展开查看详情
1 .Toward Speech Large Language Model
for Zero-Shot Speech Synthesis and Translation
Shujie Liu Principal Research Manager in MSRA
1
�
2 .Speech Processing vs NLP
我 来自 中
国
MT
I am from
China
�
3 . GPT is hot, and LLM is used everywhere.
If we convert all the speech data to discrete
tokens, is it possible to train a speech version
GPT?
How to build the
token-based
How to convert What kind of data
speech
speech to tokens? we can use ?
processing
models?
�
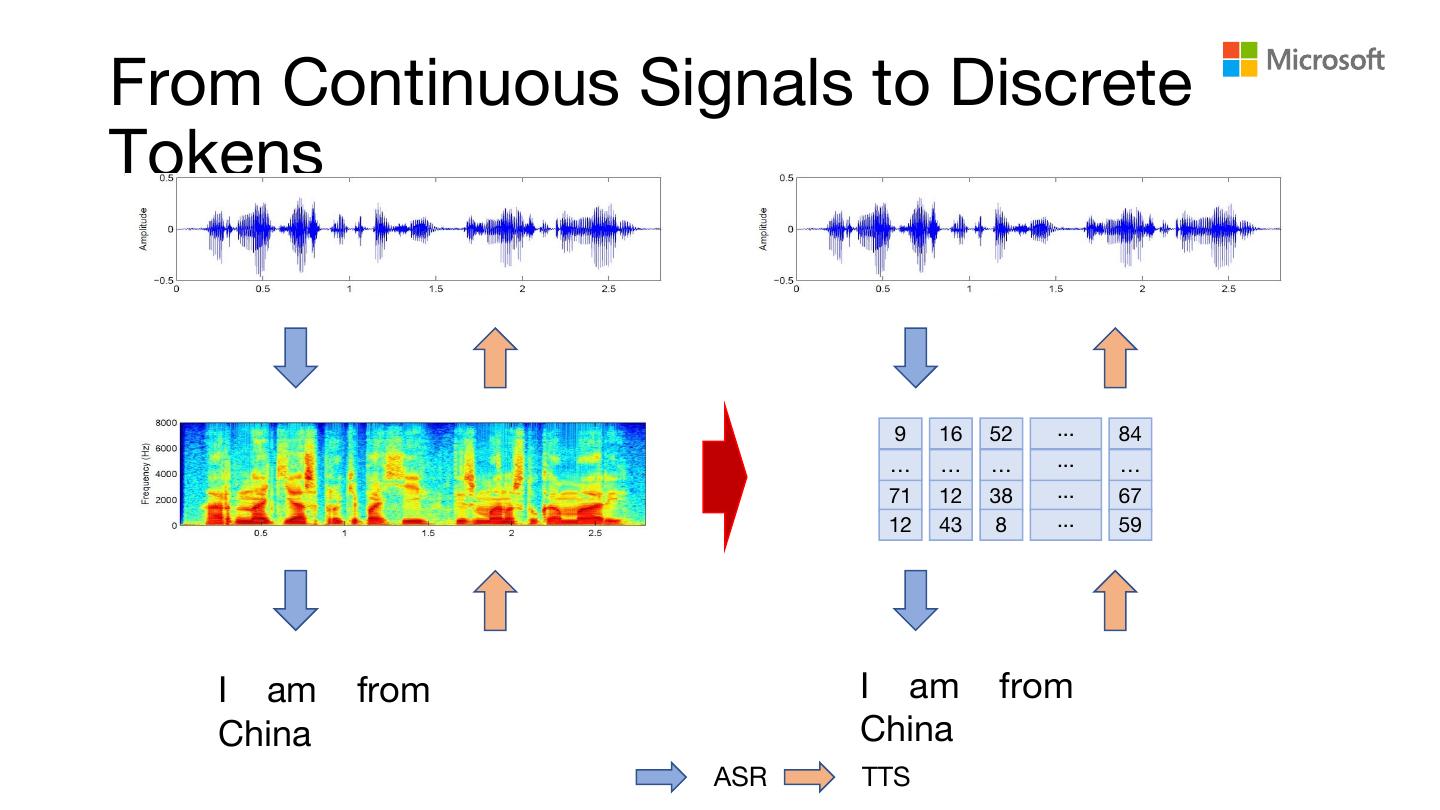
4 .From Continuous Signals to Discrete
Tokens
9 16 52 ... 84
… … … ... …
71 12 38 ... 67
12 43 8 ... 59
I am from I am from
China China
ASR TTS
�
5 .How to Convert Speech to Tokens?
+ + +
12 43 8 ... 59 71 2138 ... 67 9 1652 ... 84 Quantized
Tokens
stage 8 9 16 52 ... 84
...
Encoder
Decoder
VQ 8
VQ 2
VQ 1
...
stage 2 71 21 38 ... 67
- -
stage 1 12 43 8 ... 59
residual 1 residual 2 residual 7
Neural Audio Codec:
EnCodec
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, Yossi Adi. High Fidelity Neural Audio
�
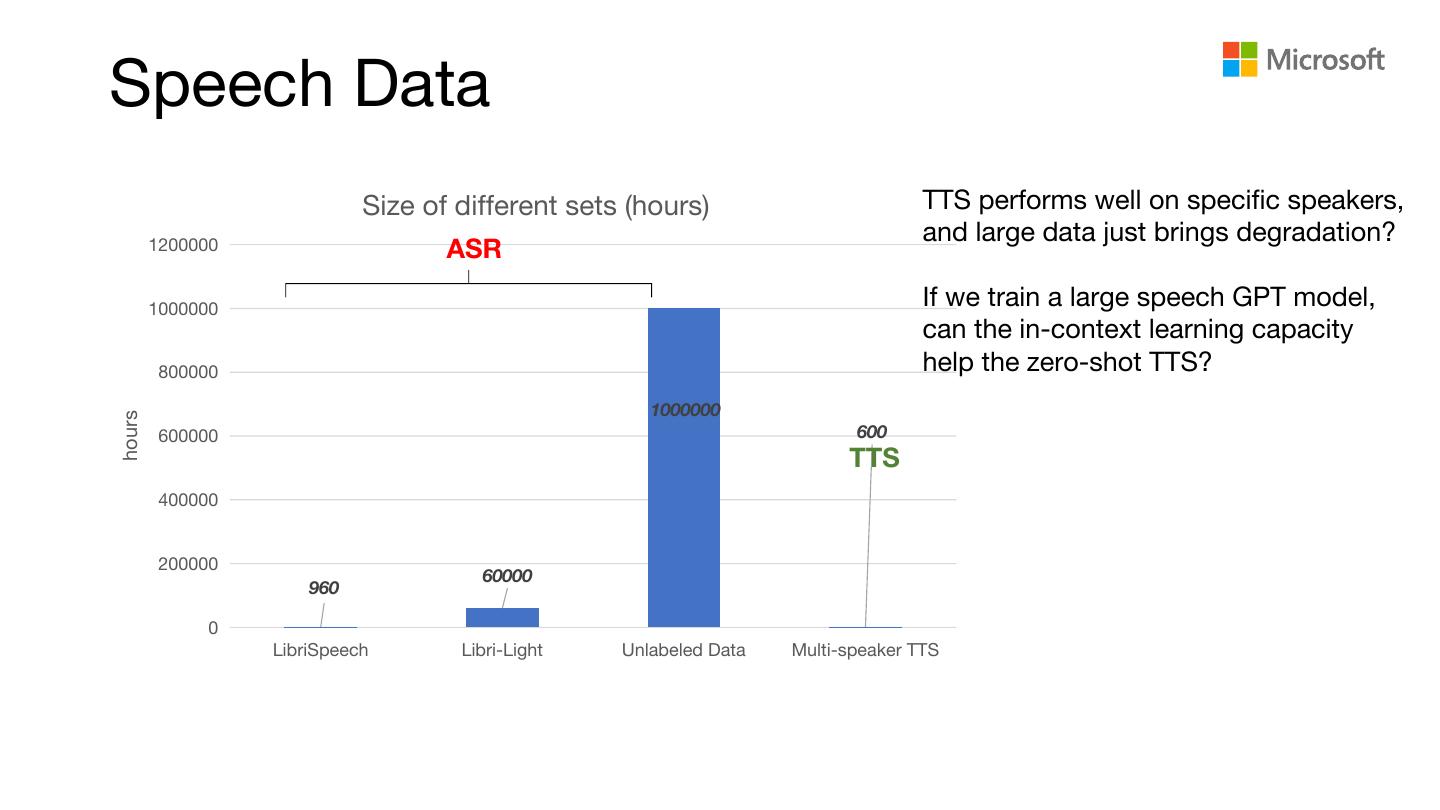
6 .Speech Data
Size of different sets (hours) TTS performs well on specific speakers,
and large data just brings degradation?
1200000 ASR
1000000 If we train a large speech GPT model,
can the in-context learning capacity
800000 help the zero-shot TTS?
1000000
hours
600000 600
TTS
400000
200000
60000
960
0
LibriSpeech Libri-Light Unlabeled Data Multi-speaker TTS
�
7 .Speech Model Size
GPT4
(1Trillion)
NLP models
GPT-3 (175B)
PaLM
(540B)
T5 (11B)
GPT-2 (1.5B) BigSSL (8B)
VALL-E (1B)
ELMo (M)
BERT-L (340M)
Traditional TTS
(<100M)
2018 2019 2020 2021 2022 2023
�
8 .Build a Speech Version of GPT: the first
try
• Discrete representations Neural Codec Codes (Encodec)
• Use large and diverse data Large ASR data (60K hours Librilight
Data)
• Large Transformer structure Decoder Only Network (1B)
• Focus on long-tail problems Zero-shot TTS /S2ST (Clone voice with
3s speech)
�
9 .VALL-E: Neural Codec Language
Modeling
Personalized
Speech
Audio Codec
Decoder
Neural Codec Language Modeling
Phoneme Audio Codec
Conversion Encoder
Text Acoustic
Prompt Prompt
Text for synthesis 3-second enrolled
recording
�
10 . Stage1: AR Transformer
��,� ��,� ��,� … <EOS
AR: �� only attends to left >
� � �� ��
� AR Transformer Decoder
�
�
��
G2P ��,� ��,� … ��′,� ��,� ��,� … ��,�
Text EnCodec
��
Allow attend Disallow attend
Conditional Codec Language Modeling
�
11 . Stage2: NAR Transformer
NAR: attend to all tokens ��,� ��,�
…
��,�
�−� �−�
� � �� ��
�
NAR Transformer Decoder
�
� �
�−�
�� G2P EnCodec ��,�:�−� ��,�:�−� … ��,�:�−�
�−� NAR ID �
��
Text
Prompt
�
12 .Experiment Setting
• Model
• Stage1 and Stage2: 12 layers 1024 hidden states Transformer
• Data
• Libri-Light 60k hours with 7000 speakers
• Training
• 16 V100(32GB)
• Batch size of 6k acoustic tokens per GPU
• 800k steps for 5 days
• Latency (Real Time Factor)
• A100: RTF = 0.5
• V100: RTF = 1.0
�
13 .Experiment Results (LibriSpeech)
Automatic Evaluation Human Evaluation
�
15 . Zero-shot TTS Examples
Prompt VALL-E
Anger
Sleepy
Cat
Dog
Cat is a girl. Dog is a
boy.
�
16 .Audio Book for Reid Hoffman
VALL-E
Reid Hoffman
https://www.reidhoffman.org/ai-voice-synthesis-
tech-impromptu/
�
17 .VALL-E X: Cross-Lingual Neural Codec Language
Model
�
19 .Experiment Results (Cross-Lingual TTS)
Automatic Evaluation
Human Evaluation
EMIME Dataset
�
20 .Zero-shot Cross-lingual TTS Examples
Emotion English Prompt VALL-E X Emotion Chinese Prompt VALL-E X
Ange Angry
r
Amused Happy
Sleepines Surprise
s
Disgus Sad
t
Neutral Neural
English Chinese Chinese English
�
21 .Experiment Results (Language ID)
Chinese Speech with English
English Prompt Chinese Speech with Chinese ID
ID
Foreign Acescent
�
23 .Speech LLM
Text Speech
Detokenizer Detokenizer
Speech LLM
Speech Text • Tokenizers to map speech and text into one semantic
Tokenizer Tokenizer space
• Detokenizers to construct the speech and text
• Decoder only network for multi-modal LLM modeling
• Can leverage pre-trained LLMs such as LLAMA
�
24 .VioLA: A Unified Model for ASR, MT, TTS
and ST
�
25 .Results of S2ST
Source Target Speech (VioLA)
Speech
请允许我标记出一些观点 PLEASE ALLOW ME TO MARK SOME
VIEWS
我们拒绝这项社会不认可的改革 WE REJECT THIS SOCIALLY UNACKNOWLEDGED
REFORM
�
26 . Demo
Source Video VioLA
�
27 .Summary
• Regarding similarity, VALL-E X outperforms other methods significantly, even parity with
ground-truth, with large ASR data.
• VoiLA extends VALL-E X to build one unified model for ASR, MT and TTS, significantly
improve the performance for zero-shot speech to speech translation.
• Codec based decoder only pre-training opens a new door for speech processing, may
be applied to any speech processing tasks, including ASR, enhancement, voice
conversion, etc.
• Is it possible to convert all the different modalities to sequences of tokens and train one
GPT model?
https://www.microsoft.com/en-us/research/project/vall-e-
x/overview/
�