





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
2.余吉文-openLooKeng:如何实现跨源跨域的高性能融合分析
余吉文,Huawei R&D Senior Engineer,上海交通大学自动化专业硕士,现任华为研发高级工程师。拥有6年软件开发和大数据领域行业经验,目前参与openLooKeng的版本规划和交付进度管理工作。

展开查看详情
1 .openLooKeng : 如何实现跨源跨域的高性能融合分析 余吉文 openLooKeng Community Tech PM & User Group Member
2 .目录 01 openLooKeng介绍 02 交互式场景的关键技术 03 Milestone 04 总结
3 .目录 01 openLooKeng介绍 02 交互式场景的关键技术 03 Milestone 04 总结
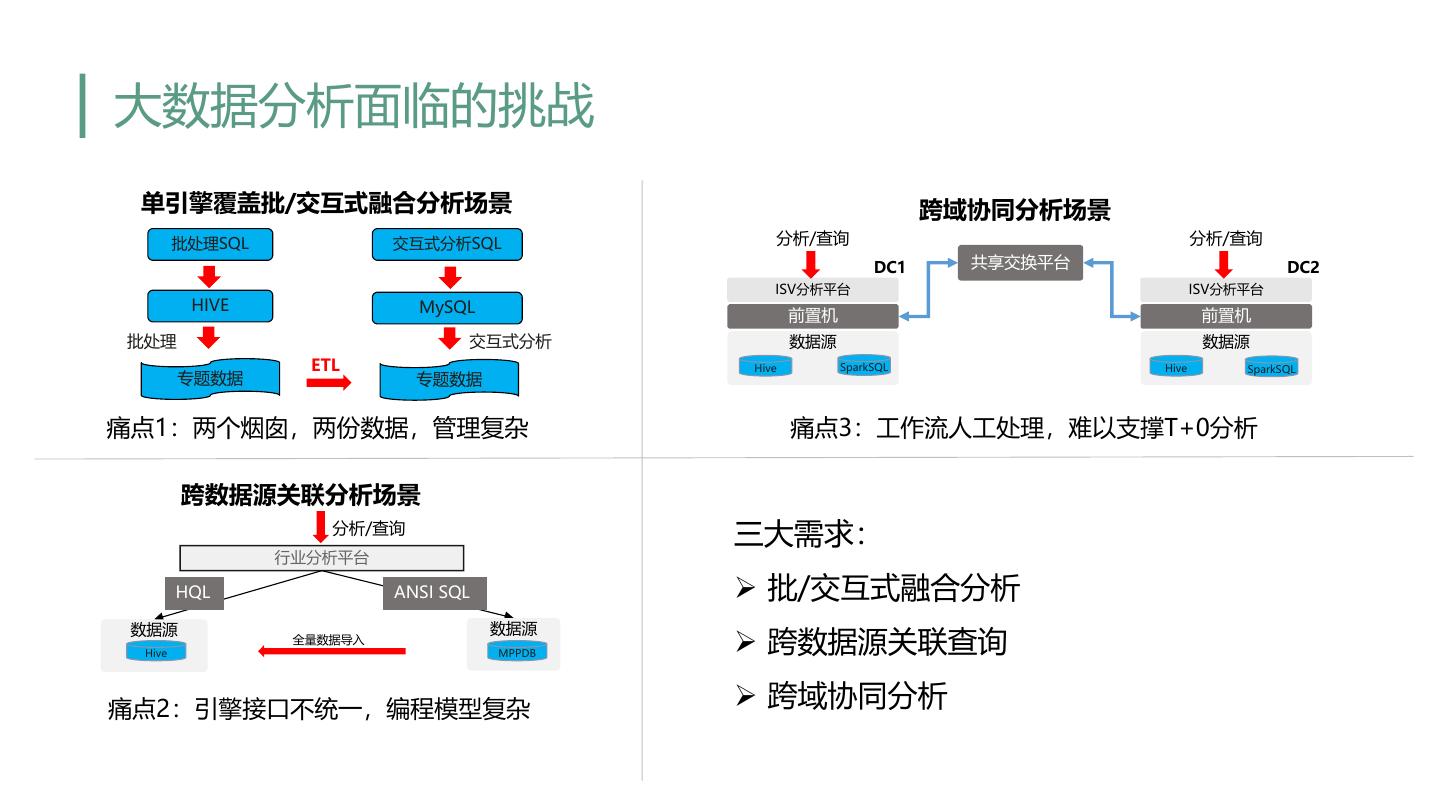
4 .大数据分析面临的挑战 单引擎覆盖批/交互式融合分析场景 跨域协同分析场景 批处理SQL 交互式分析SQL 分析/查询 分析/查询 DC1 共享交换平台 DC2 ISV分析平台 ISV分析平台 HIVE MySQL 前置机 前置机 批处理 交互式分析 数据源 数据源 ETL Hive SparkSQL Hive SparkSQL 专题数据 专题数据 痛点1:两个烟囱,两份数据,管理复杂 痛点3:工作流人工处理,难以支撑T+0分析 跨数据源关联分析场景 分析/查询 三大需求: 行业分析平台 HQL ANSI SQL Ø 批/交互式融合分析 数据源 数据源 Hive 全量数据导入 MPPDB Ø 跨数据源关联查询 痛点2:引擎接口不统一,编程模型复杂 Ø 跨域协同分析
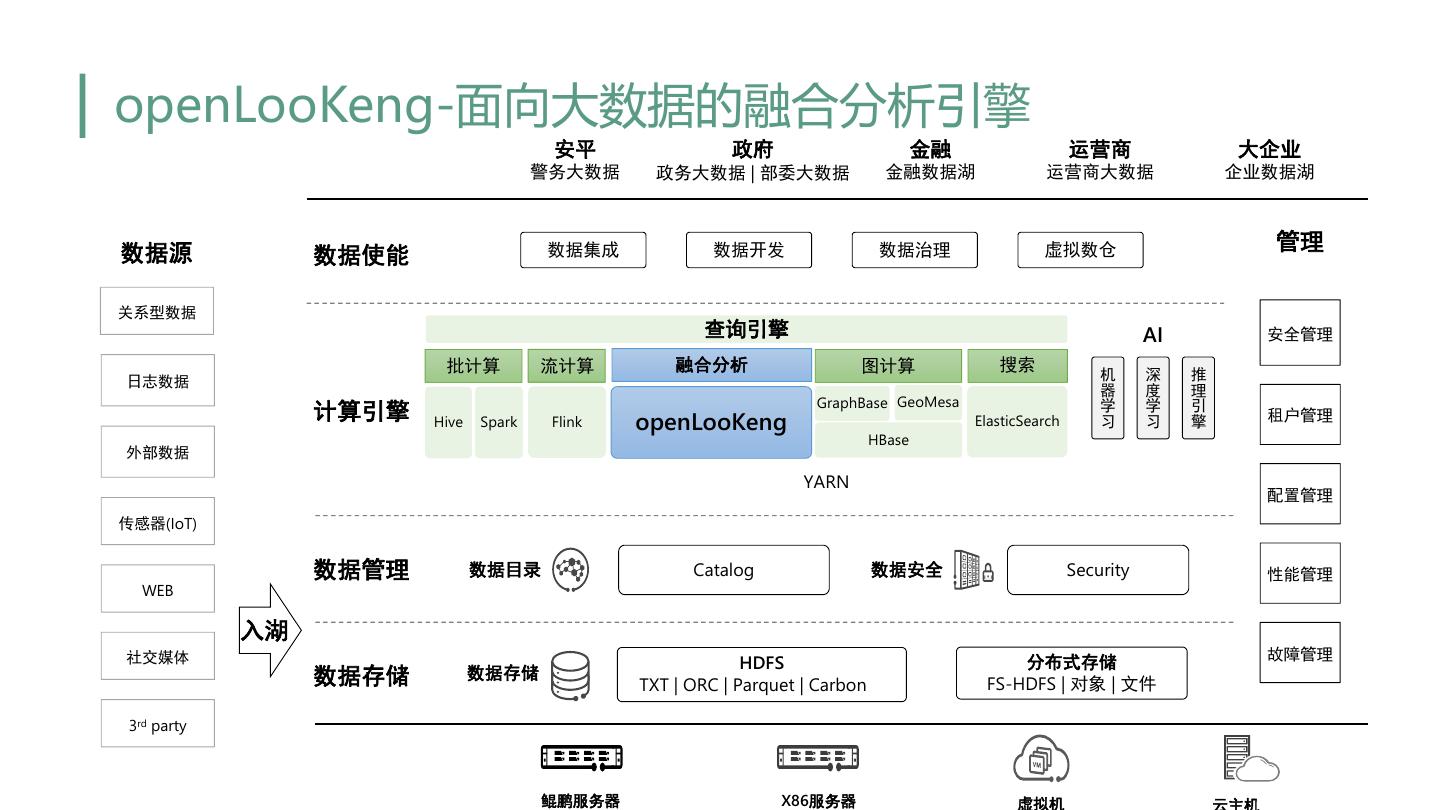
5 .openLooKeng-面向大数据的融合分析引擎 安平 政府 金融 运营商 大企业 警务大数据 政务大数据 | 部委大数据 金融数据湖 运营商大数据 企业数据湖 数据源 数据集成 数据开发 数据治理 虚拟数仓 管理 数据使能 关系型数据 查询引擎 AI 安全管理 机器学习 深度学习 推理引擎 批计算 流计算 融合分析 图计算 搜索 日志数据 GraphBase GeoMesa 计算引擎 Hive Spark Flink openLooKeng ElasticSearch 租户管理 HBase 外部数据 YARN 配置管理 传感器(IoT) 数据管理 数据目录 Catalog 数据安全 Security 性能管理 WEB 入湖 故障管理 社交媒体 HDFS 分布式存储 数据存储 数据存储 TXT | ORC | Parquet | Carbon FS-HDFS | 对象 | 文件 3rd party 鲲鹏服务器 X86服务器 虚拟机
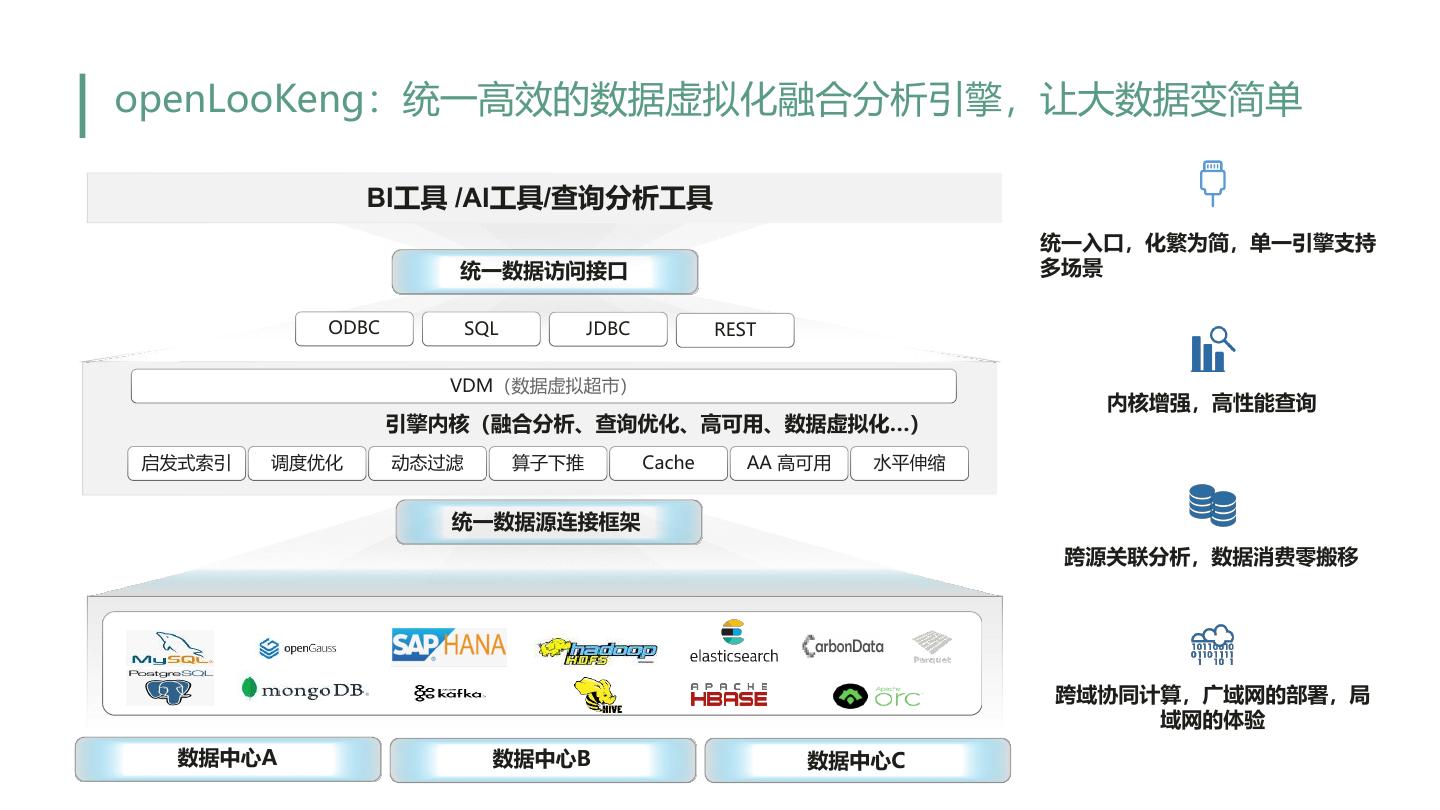
6 .openLooKeng:统一高效的数据虚拟化融合分析引擎,让大数据变简单 BI工具 /AI工具/查询分析工具 统一入口,化繁为简,单一引擎支持 统一数据访问接口 多场景 ODBC SQL JDBC REST VDM(数据虚拟超市) 内核增强,高性能查询 引擎内核(融合分析、查询优化、高可用、数据虚拟化…) 启发式索引 调度优化 动态过滤 算子下推 Cache AA 高可用 水平伸缩 统一数据源连接框架 跨源关联分析,数据消费零搬移 跨域协同计算,广域网的部署,局 域网的体验 数据中心A 数据中心B 数据中心C
7 . openLooKeng架构 openLooKeng cluster1 openLooKeng cluster2 Discovery … Discovery Coordinator Coordinator Coordinator server server 分布式处理系统,MPP架构 跨域 跨DC Worker Worker Worker Worker Worker Worker 高可用性,无单点故障 Data Center Connector 向量化列式处理引擎 Data Source Data Source Connector Connector MySQL Hive Elasticsearch MySQL Hive 基于内存的流水线处理 7
8 .目录 01 openLooKeng介绍 02 交互式场景的关键技术 03 Milestone 04 总结
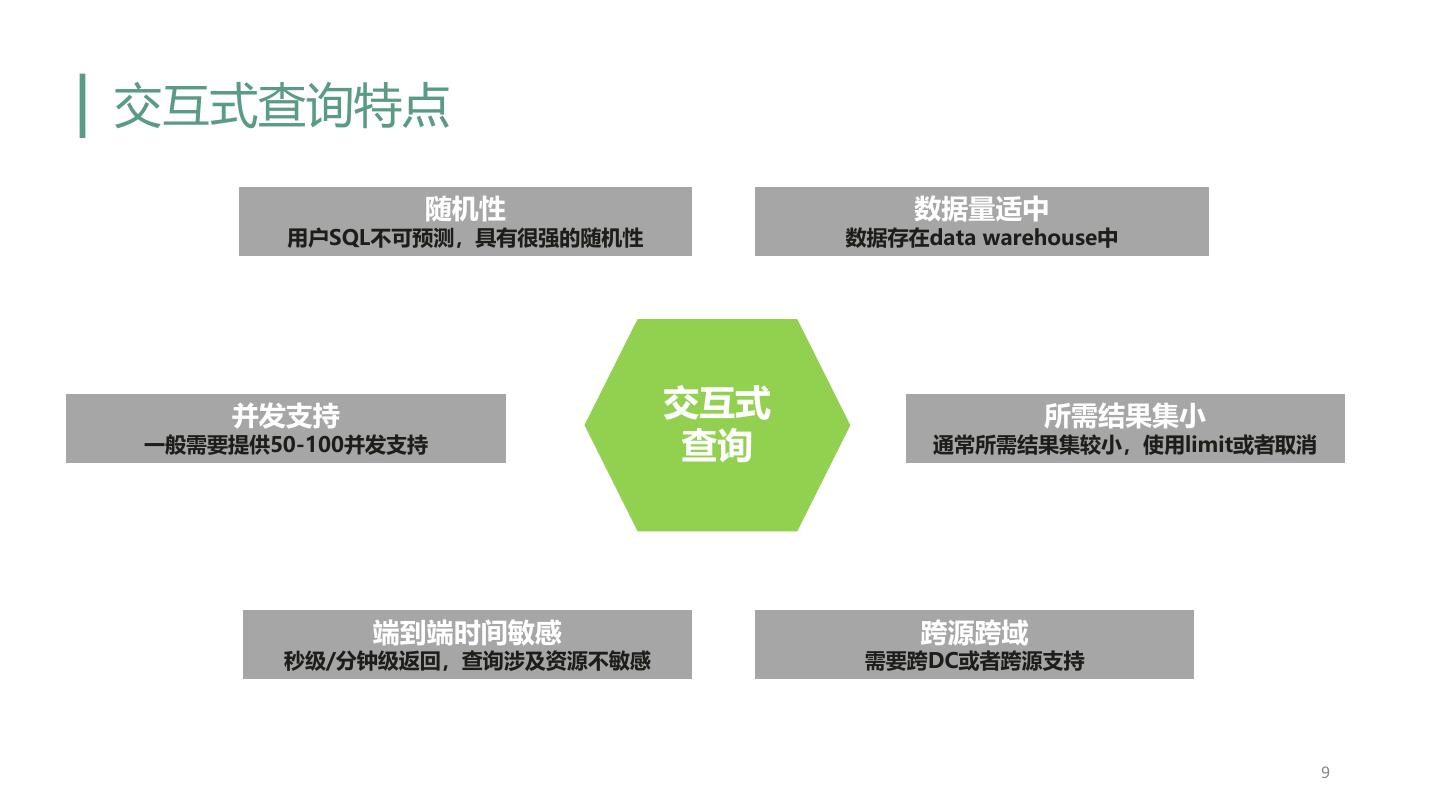
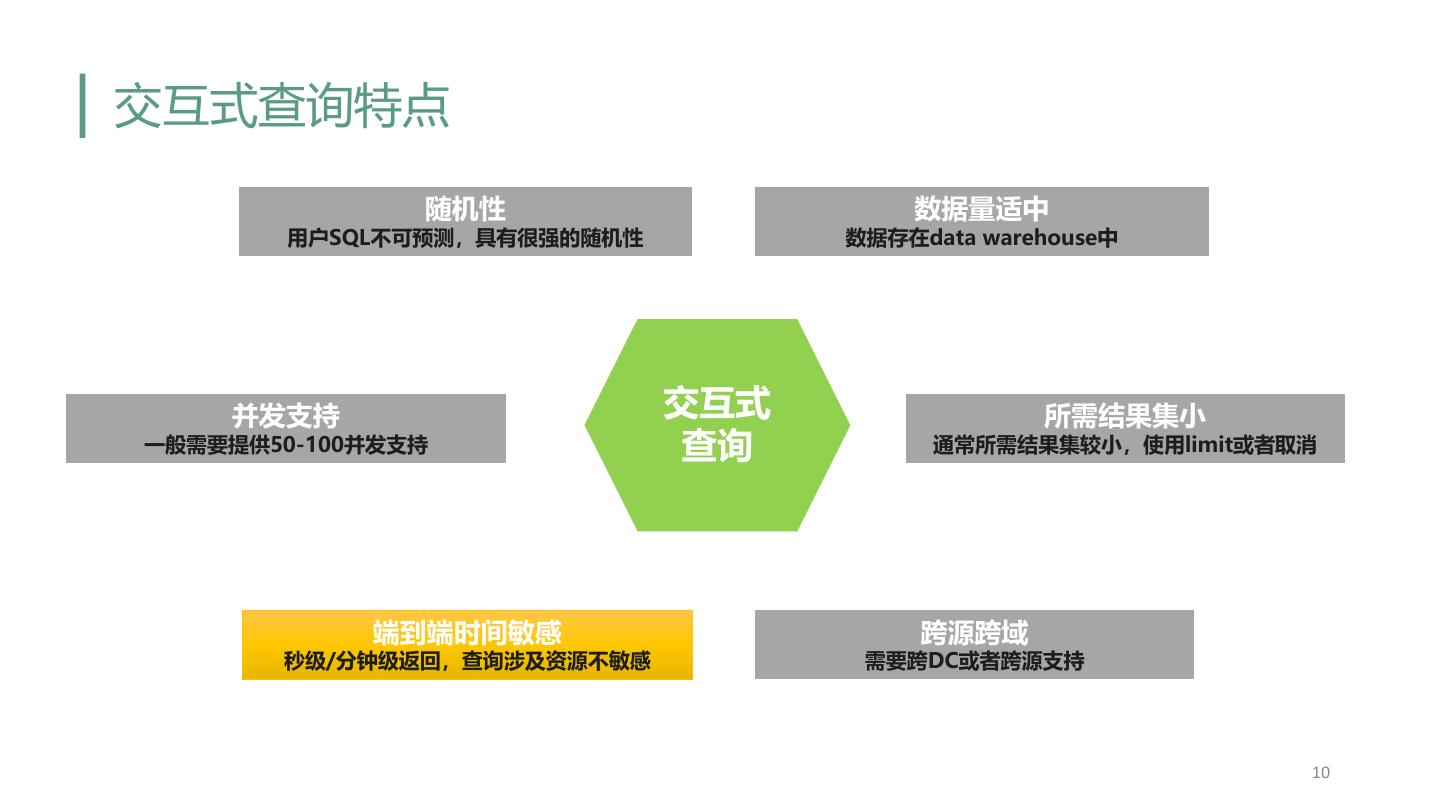
9 .交互式查询特点 随机性 数据量适中 用户SQL不可预测,具有很强的随机性 数据存在data warehouse中 并发支持 交互式 所需结果集小 一般需要提供50-100并发支持 查询 通常所需结果集较小,使用limit或者取消 端到端时间敏感 跨源跨域 秒级/分钟级返回,查询涉及资源不敏感 需要跨DC或者跨源支持 9
10 .交互式查询特点 随机性 数据量适中 用户SQL不可预测,具有很强的随机性 数据存在data warehouse中 并发支持 交互式 所需结果集小 一般需要提供50-100并发支持 查询 通常所需结果集较小,使用limit或者取消 端到端时间敏感 跨源跨域 秒级/分钟级返回,查询涉及资源不敏感 需要跨DC或者跨源支持 10
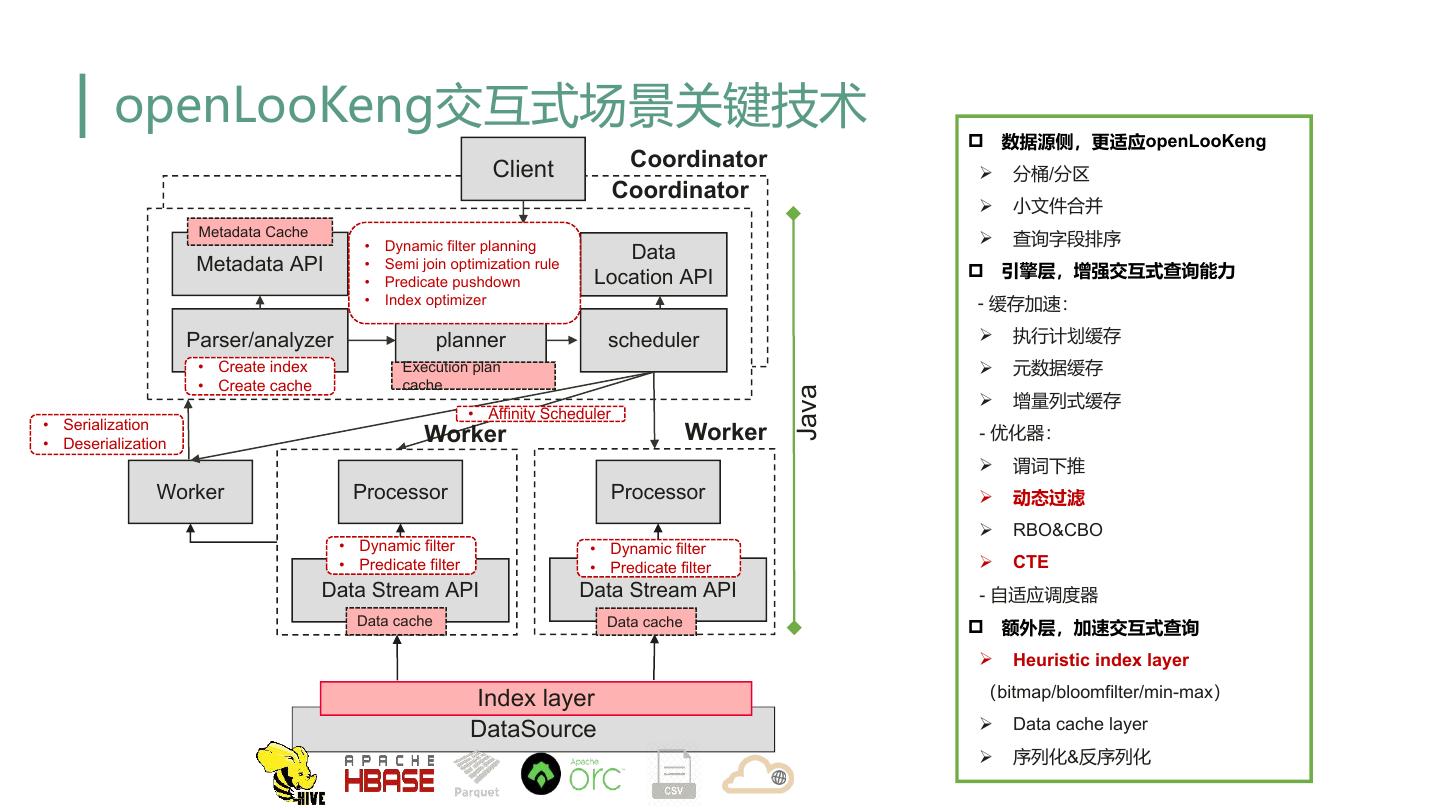
11 . openLooKeng交互式场景关键技术 p 数据源侧,更适应openLooKeng Client Coordinator Ø 分桶/分区 Coordinator Ø 小文件合并 Metadata Cache • Dynamic filter planning Ø 查询字段排序 Data Metadata API • Semi join optimization rule p 引擎层,增强交互式查询能力 • Predicate pushdown Location API • Index optimizer - 缓存加速: Parser/analyzer planner scheduler Ø 执行计划缓存 • Create index Execution plan Ø 元数据缓存 • Create cache cache Java Ø 增量列式缓存 • Affinity Scheduler • Serialization • Deserialization Worker Worker - 优化器: Ø 谓词下推 Worker Processor Processor Ø 动态过滤 Ø RBO&CBO • Dynamic filter • Dynamic filter • Predicate filter • Predicate filter Ø CTE Data Stream API Data Stream API - 自适应调度器 Data cache Data cache p 额外层,加速交互式查询 Ø Heuristic index layer Index layer (bitmap/bloomfilter/min-max) DataSource Ø Data cache layer Ø 序列化&反序列化
12 .CTE (Common Table Expression)执行计划优化 以TPC-DS Q47为代表的查询 查询性能提升50%+ (10TB,180s 降至 63s) Single-stream tpcds-10TB scenario 不开启CTE 开启CTE 性能提升 Total(s) 10591 8873 16% 12
13 . TPC-DS场景分析 TPC-DS是TPC标准组织推出的一个广泛使用的行业标准决策支持基准,用于评估数据处理引擎的性能 TPCDS数据模型 Ø 包含7张事实表和17张维度表 Ø 事实表数据量极大,而维度表相对较小 事实表Billion级 Ø 查询很少有谓词直接应用到事实表 随机性 Ø 事实表查询条件通过维度表相连接得到 数据量适中 并发支持 带来的挑战 维度表Kilo至Millon级 Ø 传统谓词下推等优化很难应用 所需结果集 端到端时间 小 敏感 Ø Join数据量巨大导致执行时间过长 跨源跨域 Catalog Sales表ER图 场景维度分析 13
14 . Dynamic Filtering 依靠join条件以及build侧表读出的数据,运行时生成动态过滤条件(dynamic filters),应用到probe侧 表的table scan阶段,从而减少参与join操作的数据量,有效地减少IO读取与网络传输 客户端 语法语义分析 Coordinator DynamicFilter Dynamic Filtering 执行计划生成 动态过滤查询优化规则 Service Ø 添加DynamicFIlterSource算子,搜集 执行计划调度 ③ Merge build侧数据 Worker Ø 依赖分布式缓存进行DF的处理 Worker Join Ø 适用于inner join & right join ② Get Ø 适用于join选择率较高的场景 分布式缓存 DynamicFilter ④Apply ProbeTableScan Source DynamicFilter ①Build BuildTableScan 数据源 14
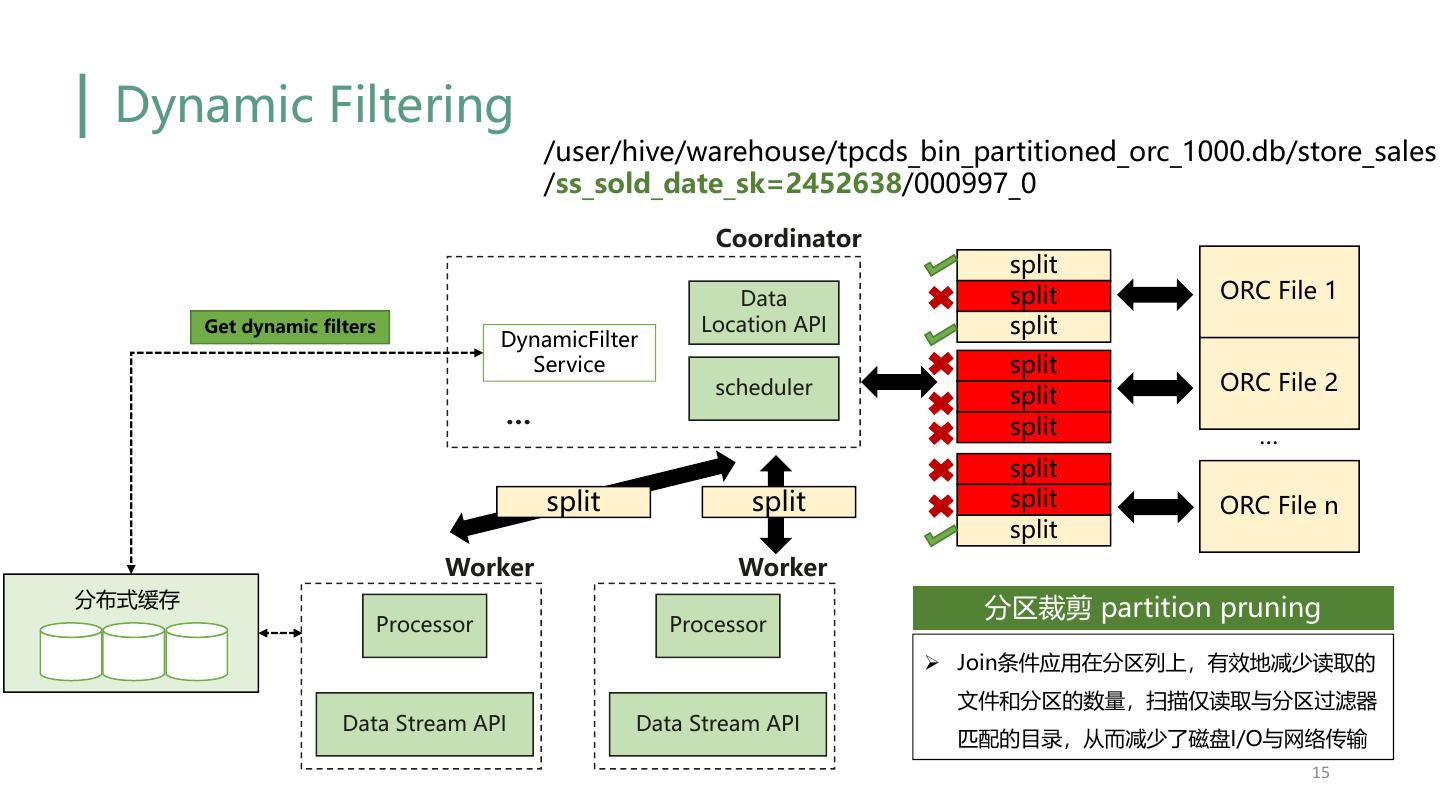
15 . Dynamic Filtering /user/hive/warehouse/tpcds_bin_partitioned_orc_1000.db/store_sales /ss_sold_date_sk=2452638/000997_0 Coordinator split Data split ORC File 1 Get dynamic filters Location API split DynamicFilter Service split scheduler ORC File 2 split … split … split split split split ORC File n split Worker Worker 分布式缓存 分区裁剪 partition pruning Processor Processor Ø Join条件应用在分区列上,有效地减少读取的 文件和分区的数量,扫描仅读取与分区过滤器 Data Stream API Data Stream API 匹配的目录,从而减少了磁盘I/O与网络传输 15
16 . Dynamic Filtering 客户端 语法语义分析 Coordinator 行过滤 row filtering DynamicFilter 执行计划生成 动态过滤查询优化规则 Service Ø Join条件应用在非分区列上,通过应用动态过 执行计划调度 滤条件对数据进行行过滤,减少Join的数据量 ③ Merge Worker Join ② Get 分布式缓存 DynamicFilter ④Apply ProbeTableScan Source ①Build BuildTableScan Filtered page Page Filtered Page DynamicFilter Column 1 Column 1 Page Column 2 Column 2 OrcPageSource Column 3 Column 3 … … Column 8 Column 8 数据源 16
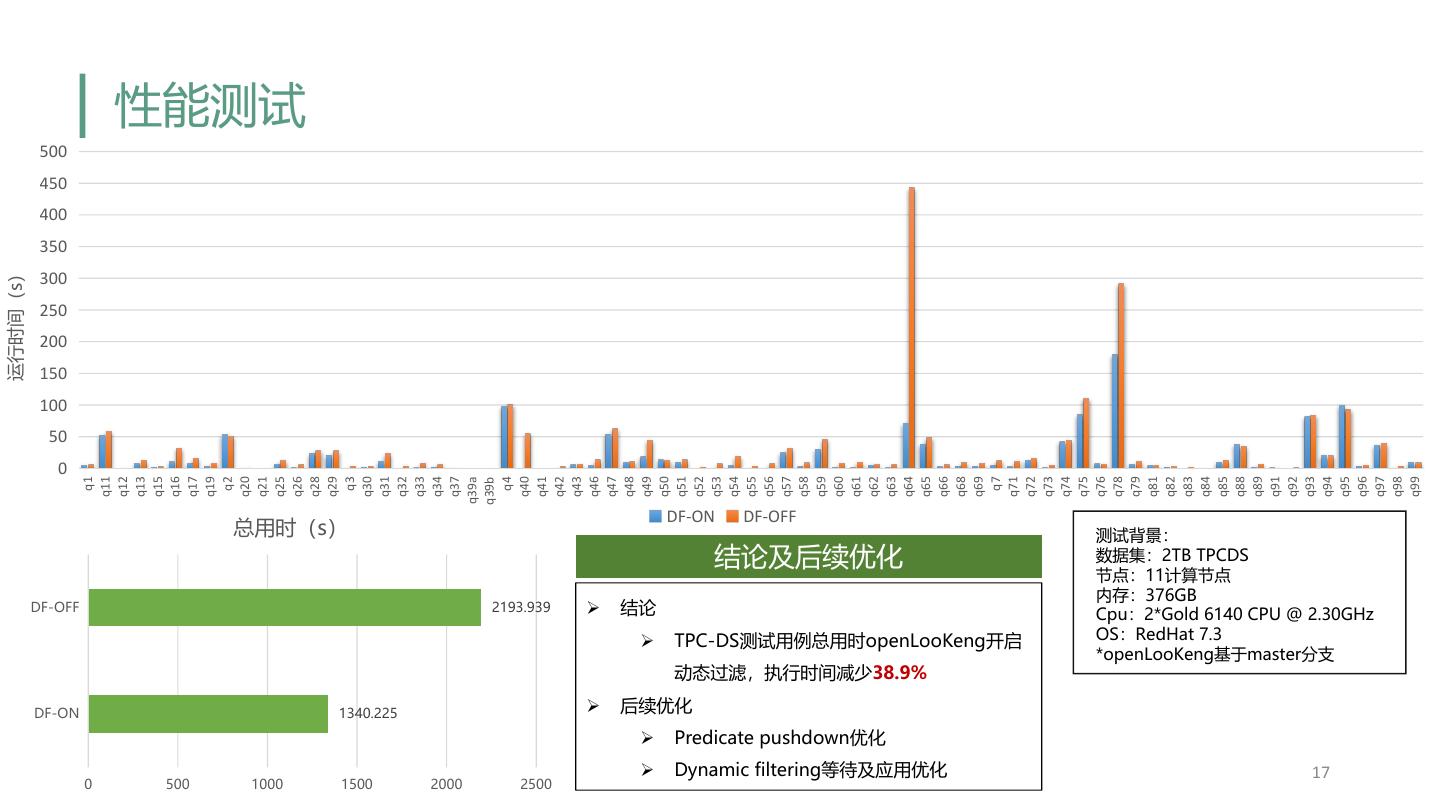
17 . 性能测试 500 450 400 350 运行时间(s) 300 250 200 150 100 50 0 q11 q12 q13 q15 q16 q17 q19 q20 q21 q25 q26 q28 q29 q30 q31 q32 q33 q34 q37 q39a q40 q41 q42 q43 q46 q47 q48 q49 q50 q51 q52 q53 q54 q55 q56 q57 q58 q59 q60 q61 q62 q63 q64 q65 q66 q68 q69 q71 q72 q73 q74 q75 q76 q78 q79 q81 q82 q83 q84 q85 q88 q89 q91 q92 q93 q94 q95 q96 q97 q98 q99 q1 q2 q3 q4 q7 q39b DF-ON DF-OFF 总用时(s) 测试背景: 结论及后续优化 数据集:2TB TPCDS 节点:11计算节点 内存:376GB DF-OFF 2193.939 Ø 结论 Cpu:2*Gold 6140 CPU @ 2.30GHz Ø TPC-DS测试用例总用时openLooKeng开启 OS:RedHat 7.3 *openLooKeng基于master分支 动态过滤,执行时间减少38.9% DF-ON 1340.225 Ø 后续优化 Ø Predicate pushdown优化 Ø Dynamic filtering等待及应用优化 17 0 500 1000 1500 2000 2500
18 . 跨域Dynamic Filtering DC-2 Coordinator:1)将DC-1的BF filter以QueryId为Key存入到hazelcast;2)判断当前query是否存在跨域dynamic filter,存在,设置session中的cross- region-dynamic-filter;3)CN生产执行计划Plan,从Plan中Query的列名到Plan的outputSymbols的映射关系,存入hazelcast;4)判断Plan的 TableScanNode是否存在DC table,如存在,则标记,可能存在继续下推BF filter的可能。 DC-2 Worker:1) CrossRegionDynamicFilterOp从hazelcast中取出BF filter和outputSymbols,判断是否存在过滤列,存在则应用filter对Page进行过滤;2) TableScanOperator应用filter和步骤一类似;3)如果TableScanNode存在DC table,则生成新的BF filter并存入hazelcast,用于发送给下一级DC。
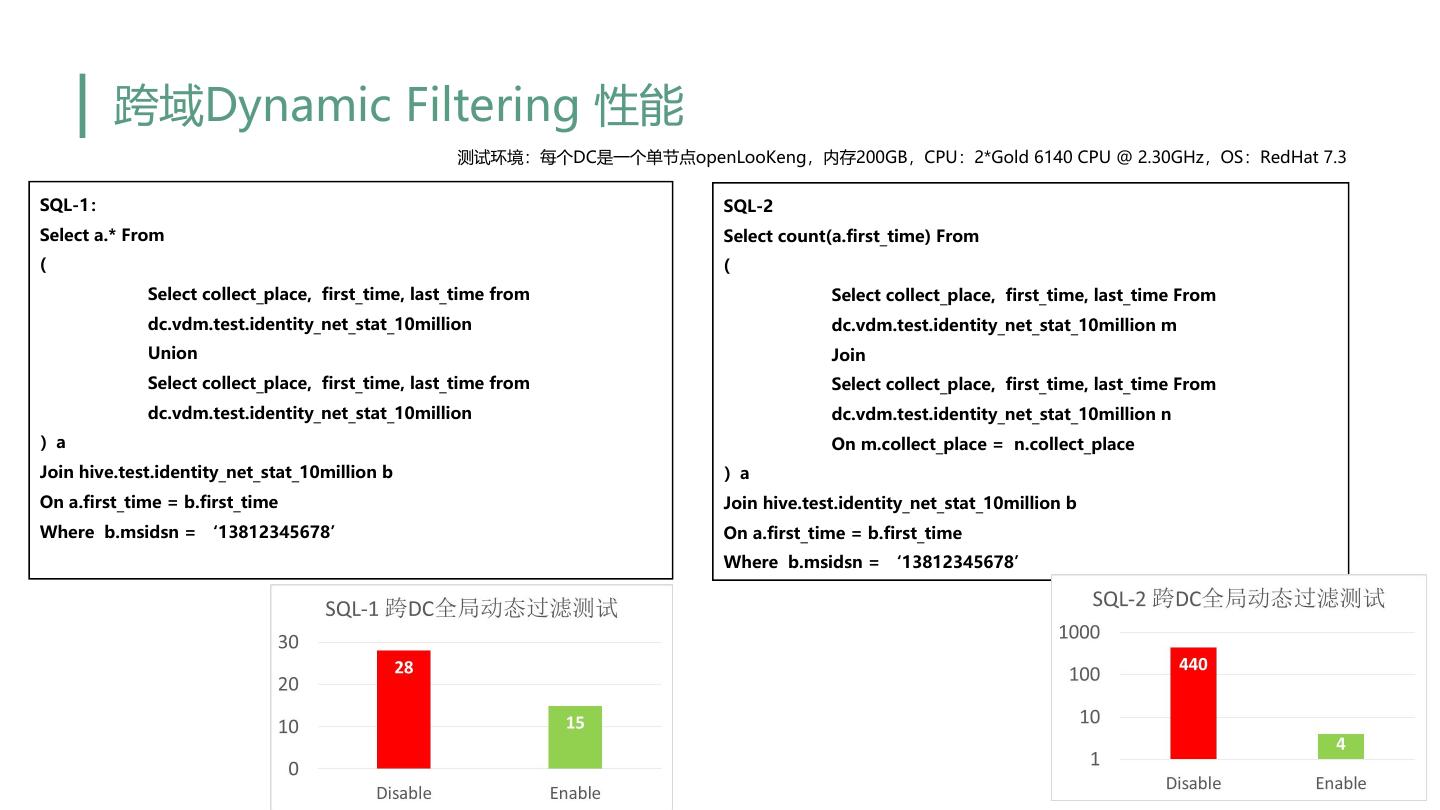
19 . 跨域Dynamic Filtering 性能 测试环境:每个DC是一个单节点openLooKeng,内存200GB,CPU:2*Gold 6140 CPU @ 2.30GHz,OS:RedHat 7.3 SQL-1: SQL-2 Select a.* From Select count(a.first_time) From ( ( Select collect_place, first_time, last_time from Select collect_place, first_time, last_time From dc.vdm.test.identity_net_stat_10million dc.vdm.test.identity_net_stat_10million m Union Join Select collect_place, first_time, last_time from Select collect_place, first_time, last_time From dc.vdm.test.identity_net_stat_10million dc.vdm.test.identity_net_stat_10million n )a On m.collect_place = n.collect_place Join hive.test.identity_net_stat_10million b )a On a.first_time = b.first_time Join hive.test.identity_net_stat_10million b Where b.msidsn = ‘13812345678’ On a.first_time = b.first_time Where b.msidsn = ‘13812345678’
20 . Heuristic index架构 Client Coordinator Coordinator Data Metadata API Location API Heuristic index • Index optimizer HIndex-稀疏索引 Ø 提供统一的索引框架 Parser/analyzer planner scheduler Ø 支持多种索引结构 • Create index Ø 稀疏索引:Bloomfilter、Min-Max • Affinity Scheduler Worker Worker Ø 稠密索引:Bitmap,Btree Ø 任务调度阶段: Worker Processor Processor Ø 裁剪Split,减少调度到Worker的任务数 • Index filtering • Index filtering Ø 支持基于索引的亲和性调度 Data Stream API Data Stream API Ø 数据读取阶段: Ø 减少加载到计算侧内存的数据量 HIndex-稠密索引 Index layer DataSource 20
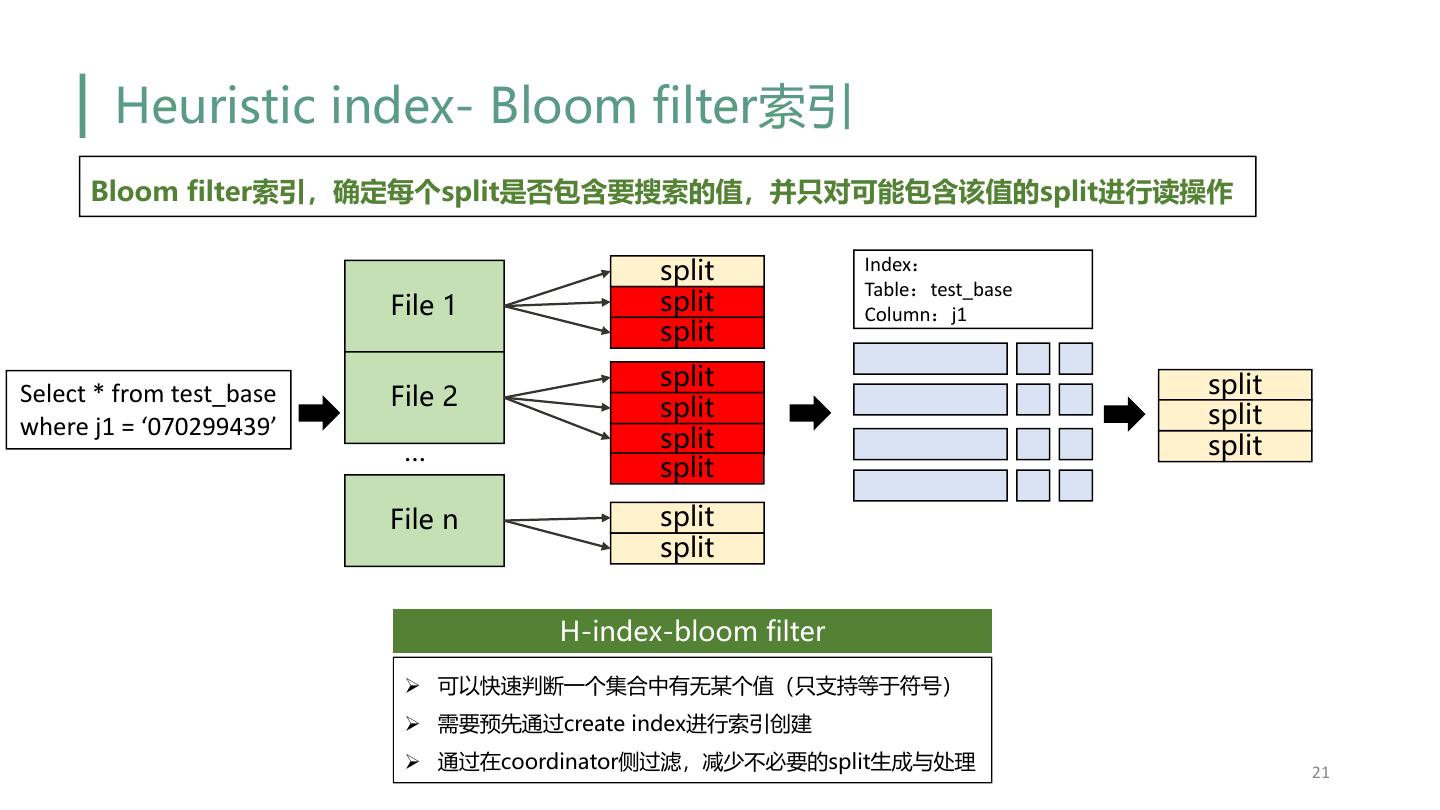
21 . Heuristic index- Bloom filter索引 Bloom filter索引,确定每个split是否包含要搜索的值,并只对可能包含该值的split进行读操作 split Index: Table:test_base File 1 split Column:j1 split split split Select * from test_base File 2 split split where j1 = ‘070299439’ split … split split File n split split H-index-bloom filter Ø 可以快速判断一个集合中有无某个值(只支持等于符号) Ø 需要预先通过create index进行索引创建 Ø 通过在coordinator侧过滤,减少不必要的split生成与处理 21
22 . Heuristic index – 位图索引 Bitmap索引,通过为谓词列保留外部位图索引,可以过滤掉与谓词不匹配的行 Stripe Batch Page Column 1 Stream Reader Index Data Column 2 Stream Reader Row Data Column 3 Stream Reader OrcPageSource Stripe Footer … … Column 8 Stream Reader 1 1 0 0 1 1 0 1 0 0 Select * from table 0 N where app_id = 123 H-index-bitmap Bitmap Ø 列式存储,记录了一列的值,字典,以及 bitmap,适用于与操作,使用字典快速查询 Ø 需要预先通过create index进行索引创建 22
23 .Heuristic index – StarTree index 点查场景 Star Tree技术:通过预聚合技术,降低高基维的查 询的延迟,达到ms级别的查询要求
24 .目录 01 openLooKeng介绍 02 交互式场景的关键技术 03 Milestone 04 总结
25 . openLooKeng 开源一周年 – 每3个月一个正式版本 openLooKeng openLooKeng 1.0.0 openLooKeng 1.1.0 openLooKeng 1.2.0 openLooKeng 1.3.0 openLooKeng 1.4.0 (开源) (已经发布) (已经发布) (已经发布) (即将发布) (规划) 2020.06 2020.09 2020.12 2021.03 2021.06 2021.09 2020年6月30日openLooKeng 0.1.0版本在社区发布,提供统一SQL接口, 具备跨源/跨域分析能力,支持交互式查询场景,同时构筑了启发式索引、动态 过滤、高可用AA、弹性伸缩、动态UDF等竞争力特性 版本 1.0.0 1.1.0 1.2.0 1.3.0 支持IUD for ORC,支持 概要 跨DC的动态过滤增强 DM优化+通用算子下推框架 资源隔离+可靠性增强 数据虚拟集市 Data Management优化、 CBO增强,支持Sorted 算子下推、动态过滤增强、 启发式索引增强、针对 高性能 基于星树索引的预聚合、CTE Source Aggregator,减少内 执行计划缓存 TPC-DS性能优化 Reuse 存使用 新增hudi connector, 北向兼容性增强 南向对接更多数据源: GreenPlum connector, 北向SQL语法转换工具支持 南向提供新的通用算子下推 南北向 openGauss、MongoDB、 clickhouse connector HQL/Impala语法 框架,更加简单、灵活和高 生态 ElasticSearch7.x、hive JDBC Connector支持多分片 南向支持10+数据源 效 metastore用户透传 查询 HBase Connector性能优化 memory connector 功能增强 高并发能力增强、对接 容器化部署、Try-me、 细粒度权限管控、查询重试 资源隔离,可靠性增强 企业级 Ranger权限管理、Admin SQL Editor 增强 (task level recovery) Dashboard
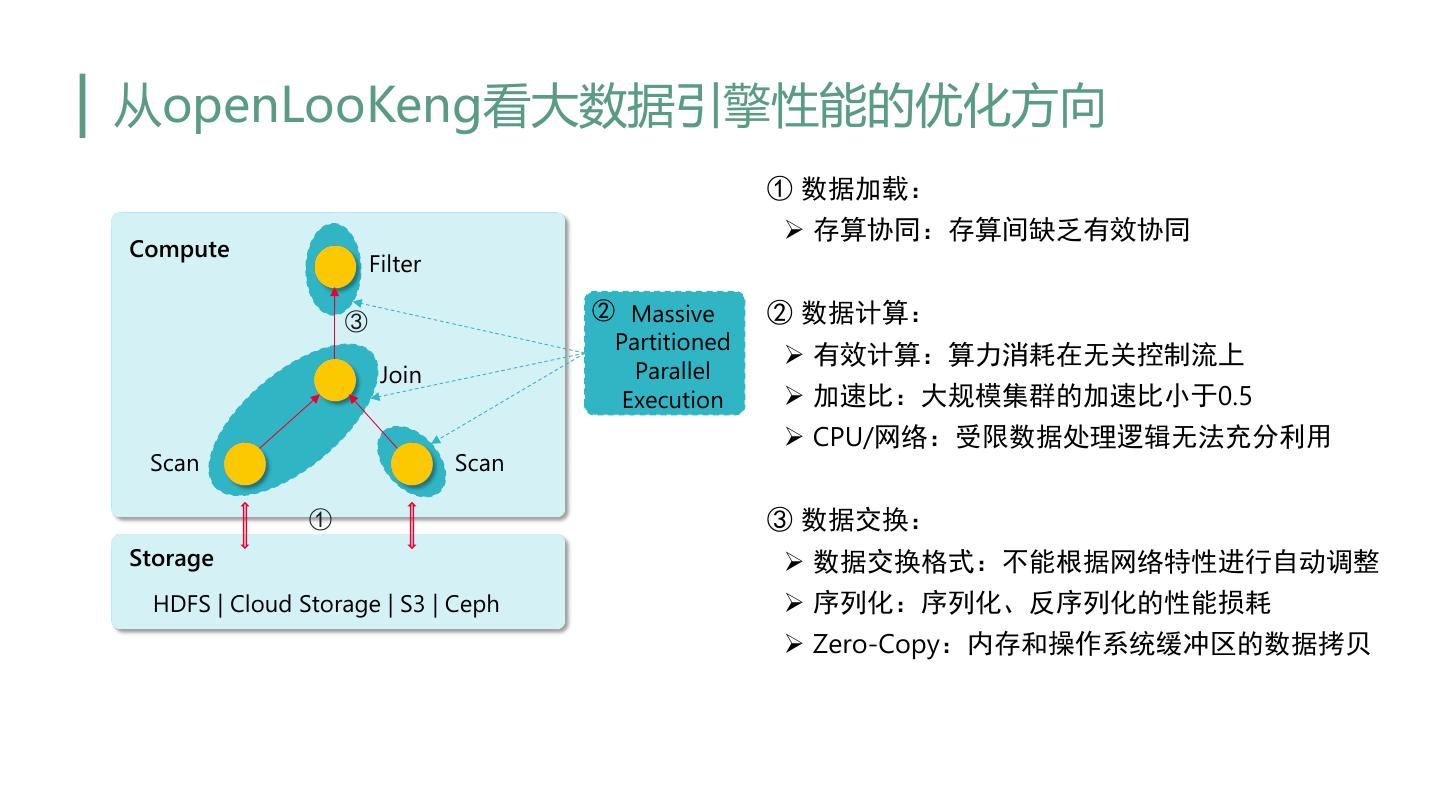
26 .从openLooKeng看大数据引擎性能的优化方向 ① 数据加载: Ø 存算协同:存算间缺乏有效协同 Compute Filter ③ ② Massive ② 数据计算: Partitioned Ø 有效计算:算力消耗在无关控制流上 Join Parallel Execution Ø 加速比:大规模集群的加速比小于0.5 Ø CPU/网络:受限数据处理逻辑无法充分利用 Scan Scan ① ③ 数据交换: Storage Ø 数据交换格式:不能根据网络特性进行自动调整 HDFS | Cloud Storage | S3 | Ceph Ø 序列化:序列化、反序列化的性能损耗 Ø Zero-Copy:内存和操作系统缓冲区的数据拷贝
27 .目录 01 openLooKeng介绍 02 交互式场景的关键技术 03 Milestone 04 总结
28 .总结 • openLooKeng愿景是让大数据更简单 • 统一SQL入口,数据免搬迁 • 高性能的交互式查询能力 • 多源异构数据源融合分析 • 跨域跨DC融合分析 • 优化技术 openLooKeng从如下三个方面进行交互式查询优化: • 让数据源更好的适配引擎(分区/小文件合并) • 引擎自身优化(动态过滤/RBO/CBO/谓词下推/缓存) • 添加额外层加速(Heuristic index layer/Cache layer/序列化/反序列化) 28
29 .Thank you
3秒后跳转登录页面
去登陆

