





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
大模型推理在eBay的架构实践-田浩炜

田浩炜-eBay高级技术专家
2014年硕士毕业于浙江大学计算机系。曾在蜻蜓FM、一条网络科技任职,负责搜索、推荐系统的算法及机器学习平台的系统架构的研发工作,在eBay先后参与了特征工程管理平台、统一推理平台,模型训练平台的研发。目前主要负责eBay大模型的训练基建及推理平台的相关工作。
分享介绍:
随着AIGC技术的兴起,eBay各业务部门正积极应用AIGC以加速提升业务价值。然而,随着AIGC模型规模不断增大,机器学习平台的架构也面临更多挑战。为满足业务团队需求,eBay机器学习平台部门在基础架构层进行了多项升级,特别针对大规模AIGC模型的特点和应用场景。本次演讲将重点介绍eBay机器学习平台在大模型推理方面的架构实践,从大模型生命周期管理、模型部署和推理架构、模型优化等方面来简述eBay机器学习平台在AIGC领域的工作。
展开查看详情
1 .Architectural Practices of Large- scale Model Inference in eBay Haowei Tian - eBay 1
2 .Agenda Unified Inference Platform in eBay 1 An overview of our unified model inference platform Emerging Large-Scale Model Requirements 2 Emerging large-scale model ecosystem and eBay internal needs Large Language Models Inference Practice 3 Technology and practice for LLM deployment Multimodal Large-Scale Model Inference Practice 4 Technology and practice for Stable Diffusion Model deployment Next Steps 5 Looking forward to the future 2
3 .01 Unified Inference Platform in eBay 3
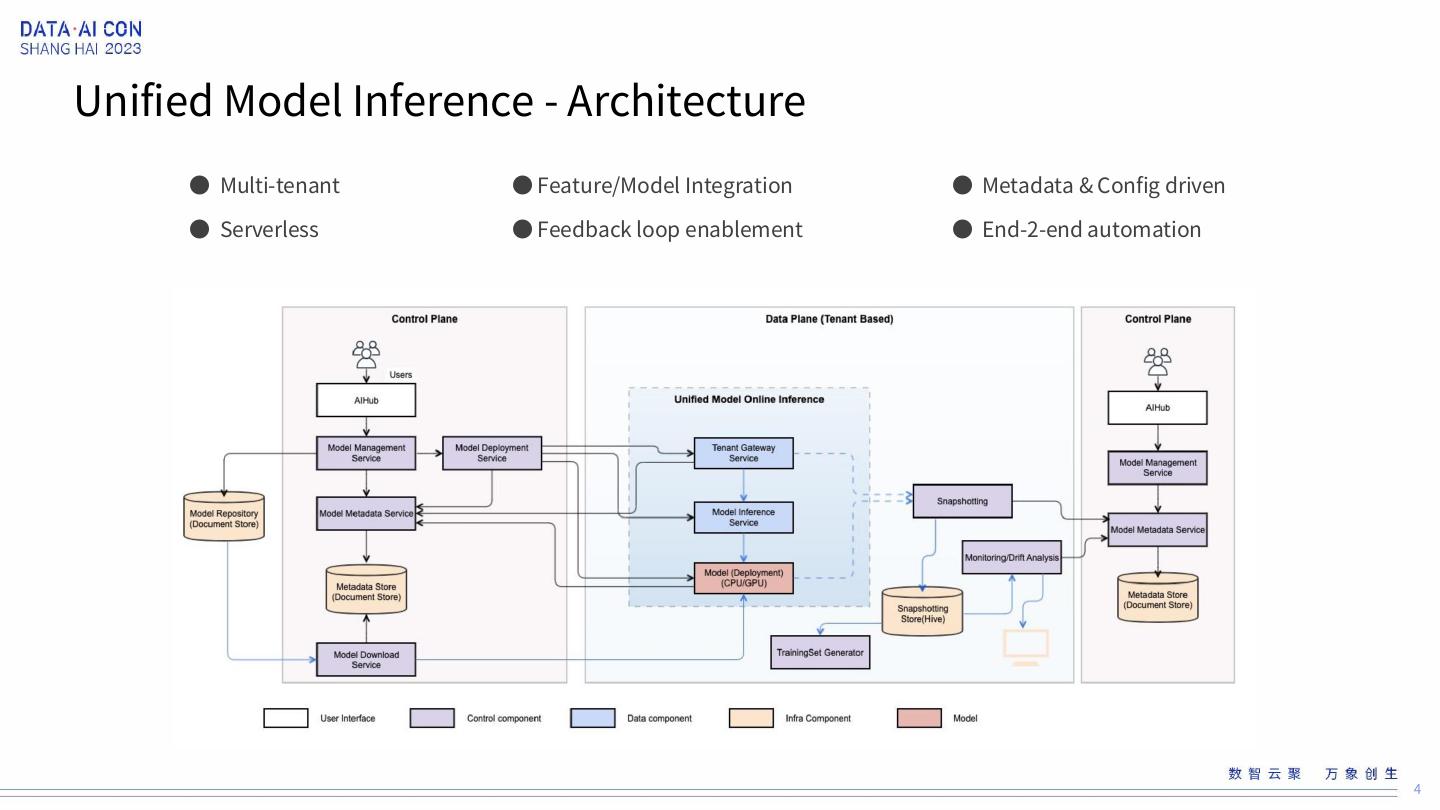
4 .Unified Model Inference - Architecture ● Multi-tenant ● Feature/Model Integration ● Metadata & Config driven ● Serverless ● Feedback loop enablement ● End-2-end automation 4
5 .Scalable Model Deployment Assemble Types Description Applicable Scenarios Examples One single model to be deployed, Most CTR / CVR Mono For most cases most deployments are of this type models The model has pre- and post-processors, Several relevant models executed in Most Current CV Ensemble and the processors utilize a different sequential models framework than the model. 5
6 .Scalable Model Deployment Assemble Types Description Applicable Scenarios Examples Several relevant models co- • Risk segmentation models • Model Segmentation Orchestrator located and sometimes looped or • Gen-AI models such as Stable • Loop scheduler conditioned involved. Diffusion 6
7 .02 Emerging Large-Scale Model Requirements 7
8 .Embracing eBay Internal Needs Payment & Ads & Recs Search Marketing BuyerEx DSS IE Risk Others 11% Domain Business 42% Dev Velocity 47% https://innovation.ebayinc.com/tech/features/magical-listing-tool- More and more teams are embracing LLM for their business harnesses-the-power-of-ai-to-make-selling-on-ebay-faster-easier- and-more-accurate/ 8
9 .GAPs and Challenges LLMs are costly, demand and benefits should be carefully evaluated for each use case Governance Large files deploy Delta patching deploy Improve throughput and reduce latency Performance Deploy Multi-card deploy Multi-node deploy Serving Streaming API Early stop New serving pattern Easy switch between different models 9
10 .03 Large Language Models Inference Practice 10
11 .Model Onboard • Model & Code separation • Local Testing • Integration with Jupyter Lab in training platform • Standardized Model schema for Simplification 11
12 .Model Deployment • Multi-threads file upload and download • Delta model patching (LoRA, P-tuning) • Multi-card deploy 12
13 .Model Inference Pattern Prompt context phase • Prompt context phase • < 10% Time (for most use case) KV Cache • Computation bounded • Token generation phase • > 90% Time (for most use case) • IO bounded Token generation phase • KV Cache • High GPU memory consumption • Grows linearly with the batch-size • Differ LLM perf optimization from others 13
14 .Model Optimization – Engineering Perspective • Kernel Fusion • Flash Attention / Flash Decoding • Paged Attention • Dynamic Batching • Tensor Parallelism • S-LoRA • Speculative Sampling • Faster Tokenizer (Only for very large batch size) 14
15 .Model Optimization – Algorithm Perspective • MHA GQA MQA • Compress & Distillation • Model Quantization • SmoothQuant • Weight-only quantization(Group-wise) • KV cache Int8 • Large Model with Low Precise / Small Model with High Precise 15
16 .Framework Integration TGI -- Evaluate as Benchmark Currently also very fast with paged attention & flash attention 2.0 vLLM -- In Use Being quickly updated, but still some unmerged useful PRs. Such as P-tunning, Int8 KV Cache Quant and etc. TensorRT-LLM -- Exploring Many build-in ability, still exploring. 16
17 .Model Serving • Streaming API • Server-Sent Events • GRPC Streaming • Early stop 17
18 .LLM Serving Pattern Chat • Input can be history chat messages or instruction to follow • May include pre-defined prompt templates. • Single-round chat • Instruction-following chat • Multi-round chat RAG • Require prompt engineering with external knowledge • Call external recall service 18
19 .LLM Serving Pattern Agent • ReAct framework • Work with external tool APIs • Multi-round interaction pipeline Agent Reasoning Task LLM Action Tools Environment Result 19
20 .Gateway and Use case Integration ● GPT Gateway ● RAG enhance ● Similarity Search ● Application Storage ● Conversation DB ● Inference API ● UIP LLM (our service) ● External LLM 20
21 .Use case Demo ● eBayCoder ● Write code ● Solve coding issues ● Search for the relevant information. 21
22 .04 Multimodal Large-Scale Model Inference Practice 22
23 .Stable Diffusion Architecture Transformer base (sharing LLM optimization techniques such as kernel fusion) Consists of several disparate models • Te xt e nc o de r • U- N e t • S c h e du le r • Au to e nc o de r (VAE ) 23
24 .Stable Diffusion Inference Orchestrator serving pattern • Consist of several sub models • Sampling in a loop https://stable-diffusion-art.com/samplers/ https://huggingface.co/blog/stable_diffusion 24
25 .Inference Architecture Unit deployment for co-located model deployments 25
26 .05 Next Steps 26
27 .Next Steps Seamless Training Integration Perf Improvements Prompts Warehouse Agent Support Responsible AI Governance 27
28 .28
3秒后跳转登录页面
去登陆

