
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Gluten: 将Spark SQL性能翻一倍!-周渊

周渊-Intel软件开发经理
Intel亚太研发大数据分析组研发负责人,具有十多年大数据研发经验,深度参与了Spark原生执行引擎从0到1的开发过程,在客户端有丰富的Spark落地实践经验。
分享介绍:
Spark经过多年发展,作为基础的计算框架,不管是在稳定性还是可扩展性方面,以及生态建设都得到了业界广泛认可。为了更好提升Spark性能,我们开发了gluten项目来通过原生算子加速Spark应用性能。Gluten是一个开源项目,目前已经有多个业界的公司来合作开发,包括Intel, Kyligence, BigO, Meituan, Alibaba cloud, Netease, Baidu, Microsoft等。通过对接gluten对接的原生执行引擎,Spark集群这里的CPU利用率可以得到极大提升,从而取得高达8x的提速。
展开查看详情
1 .Gluten: Plugin to Double SparkSQL's Performance Yuan Zhou – Engineer Manager @ Intel
2 .LEGAL DISCLAIMERS Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at [intel.com]. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks. Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Consult other sources of information to evaluate performance as you consider your purchase. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks Cost reduction scenarios described are intended as examples of how a given Intel- based product, in the specified circumstances and configurations, may affect future costs and provide cost savings. Circumstances will vary. Intel does not guarantee any costs or cost reduction. Results have been estimated or simulated using internal Intel analysis or architecture simulation or modeling, and provided to you for informational purposes. Any differences in your system hardware, software or configuration may affect your actual performance. Intel does not control or audit third-party benchmark data or the web sites referenced in this document. You should visit the referenced web site and confirm whether referenced data are accurate. Intel processors of the same SKU may vary in frequency or power as a result of natural variability in the production process. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps. No computer system can be absolutely secure. Intel, the Intel logo, Xeon, Intel vPro, Intel Xeon Phi, Look Inside., are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others. Microsoft, Windows, and the Windows logo are trademarks, or registered trademarks of Microsoft Corporation in the United States and/or other countries. © 2023 Intel Corporation. 2
3 .Agenda • Why Spark with Native SQL Engine? • Gluten Introduction • Performance Result • Lessons learned on engineering work and customer landing • Roadmap & Future Works
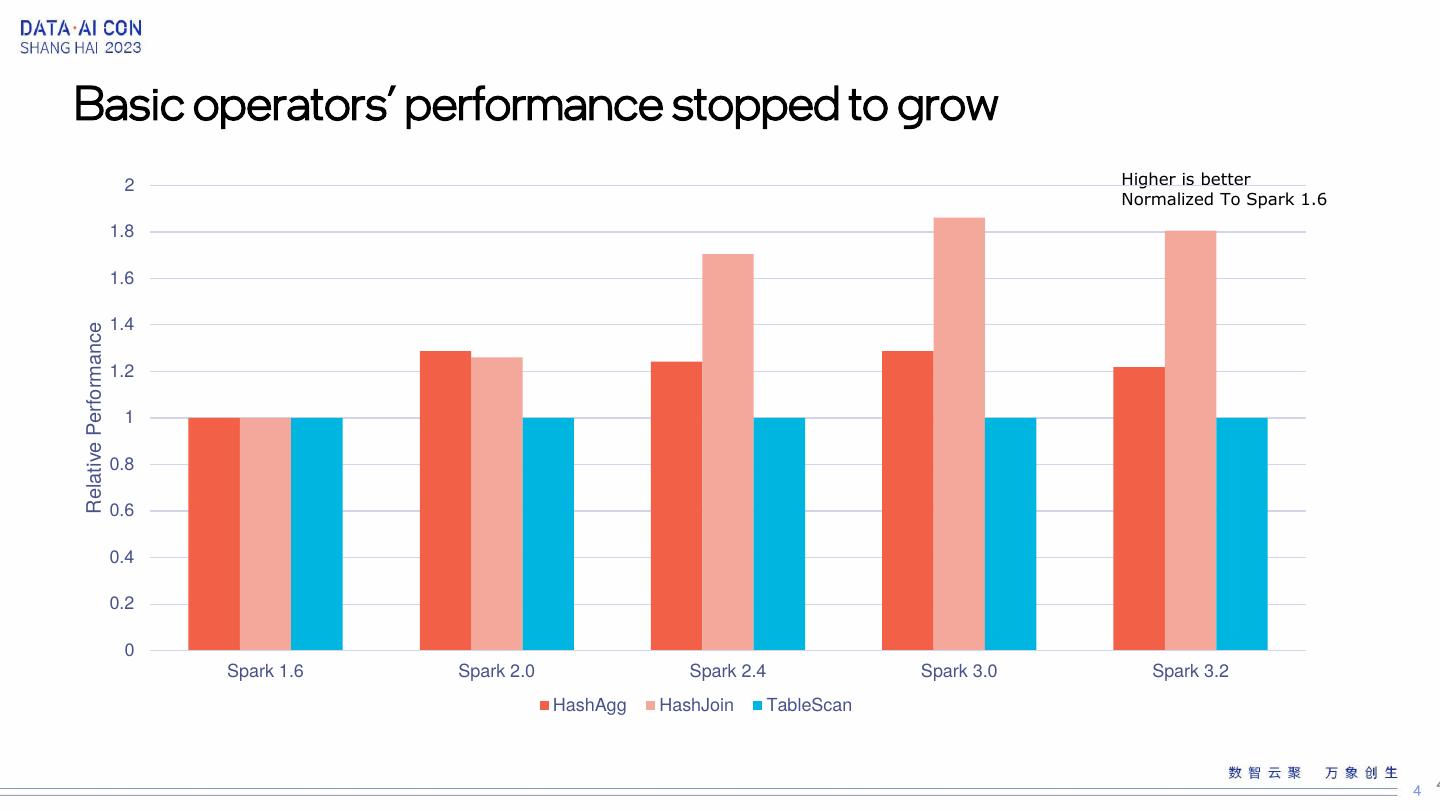
4 .Basic operators’ performance stopped to grow 2 Higher is better Normalized To Spark 1.6 1.8 1.6 1.4 Relative Performance 1.2 1 0.8 0.6 0.4 0.2 0 Spark 1.6 Spark 2.0 Spark 2.4 Spark 3.0 Spark 3.2 HashAgg HashJoin TableScan 4
5 .Cpu has become the bottleneck Node: 3 Disk: 4 x INTEL SSDPE2KE016T8 CPU: 2 x 36C Intel(R) Xeon(R) Platinum 8360Y 3.5GHz NIC: 25Gbps Memory: 512GB DDR4 Dataset: 3T
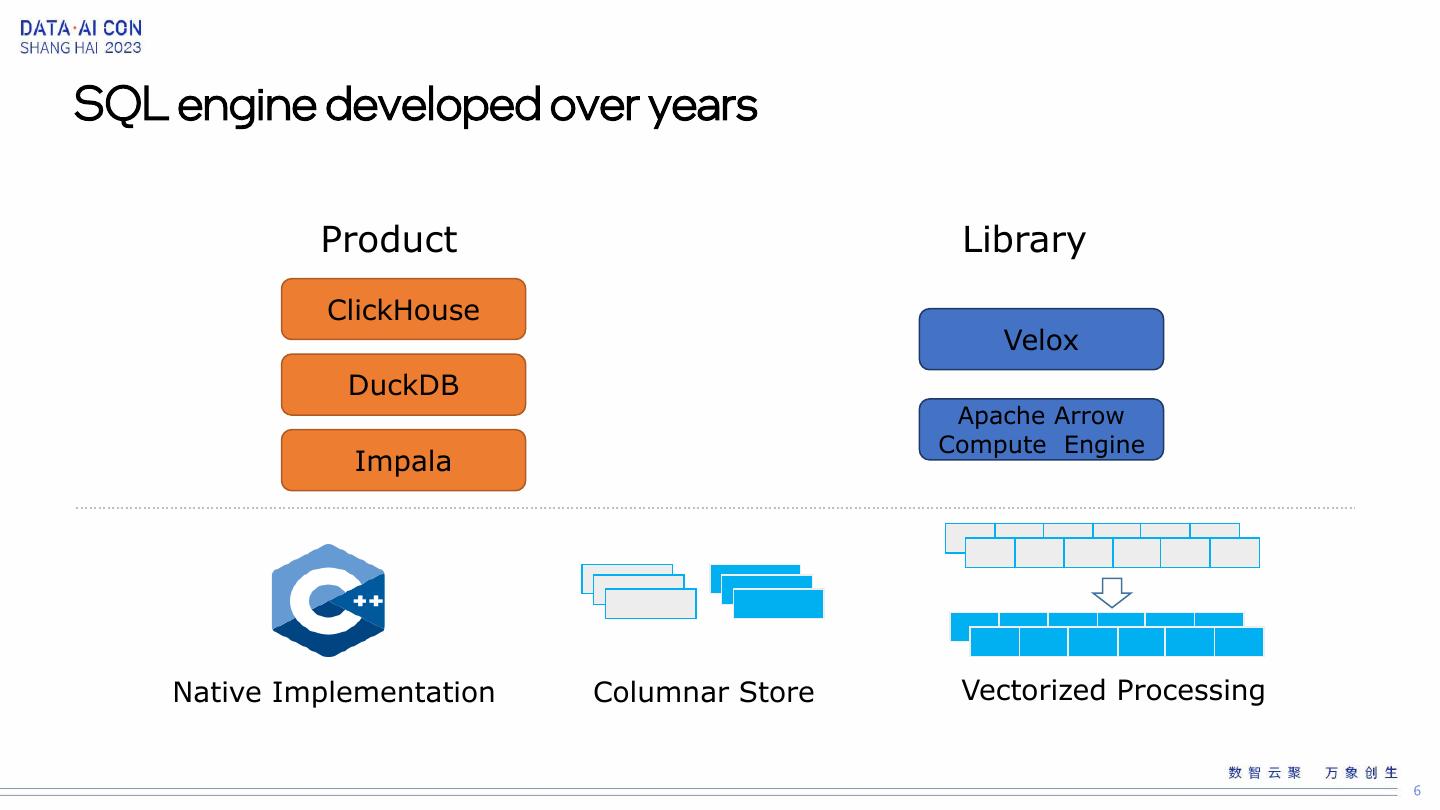
6 .SQL engine developed over years Product Library ClickHouse Velox DuckDB Apache Arrow Compute Engine Impala Native Implementation Columnar Store Vectorized Processing
7 .DBX Photon https://www.databricks.com/product/photon
8 .Gluten • Initiated by Intel and Kyligence, open-source project, to be contributed to Apache project • 10+ companies, 80+ contributors. • Actively contributed by Alibaba Cloud, Baidu, Bytedance, BigO, Meituan, Microsoft, NetEase, etc. • Transform Spark’s whole stage physical plan to Substrait plan and to execute w/ native engine • Offload performance critical data processing to native library • Reuse Spark’s distributed control flow • Manage data sharing between JVM and native, define clear JNI interfaces for native libraries • Switch the native backends easily, extend support to native accelerators
9 .Gluten framework Spark Physical Plan Columnar Vector Gluten Plugin Substrait Substrait Substrait Substrait Arrow + FPGA/GPU/ASIC Velox ClickHouse Gazelle Accelerators Reference: 1. Gluten: https://github.com/oap-project/gluten 2. Velox: https://github.com/facebookincubator/velox 3. Clickhouse: https://github.com/Kyligence/ClickHouse forked from https://github.com/ClickHouse/ClickHouse 4. Gazelle: https://github.com/oap-project/gazelle_plugin 5. Apache Arrow: https://github.com/apache/arrow 6. Substrait: https://substrait.io/ 9
10 .Gluten components DataFrame Catalyst Query Plan Optimization Tungsten Physical Plan Execution JVM SQL Engine Gluten Plugin Plan Memory Columnar Expression Shim Layer Fallback Metric JIT Conversion Mgr. Shuffle Operators Whole Stage Code Gen Native Library 1 0
11 . Gluten plan conversation Schema SQL Catalog Rules Cost Model Unresolved Optimized Physical Physical Spark DataSet Logical Plan Physical Plan Logical Plan Logical Plan Plan Plan Physical Plan DataFram e Spark “Substrait: A well-defined, cross-language specification for data compute Substrait Plan operations.” https://substrait.io/ Gluten Native Accelerator Library Pipeline in Library A Pipeline in Library B Scan Filter Project Aggregate Scan Filter Project Aggregate Join Join f f f f f Σ f Σ 1 1
12 .Gluten buffer passing & sharing Lib Velox Vector ArrowColumnarVector Lib ClickHouse Vector Column Column Column Column Column Column C Data Struct JVM Array Array Native Export as Native Batch Export as Native Batch Library Velox Library ClickHouse Batch Batch Column Column Column Column Export as Arrow 1 2
13 .Gluten fallback processing • Replace Spark physical plan by Transformers • Unsupported operators with express will fallback to Vanilla Spark • Combining several operators into WholeStageTransformer to generate whole stage substrait plan Validate Succeed, Native computing Validate Succeed Validate Fail Native computing Spark computing CondProjectTransformer ShuffledHash UnsupporedO AggregateTra CondProjectTr JoinTransform perator nsformer ansformer er CondProjectTransformer WholestageTransformer C2R R2C WholestageTransformer
14 .Gluten shuffle Parquet Read • Velox backend implementation is using Arrow IPC based shuffle Stage1 Transformer • Clickhouse backend use its internal columnar format Project • Cache split batches in memory Gazelle’s • On memory pressure, spill all batches ColumnarShuffle Split/Compress/Write into single file with part. id seq Shuffler Reader • Merge all spill files into data file at end Stage2 Transformer Coalesce
15 .Gluten remote shuffle • Apache Celeborn is already supported • Contributed by Alibaba EMR team • Works well with K8s setup • Can bring performance benefits on HDD-based setup • Apache Uniffle support is working in progress https://mp.weixin.qq.com/s/HMitbWH-cfxvi7j9GaWb5Q
16 .Gluten memory management • Memory Pool hold a block of memory • Acquire from task memory manager if not enough • Report all allocation to Spark • Spill happens if task doesn’t have enough memory
17 .Pyspark offload Worker Node Python Executor Executor Task Apache Arrow IPC Pandas/TouchArrow Task UDF Block Block Task Task manager manager Driver Node Native SQL Implementation of Offload Pandas Velox
18 .Gluten status • TPC-H Like workload and TPC-DS Like workload Function Coverage: Spark3.2 Spark with 99% offloaded total Common Gluten 361 235 195 • Ubuntu 20/22, CentOS7/8 Support Operator Coverage: • Spark 3.2/3.3 Support, experimental for Spark 3.4 Spark3.2 Spark Gluten total Common • AQE, DPP Support 90 37 28 • Velox metrics added Data Type Coverage: • Memory management (Spill supported) BOOL BYTE SHORT INT LONG FLOAT DOUBLE STRING NULL BINARY TIMEST DECIMA CALEND ARRAY MAP STRUCT DATE UDT • Pass Velox & Spark UT AMP L AR • Work in progress to contribute to Apache
19 . Gluten w/ Velox performance TPC-H Like Benchmarks TPC-DS Like Benchmarks SF2T Performance SF2T Performance 3.00 3.00 2.71 2.50 2.50 2.29 Normalized Performance Normalized Performance 2.00 2.00 (Higher is better) (Higher is better) 1.50 1.50 1.00 1.00 1.00 1.00 0.50 0.50 0.00 0.00 Spark Gluten + Velox Spark Gluten + Velox Performance varies by use, configuration and other factors. See backup for configuration details
20 . Gluten w/ Velox on TPCDS-like workload performance Top 20 TPCDS-like workload speedup: gluten vs. vanilla 14.00 12.67 12.00 10.00 Speedup(x) 8.00 6.00 5.17 4.52 4.00 4.16 3.84 3.29 3.09 2.77 2.59 2.57 2.07 2.20 2.34 2.25 2.00 2.01 2.07 1.48 1.54 0.86 0.84 - q4 q67 q23b q23a q78 q93 q14a q64 q95 q14b q50 q24a q75 q24b q28 q11 q74 q97 q65 q16 Performance varies by use, configuration and other factors. See backup for configuration details
21 . Gluten w/ CK performance • Average 2.12x speedup in total 22 TPC-H Like queries • Up to 3.48x speedup in a single query • Functionality Pass for 21 queries, still have some functionality issue in q21(link) Department or Event Name DCAI-DAIS-AISE-DAP-BDF Intel Confidential 21
22 . Gluten w/ Velox: Parquet write • Typical ETL : big fact tables join with small • Example query: dimension tables, then write back with spark.sql(" select * from store_sales left outer join customer_demographics on parquet/orc ss_cdemo_sk = cd_demo_sk and cd_demo_sk <= 1920800 ; ") • Up to ~2.5x speedup, depends on data size .write.option("parquet.compression",“zstd") and compression codec .mode("overwrite") .format("parquet") .save("ETL/newparquet") Performance varies by use, configuration and other factors. See backup for configuration details
23 . Gluten w/ Velox: decimal aggregations • Example query: • Typical analysis case: aggregation over select decimal data, up to ~10x perf l_returnflag, improvement l_linestatus, • Java BigDecimal has problem on sum(l_quantity) as sum_qty, performance sum(l_extendedprice) as sum_base_price, from lineitem where l_shipdate <= '1998-09-02' group by l_returnflag, l_linestatus Performance varies by use, configuration and other factors. See backup for configuration details
24 . Gluten w/ Velox: memory footprint • Memory footprint reduced a lot vs. Vanilla Spark TPCH-like workload Memory Footprint: gluten vs. vanilla 9E+11 8E+11 7E+11 6E+11 5E+11 bytes 4E+11 3E+11 2E+11 1E+11 0 gluten vanilla Performance varies by use, configuration and other factors. See backup for configuration details
25 .Lessons learned in engineering work • Writing a robust native engine is difficult! • TPC-H/DS workloads + Spark Unit tests is not enough • Need more “complex” or real-world workload ➢ A good fuzz testing framework can help to discover many bugs • Spark internal API changes: operators, functions. • E.g., join, parquet write, decimal functions… ➢ Need to setup a shim layer for different Spark versions • Spark Catalyst planner is not good enough • Performance of good plan vs. bad plan diff a lot ➢ Need more work on Spark optimizer
26 .Customer landing issues • Semantic gaps between Spark and native engines • Floating point: precision issue, scientific notion • NULL/Overflow handling • timestamp vs. timestamp_ntz • Solutions: • Setup fuzz tests with Spark expressions, run many tests • Enable SQL logic tests and pass it
27 .Customer landing issues • Disk/Network I/O is the bottleneck in Spark cluster, CPU is not the key path • Remote storage introduced long latency • HDD based Shuffle is too slow • 10Gb networking is not good enough • Solutions: • Using local cache for table scan • Using remote shuffle service • Upgrade to 25Gb networking
28 .Customer landing issues • Different spark configurations required: • off-heap vs. on-heap • shuffle.partitions • maxPartitionBytes ➢ Solutions: need engineering efforts to do more turning work • Too many fallbacks, resulting lower performance vs. Vanilla Spark ➢ Solutions: A tool to check if SQL is “worth” to run with Gluten
29 .Gluten roadmap • Implement more native functions/operators • Support Spark 3.4/3.5 • Support Data Lake solutions(Delta/Iceberg/Hudi) • Improve robustness, verified by more production workloads
3秒后跳转登录页面
去登陆

