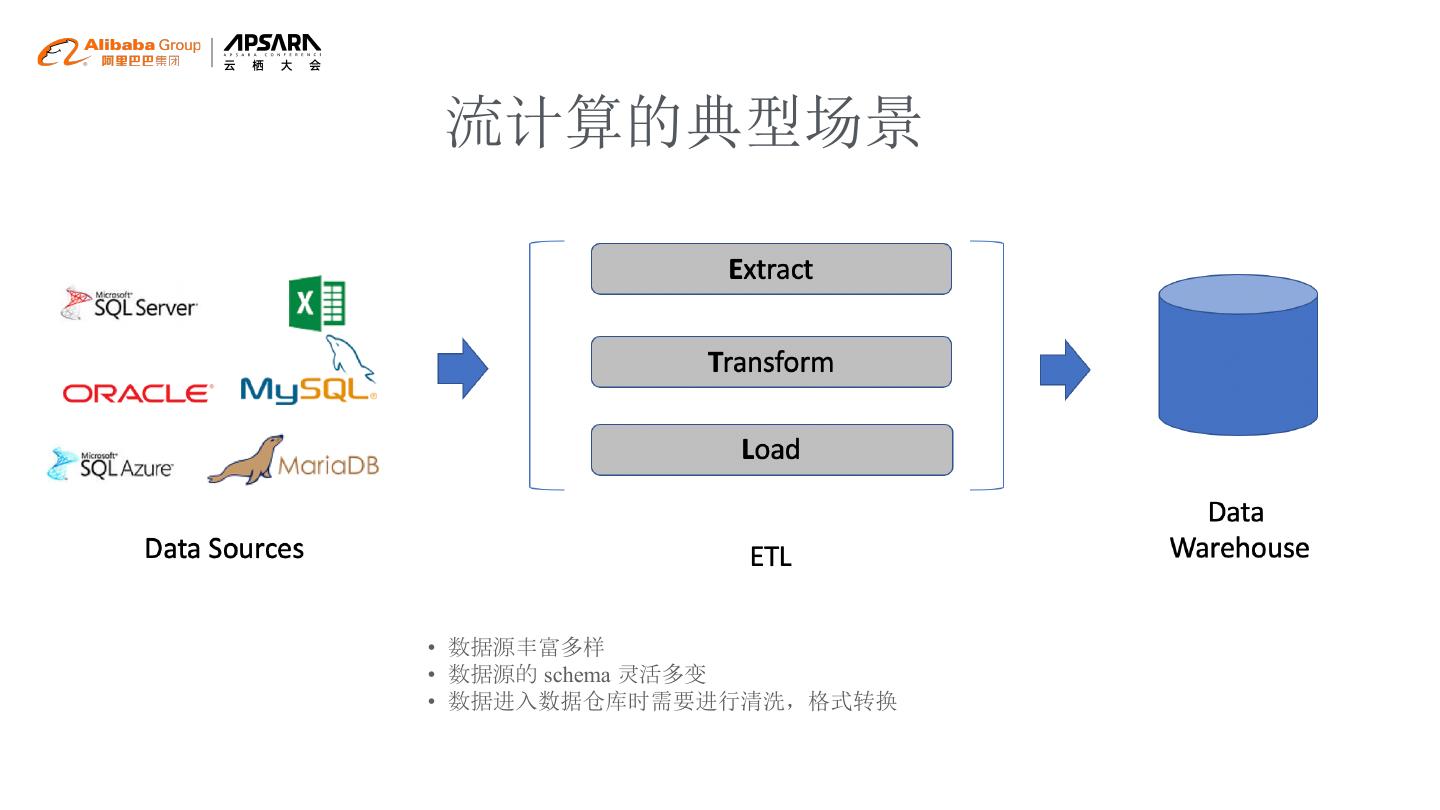
12 .流计算的典型场景
• 数据源丰富多样
• 数据源的 schema 灵活多变
• 数据进入数据仓库时需要进行清洗,格式转换
�
13 . Tablestore Tunnel Source Connector 对接流程
1. micro-batch 的模式
2. 在 GetOffset 过程中通过 Tunnel SDK 获取当前批次读需要处理的分区 Channel 列表
3. 每个 channel 关联一个 SparkRDD 中的 partition
4. 每个 partition 调用 Tunnel 的数据接口拉取数据,样例输出:
�
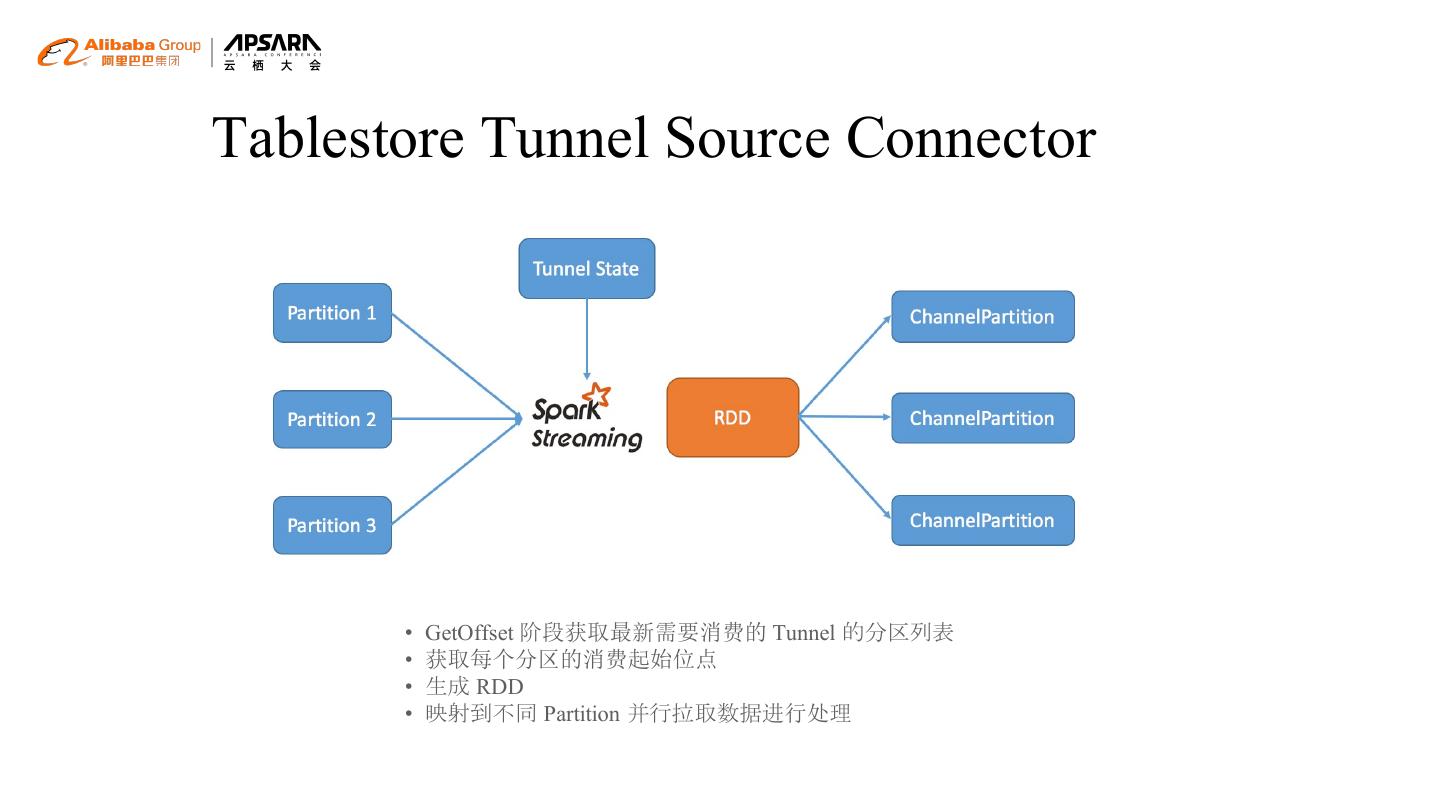
14 .Tablestore Tunnel Source Connector
• GetOffset 阶段获取最新需要消费的 Tunnel 的分区列表
• 获取每个分区的消费起始位点
• 生成 RDD
• 映射到不同 Partition 并行拉取数据进行处理
�
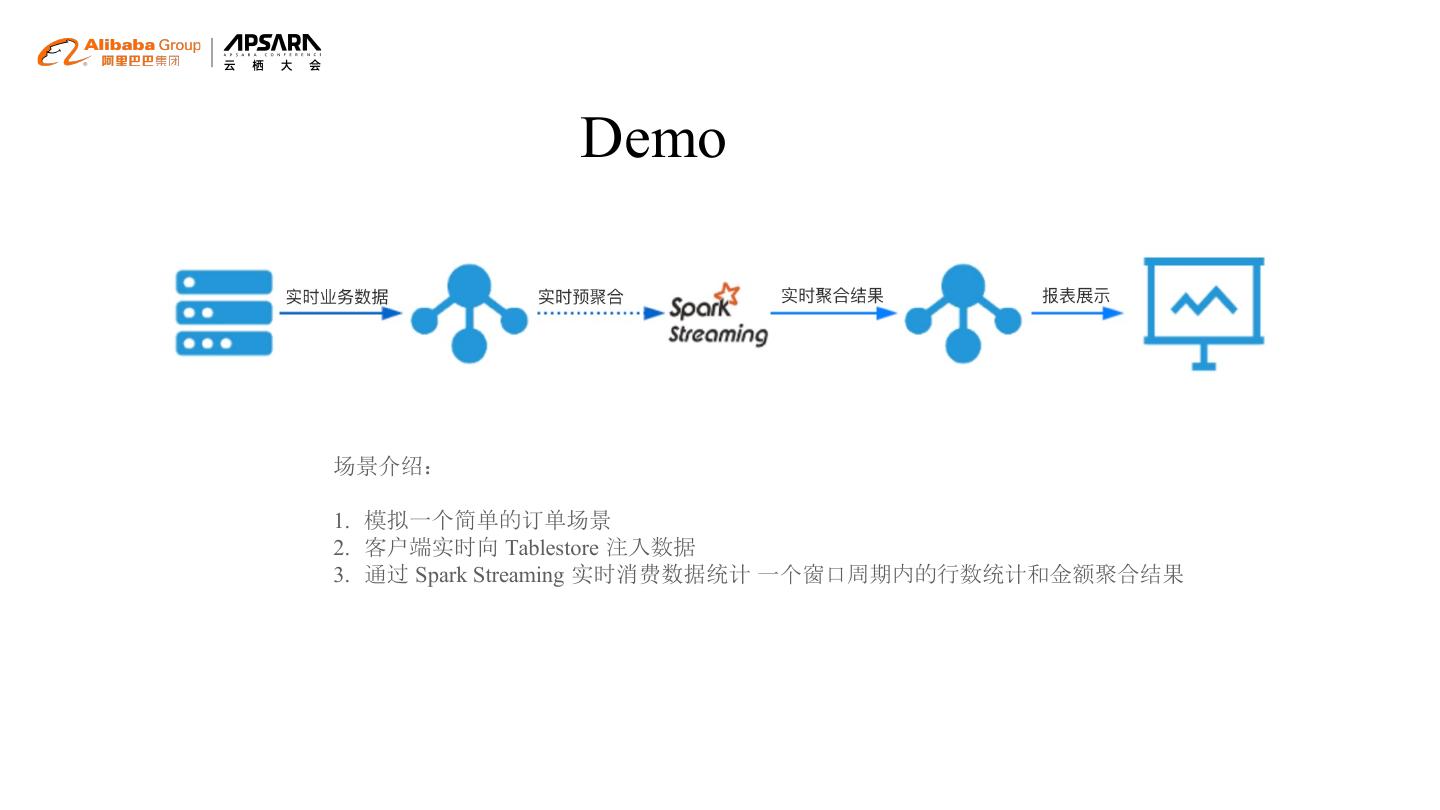
15 . Demo
场景介绍:
1. 模拟一个简单的订单场景
2. 客户端实时向 Tablestore 注入数据
3. 通过 Spark Streaming 实时消费数据统计 一个窗口周期内的行数统计和金额聚合结果
�
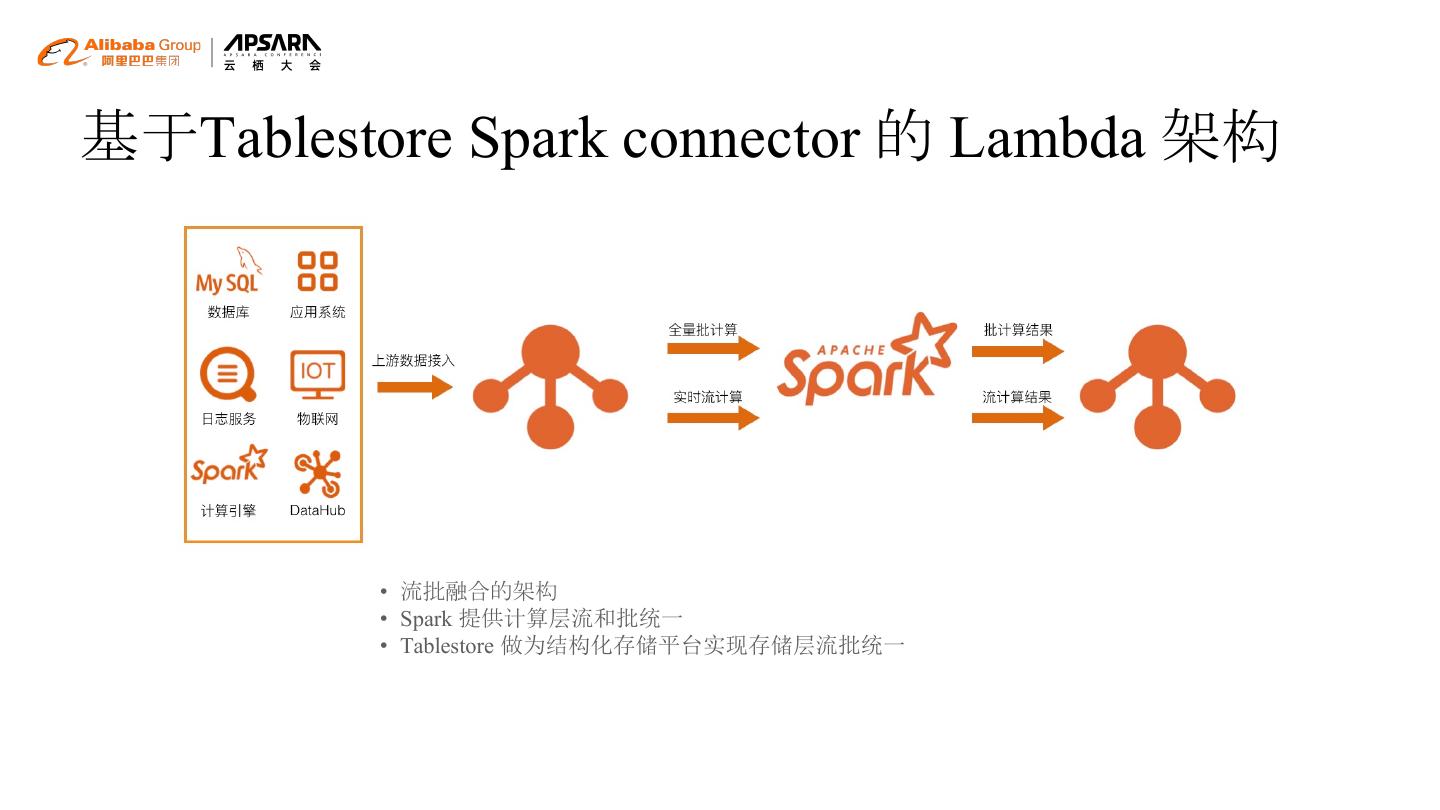
17 .基于Tablestore Spark connector 的 Lambda 架构
• 流批融合的架构
• Spark 提供计算层流和批统一
• Tablestore 做为结构化存储平台实现存储层流批统一
�
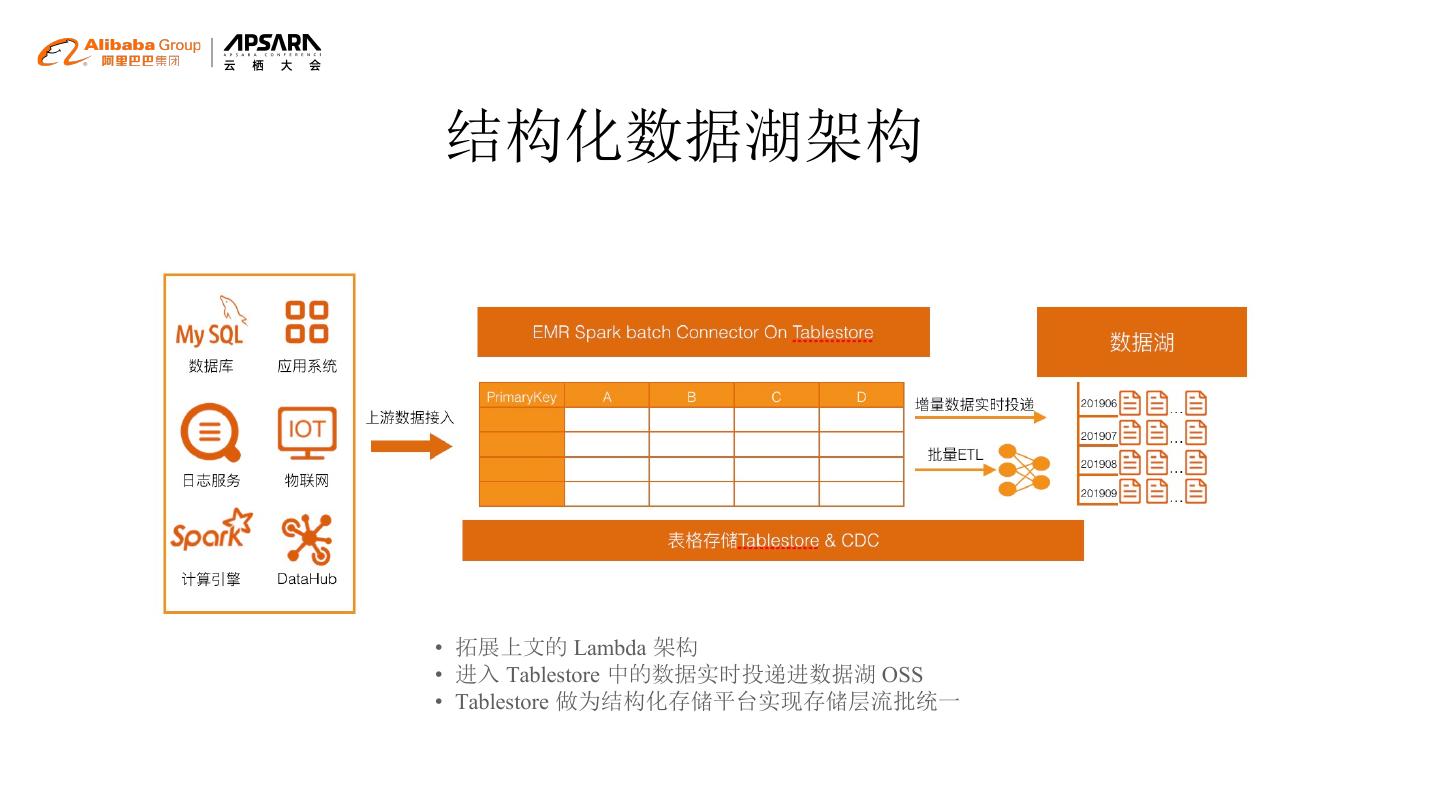
18 .结构化数据湖架构
• 拓展上文的 Lambda 架构
• 进入 Tablestore 中的数据实时投递进数据湖 OSS
• Tablestore 做为结构化存储平台实现存储层流批统一
�
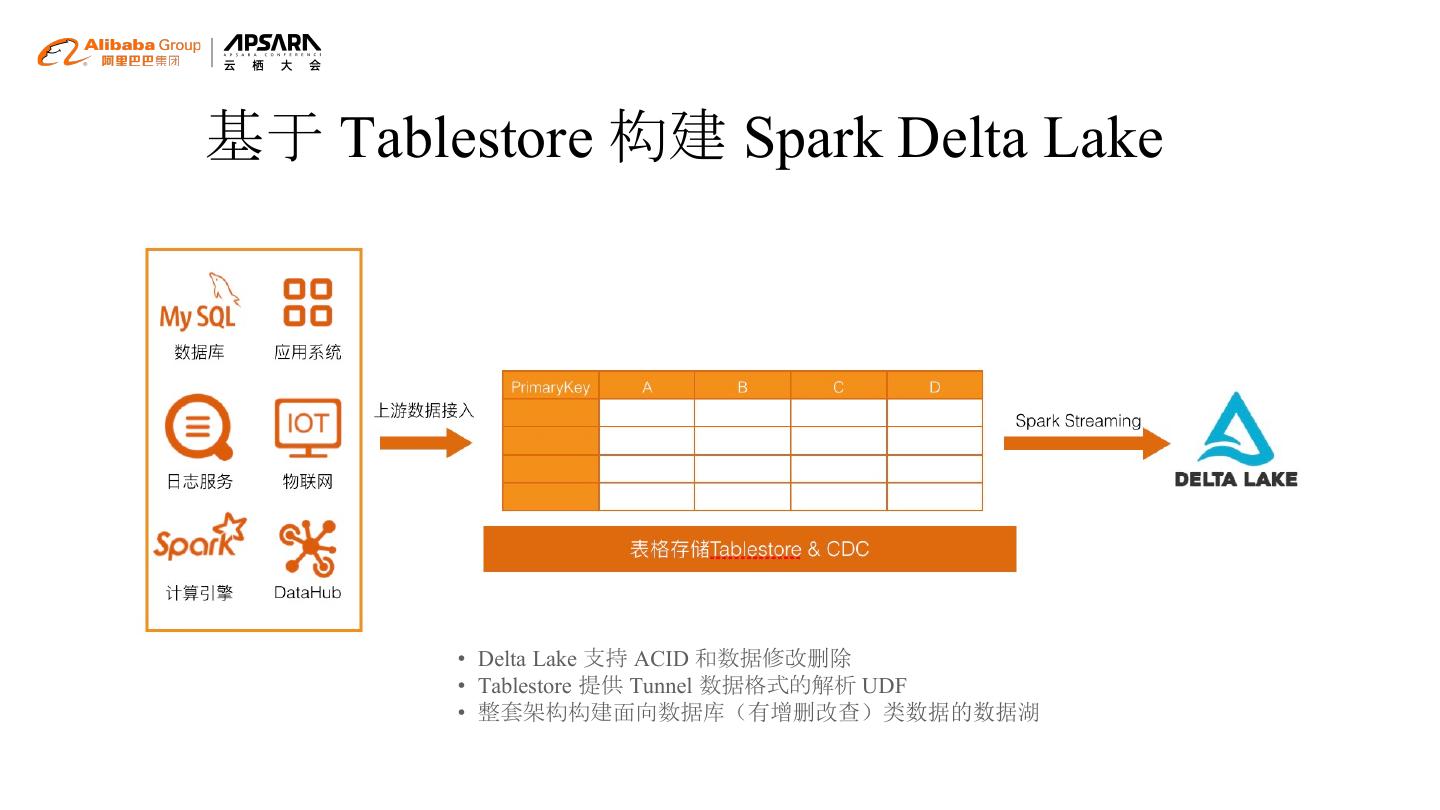
19 .基于 Tablestore 构建 Spark Delta Lake
• Delta Lake 支持 ACID 和数据修改删除
• Tablestore 提供 Tunnel 数据格式的解析 UDF
• 整套架构构建面向数据库(有增删改查)类数据的数据湖
�
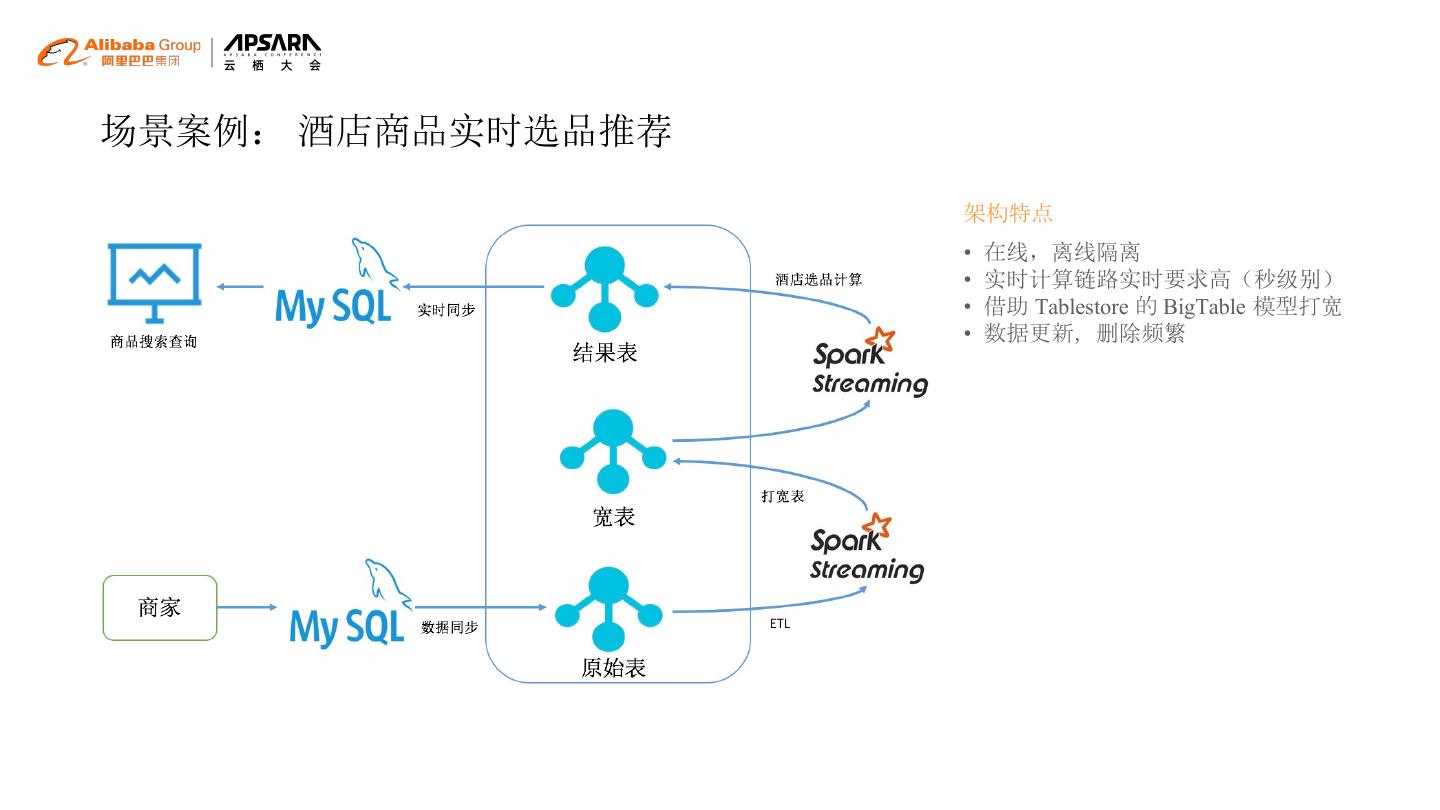
20 .场景案例: 酒店商品实时选品推荐
架构特点
• 在线,离线隔离
• 实时计算链路实时要求高(秒级别)
• 借助 Tablestore 的 BigTable 模型打宽
• 数据更新,删除频繁
�
21 .场景案例: 全网爬虫舆情系统
架构特点
• 数据存储海量,有批和流的需求
• 离线计算数据吞吐量大
• 在线离线混跑
• 数据源无需双写
• Spark Streaming Source 和 Sink 依赖
Tablestore
• 结果表利用 Tablestore 自身行列混合能力实
现交互查询,报表需求
• 舆情结果报警依赖 Tablestore Tunnel 事件编
程技术触发报警业务逻辑
�
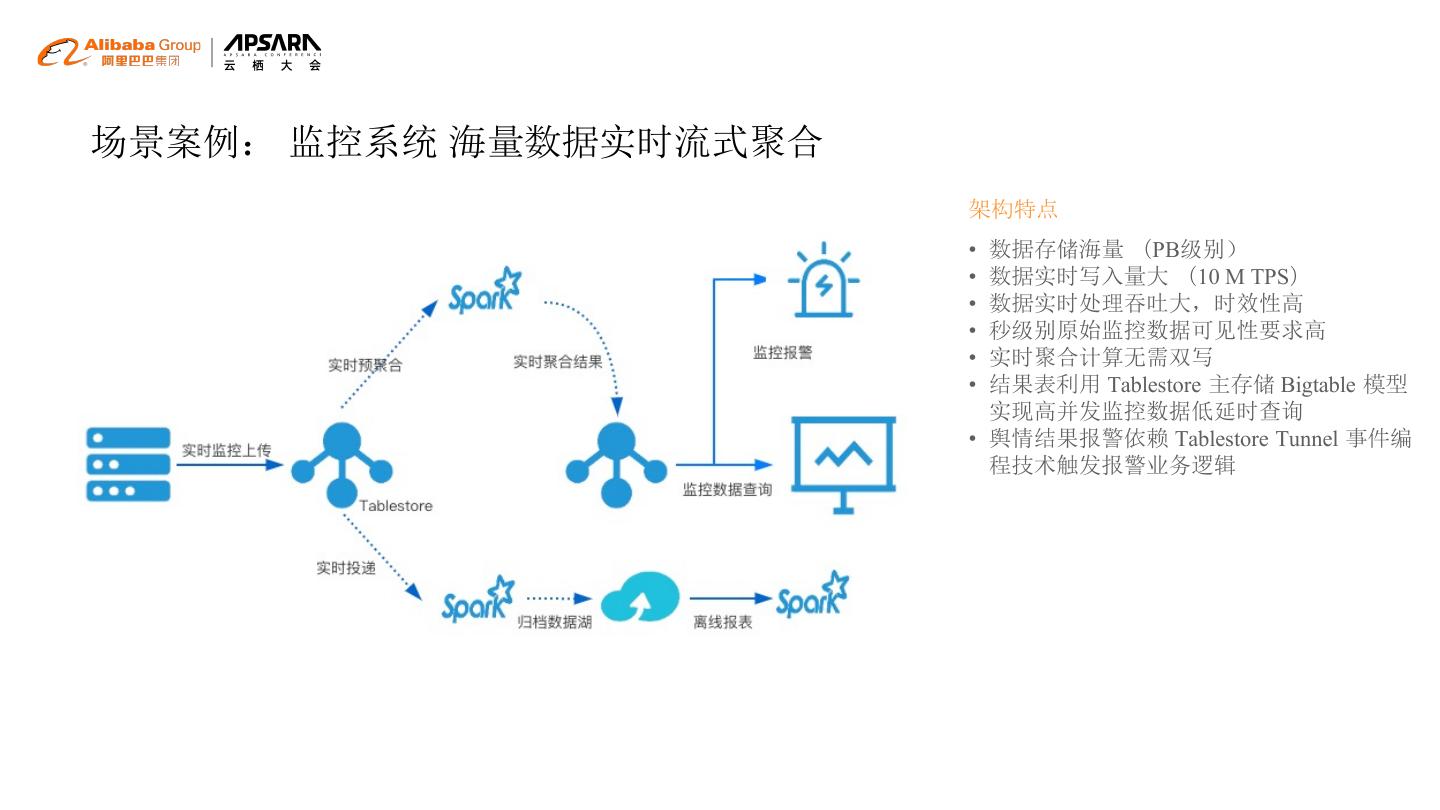
22 .场景案例: 监控系统 海量数据实时流式聚合
架构特点
• 数据存储海量 (PB级别)
• 数据实时写入量大 (10 M TPS)
• 数据实时处理吞吐大,时效性高
• 秒级别原始监控数据可见性要求高
• 实时聚合计算无需双写
• 结果表利用 Tablestore 主存储 Bigtable 模型
实现高并发监控数据低延时查询
• 舆情结果报警依赖 Tablestore Tunnel 事件编
程技术触发报警业务逻辑
�
23 .表格存储 Tablestore 结构化数据统一存储平台
表格存储技术交流群 Apache Spark 中国社区交流群
�