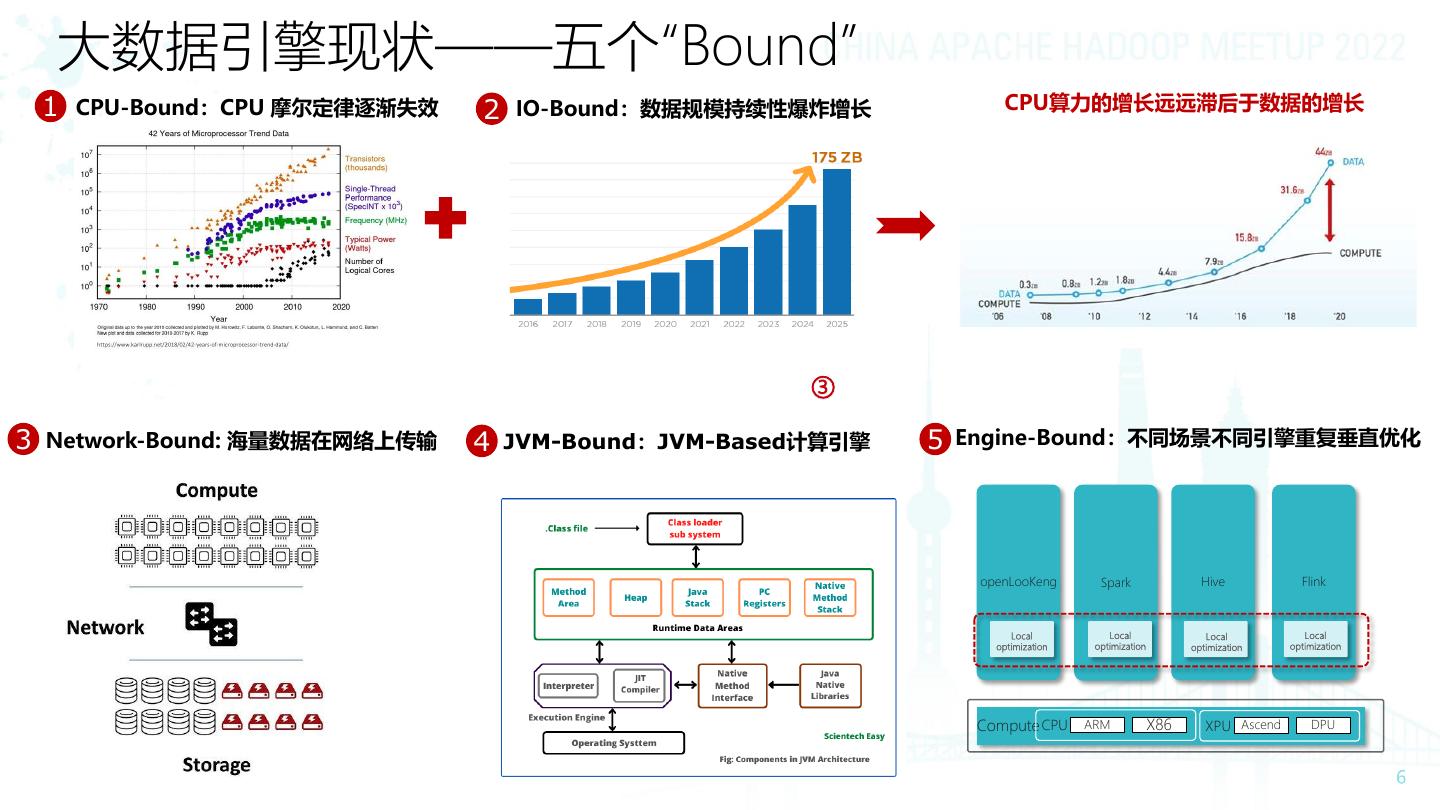
6 . 大数据引擎现状——五个“Bound”
1 CPU-Bound:CPU 摩尔定律逐渐失效 2 IO-Bound:数据规模持续性爆炸增长 CPU算力的增长远远滞后于数据的增长
③
3 Network-Bound: 海量数据在网络上传输 4 JVM-Bound:JVM-Based计算引擎 5 Engine-Bound:不同场景不同引擎重复垂直优化
openLooKeng Spark Hive Flink
Local Local Local Local
optimization optimization optimization optimization
Compute CPU ARM X86 XPU Ascend DPU